


前言:互联网业务为海量的互联网用户提供服务的过程中,收获了大量的业务流量,同时,程序也默默的记录着每次访问的相关信息,形成访问日志记录,而我们要如何从这海量的访问日志中提取有用的信息进行业务分析及优化呢?
在平日运营过程中,我们可能在机器上部署了nginx、squit、ATS等软件,业务访问流量经过这些软件后,会产生大量的访问日志,又或者我们的业务使用了CDN加速,可以在CDN控制台上下载到用户的大量访问日志记录,我们可以通过awk命令,快速的过滤并分析相应的访问日志信息。
网上有大量的文章说明了 awk、grep、sed等命令的使用,这篇文章中,会从日志分析的角度对awk命令进行进一步的说明,并提供常用的awk分析命令。
一、如何【看懂】awk命令?
awk命令是由模式和操作组成的:pattern {action},如 cat file | awk ‘$6>500 {test}’
两者是可选的,如果没有模式,则操作应用到全部记录,如果没有操作,则输出匹配到的全部记录,如两者兼具,则操作会应用到匹配到的所有记录中。默认情况下,输入的文件(输入源)中,每一行都是一条记录。
在本文中,我们重点介绍常用的三种模式:
- 模式匹配表达式:如:$1~”200”(第一个字段包含200); $1!~”200”(第一个字段不包含200);$1==”200”(第一个字段等于200);~与!~ 后面的表达式中,可以使用正则,如:^2.. 代表 2开头的 3位字符。
- BEGIN:在第一条输入记录被处理之前所发生的动作,通常可在这里设置变量。
- END:在所有记录被读取,操作完之后发生的动作,一般用作总结输出。
1.1 分隔符
首先,我们介绍下分隔符与$0、$1、$2、$3……的关系。
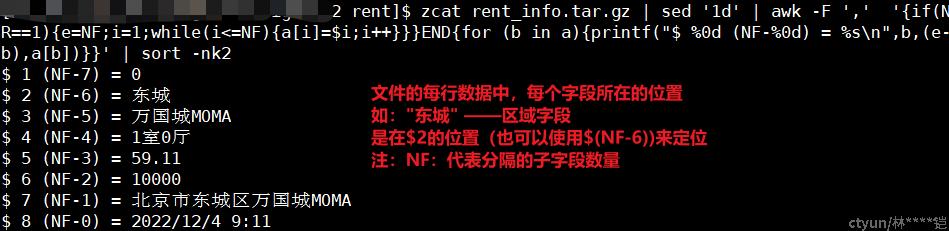
在awk命令中,我们可以使用 -F 参数,指定需要的分隔符(如果不指定,默认分隔符为空格),之后$1、$2、$3……,则分别代表被分隔符隔开的每个字段,而$0,则代表整行数据,以下面截图为参考,一个csv数据,以“,”为分隔符的话,$1,$2,$3……分别为“0”,“东城”,“万国城MOMA”……,而$0则代表整行数据(整个句子)

1.2模式匹配表达式
在了解了分隔符与$1、$2、$3……的关系后,我们就可以来说下模式匹配表达式了。在模式匹配表达式中,我们可以精确的指定需要过滤的字段。
这里以一个模拟的北京地区的租房信息做为演示,原始信息大致如下:
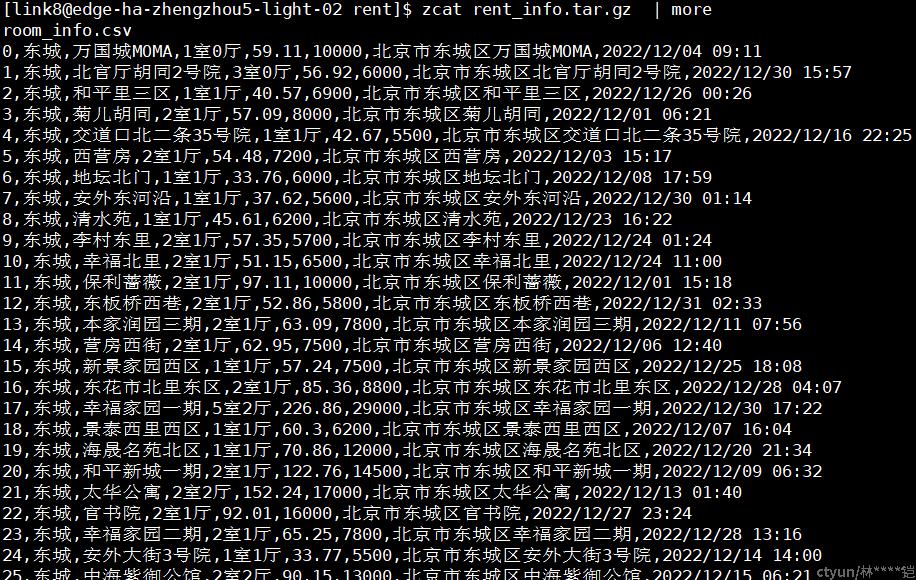
在这个数据中,我们如果要过滤展示所有“4室”的租房信息,可以使用$4~”4室”的表达式,如下图(以“,”做为分隔符,房型字段在$4,把第4个字段中包含”4室”的记录,都过滤出来)
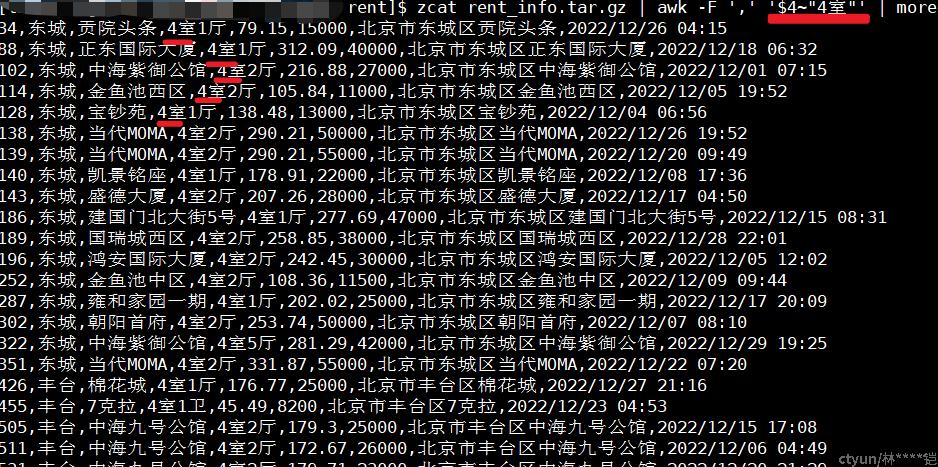
甚至,我们可以过滤更复杂的条件,如:丰台区5室的房子,或者大兴区租房面积大于200的房子(&&:表示条件“与”,||:表示条件“或”),那条过滤条件为:
awk -F ',' '($2~"丰台"&&$4~"5室") || ($2~"大兴"&&$5>200)'注:以下内容为了方便直观展示,我在命令后增加 【column -s , -t 】 命令,将内容以”,”进行分列对齐展示
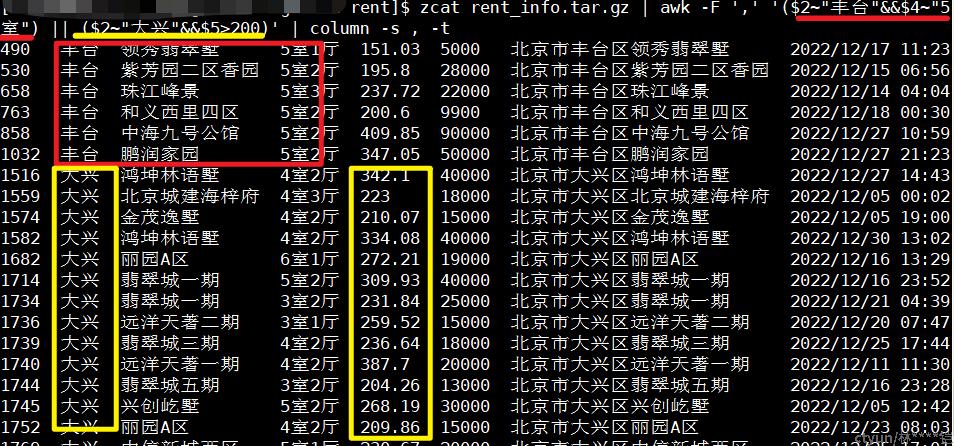
模式匹配表达式,还可以使用 !~ (不包含)、==(等于)、>(大于)、 <(小于)等匹配条件(其实大于、小于属于条件匹配表达式,但我们在这里就一并考虑使用了~)
1.3、BEGIN,END表达式与{操作}
在说完模式匹配表达式后,我们再来说说awk常用的三段落BEGIN{}{}END{},其中BEGIN{}段落是在所有数据操作前执行的,一般用于全局变量赋值;中间的{},则是针对每行数据都需要做的一些操作;而END{},则是在所有行数据都操作完成后,再最后进行的操作,一般用于总结性的结果输出。
那么,说完这些,来看看这段命令,大家能看得清是啥作用吗?
zcat rent_info.tar.gz | awk -F ',' 'BEGIN{ave2_sum=0; ave3_sum=0;ave2_count=0; ave3_count=0 }{if($2~"东城" && $4~"2室"){ave2=$6/$5;ave2_sum+=ave2;ave2_count++}else if($2~"东城" && $4~"3室"){ave3=$6/$5;ave3_sum+=ave3;ave3_count++}}END{print("东城区域:2室数量:",ave2_count,";均价:",ave2_sum/ave2_count,"\n东城区域:3室数量:",ave3_count,";均价:",ave3_sum/ave3_count)}'

看完是这个表情吗?^_^
是的,复杂的awk命令的确写完是这样的(还有更复杂的。。。),但也的确不方便观看,我刚进入CDN行业的时候,看到这样的awk命令也是好一阵无语-_-!!,如果大家是新接触awk,或者接触时间不长,肯定是无法看出这串命令具体要做什么,那我们要怎么办呢?
其实,在最初开始学习或编写awk命令时,我们不要着急于“一气呵成”,可以按一些简单的代码格式,把awk命令分行编写,就能比较清晰了,例如,上面的复杂命令,我们可以改写成如下:
zcat rent_info.tar.gz | awk -F ',' ' # 这里留下一个【单引号】很重要哦~
BEGIN{
ave2_sum=0;
ave3_sum=0;
ave2_count=0;
ave3_count=0
}
{
if($2~"东城" && $4~"2室")
{
ave2=$6/$5;
ave2_sum+=ave2;
ave2_count++
}
else if($2~"东城" && $4~"3室")
{
ave3=$6/$5;
ave3_sum+=ave3;
ave3_count++
}
}
END{
print("东城区域:2室数量:",ave2_count,";均价:",ave2_sum/ave2_count,
"\n东城区域:3室数量:",ave3_count,";均价:",ave3_sum/ave3_count)
}
'以下是逐块内容解释及命令最终输出内容:重点哦~!!!
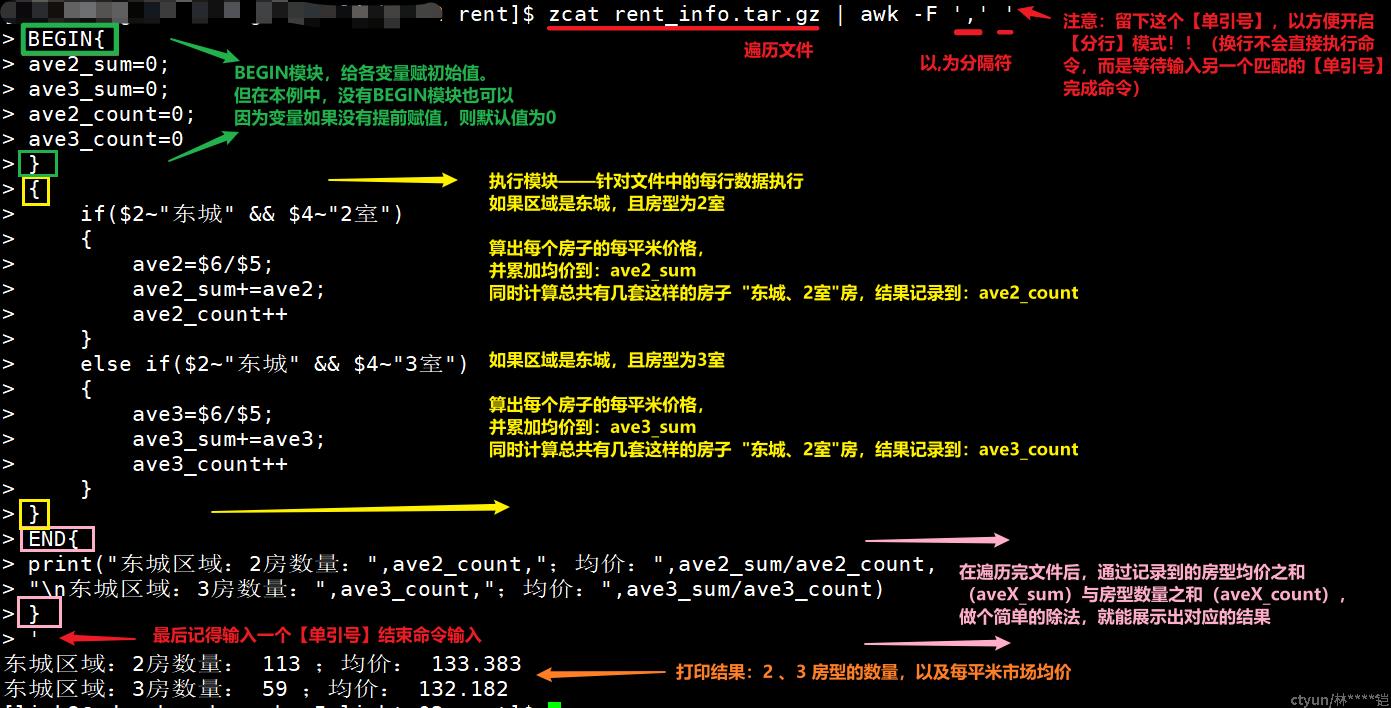
这样大家是不是就比较能看清【复杂】的awk命令了呢?其实也是很简单的逻辑呢(只是原本挤在一行,不方便阅读)
二、awk常用命令
在我们看懂awk命令后,其实就可以开始自主编写一些个性化需求的命令了(简单的判断、循环等逻辑网上介绍的比较多,我在这里就不再赘述了),本文提供一些常用的awk命令以及使用场景,我在这里也分别演示下(还是以上面的租房信息文件作为演示),大家可以收藏这些常用命令,后续此基础上再进行进一步的改编~
2.1查看字段位置
命令:
awk -F ',' '{if(NR==1){e=NF;i=1;while(i<=NF){a[i]=$i;i++}}}END{for (b in a){printf("$ %0d (NF-%0d) = %s\n",b,(e-b),a[b])}}' | sort -nk2作用/场景:按指定的分隔符,查看字段所在的位置,$X
示例:
2.2 查看某列数据的占比
命令:
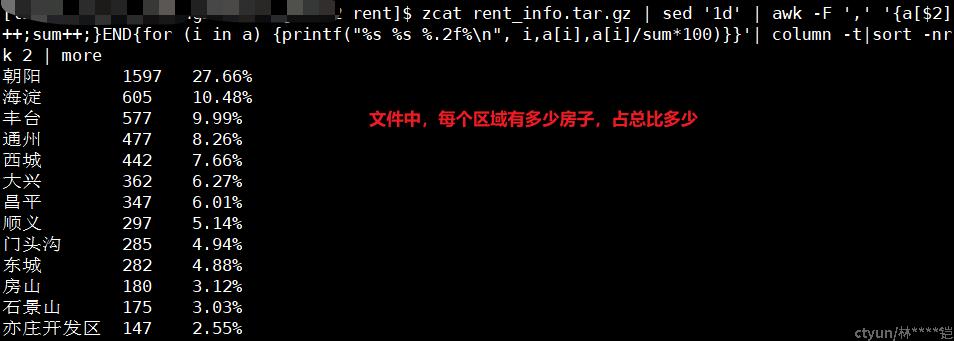
awk -F ',' '{a[$2]++;sum++;}END{for (i in a) {printf('%s %s %.2f%\n', i,a[i],a[i]/sum*100)}}'| column -t|sort -nrk 2 | more作用:查看某列字段的占比
使用场景:在访问日志统计场景中,可以通过这个命令来过滤访问状态码、访问域名、用户IP等数据的占比情况
示例:
2.3 查看某列数据的平均值
命令:
awk -F ',' '{sum+=$5;count++;}END{printf("总价:%s 总数:%s 平均价:%.2f\n", sum,count,sum/count*100)}'| column-t|sort -nrk 2 | more作用:查看某列数据的平均值
使用场景:在访问日志统计场景中,可以通过这个命令算出访问文件平均大小,平均响应时间,平均下载速率等
示例:

2.4 每5分钟数据统计
命令:
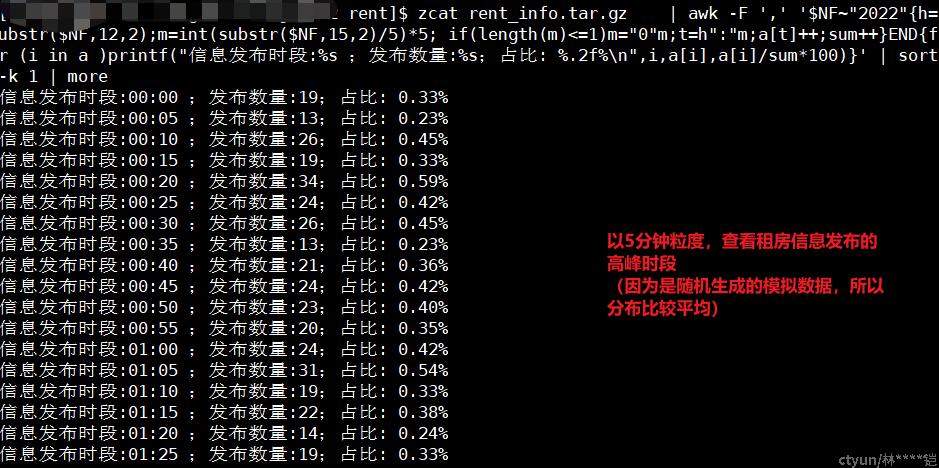
awk -F ',' '$NF~"2022"{h=substr($NF,12,2);m=int(substr($NF,15,2)/5)*5; if(length(m)<=1)m="0"m;t=h":"m;a[t]++;sum++}END{for (i in a )printf("信息发布时段:%s ;发布数量:%s;占比: %.2f%\n",i,a[i],a[i]/sum*100)}'| sort -k 1| more作用:按每5分钟的粒度,进行数据统计,上面命令中“h=……t=h":"m;”这一截是重点哦~(不能单独输出,被网站判定为敏感字。。。)
场景:在访问日志统计场景中,可以按每5分钟粒度(也可以自行调整到其余时间粒度),统计业务在每个5分钟时段内的的业务流量、请求数、状态码数量等等
注:substr(“str”,index,step):该方法代表,截取str字符串中,第index开始的 step 长度的字符串。在本例中,h=substr($NF,12,2)代表截取了最后一段的时间信息中的小时信息,并存储到变量h中;m=int(substr($NF,15,2)/5)*5,代表截取了分钟信息,同时做了一些整数处理,0~4分钟的数据记录为00分,5~9分钟的数据记录为05分,最后,使用t=h”:”m,将小时与分钟数据记录到变量t中(t=”hh:mm”)
示例:
2.5 按指定区间统计数据
命令:
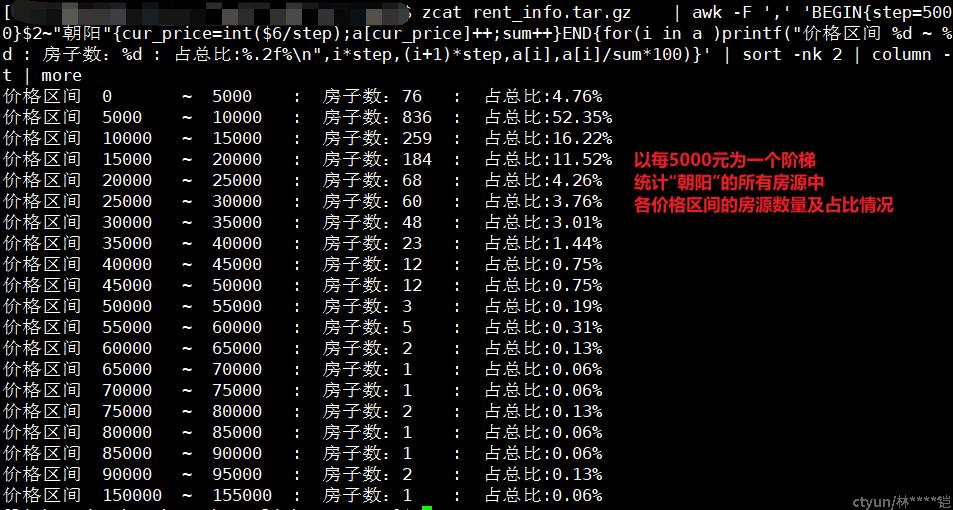
awk -F ',' 'BEGIN{step=5000}$2~"朝阳"{cur_price=int($6/step);a[cur_price]++;sum++}END{for(i in a )printf("price区间 %d ~ %d : 房子数:%d : 占总比:%.2f%\n",i*step,(i+1)*step,a[i],a[i]/sum*100)}' | sort -nk 2 | column -t | more作用:按指定区间统计数据
场景:在访问日志统计场景中,可以按指定区间统计文件大小的情况;文件下载速率情况;响应时间情况等等
示例:
结语:本文结合我个人的日常使用awk命令的一些经验,描述了我在新入行的小白阶段是如何看懂awk命令的,并提供了在之后的日常运营工作中,经常会用到的一些awk命令,希望对各位看官也有所帮助~~
t
