Spark如何将数据写入到DLI表中
使用Spark将数据写入到DLI表中,主要设置如下参数:
- fs.obs.access.key
- fs.obs.secret.key
- fs.obs.impl
- fs.obs.endpoint
示例如下:
import logging
from operator import add
from pyspark import SparkContext
logging.basicConfig(format='%(message)s', level=logging.INFO)
#import local file
test_file_name = "D://test-data_1.txt"
out_file_name = "D://test-data_result_1"
sc = SparkContext("local","wordcount app")
sc._jsc.hadoopConfiguration().set("fs.obs.access.key", "myak")
sc._jsc.hadoopConfiguration().set("fs.obs.secret.key", "mysk")
sc._jsc.hadoopConfiguration().set("fs.obs.impl", "org.apache.hadoop.fs.obs.OBSFileSystem")
sc._jsc.hadoopConfiguration().set("fs.obs.endpoint", "myendpoint")
# red: text_file rdd object
text_file = sc.textFile(test_file_name)
# counts
counts = text_file.flatMap(lambda line: line.split(" ")).map(lambda word: (word, 1)).reduceByKey(lambda a, b: a + b)
# write
counts.saveAsTextFile(out_file_name)
通用队列操作OBS表如何设置AK/SK
- 获取结果为AK和SK时,设置如下:
- 代码创建SparkContext
val sc: SparkContext = new SparkContext() sc.hadoopConfiguration.set("fs.obs.access.key", ak) sc.hadoopConfiguration.set("fs.obs.secret.key", sk) - 代码创建SparkSession
val sparkSession: SparkSession = SparkSession .builder() .config("spark.hadoop.fs.obs.access.key", ak) .config("spark.hadoop.fs.obs.secret.key", sk) .enableHiveSupport() .getOrCreate()
- 获取结果为ak、sk和securitytoken时,鉴权时,临时AK/SK和securitytoken必须同时使用,设置如下:
- 代码创建SparkContext
val sc: SparkContext = new SparkContext() sc.hadoopConfiguration.set("fs.obs.access.key", ak) sc.hadoopConfiguration.set("fs.obs.secret.key", sk) sc.hadoopConfiguration.set("fs.obs.session.token", sts) - 代码创建SparkSession
val sparkSession: SparkSession = SparkSession .builder() .config("spark.hadoop.fs.obs.access.key", ak) .config("spark.hadoop.fs.obs.secret.key", sk) .config("spark.hadoop.fs.obs.session.token", sts) .enableHiveSupport() .getOrCreate()
说明出于安全考虑,不建议在obs路径上带AK/SK信息。而且,如果是在OBS目录上建表,建表语句path字段给定的obs路径不能包含AK/SK信息。
如何查看DLI Spark作业的实际资源使用情况
查看Spark作业原始资源配置
登录DLI 控制台,单击左侧“作业管理”>“Spark作业”,在作业列表中找到需要查看的Spark作业,单击“作业ID”前的,即可查看对应Spark作业的原始资源配置参数。
说明在创建Spark作业时,配置了“高级配置”中的参数,此处才会显示对应的内容。
查看Spark作业实时运行资源
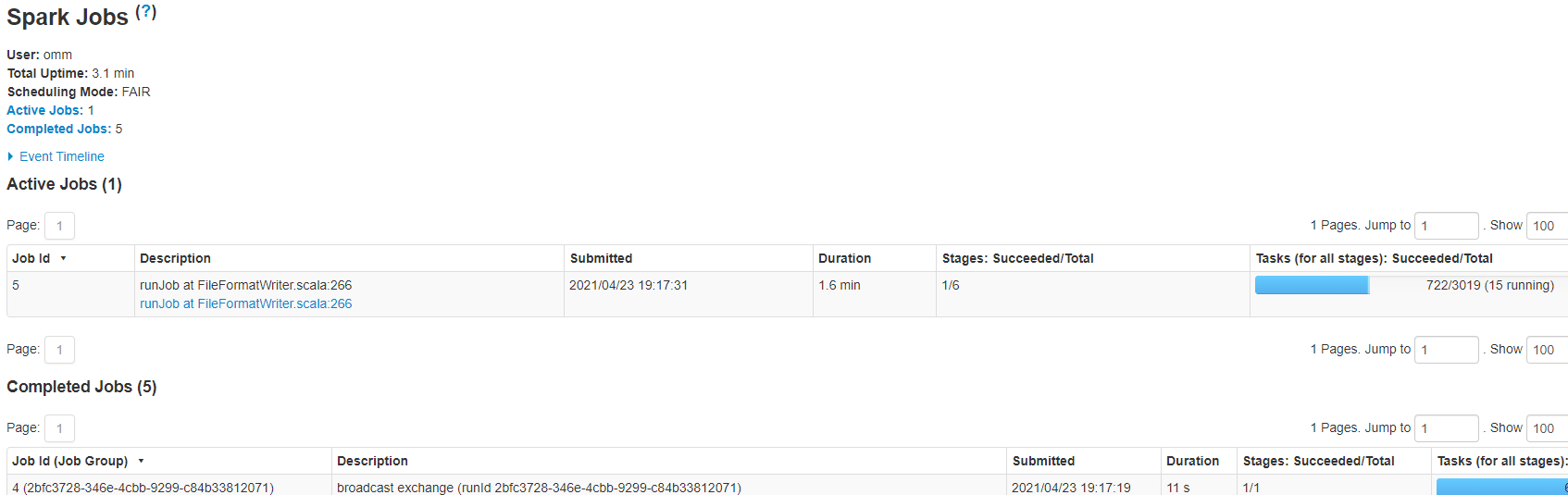
查看Spark作业实时运行资源,即查看有多少CU正在运行。
-
登录DLI 控制台,单击左侧“作业管理”>“Spark作业”,在作业列表中找到需要查看的Spark作业,单击“操作”列中的“SparkUI”。
-
在SparkUI页面可查看Spark作业实时运行资源。
-
在SparkUI页面还可以查看Spark作业原始资源配置(只对新集群开放)。
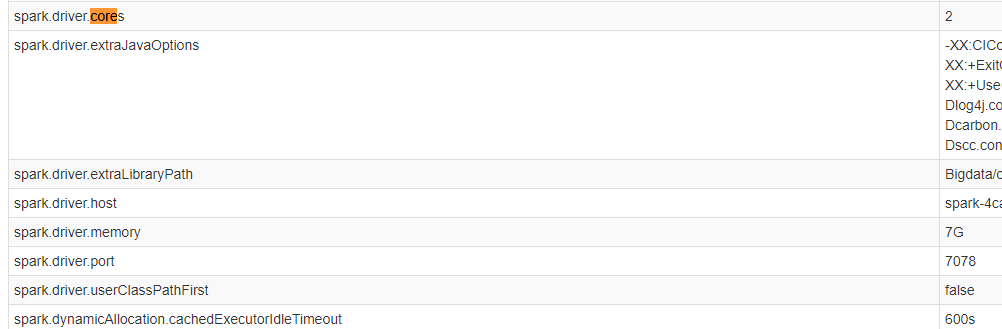
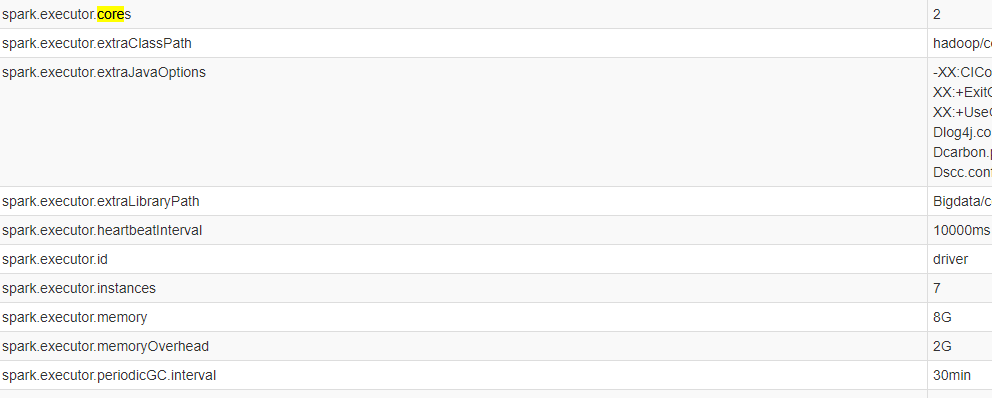
在SparkUI页面,单击“Environment”,可以查看Driver信息和Executor信息。
详见下图:Driver信息
详见下图:Executor信息
将Spark作业结果存储在MySQL数据库中,缺少pymysql模块,如何使用python脚本访问MySQL数据库?
1.缺少pymysql模块,可以查看是否有对应的egg包,如果没有,在“程序包管理”页面上传pyFile。具体步骤参考如下:
a.将egg包上传到指定的OBS桶路径下。
b.登录DLI管理控制台,单击“数据管理 > 程序包管理”。
c.在“程序包管理”页面,单击右上角“创建”可创建程序包。
d.在“创建程序包”对话框,配置如下参数:
- 包类型:PyFile。
- OBS路径:选择1.aegg包所在的OBS路径。
- 分组设置和分组名称根据情况选择。
e.单击“确定”完成程序包上传。
f.在报错的Spark作业编辑页面,“依赖python文件”处选择已上传的egg程序包,重新运行Spark作业。
2.pyspark作业对接MySQL,需要创建跨源链接,打通DLI和RDS之间的网络。
如何在DLI中运行复杂PySpark程序?
数据湖探索(DLI)服务对于PySpark是原生支持的。
对于数据分析来说Python是很自然的选择,而在大数据分析中PySpark无疑是不二选择。对于JVM语言系的程序,通常会把程序打成Jar包并依赖其他一些第三方的Jar,同样的Python程序也有依赖一些第三方库,尤其是基于PySpark的融合机器学习相关的大数据分析程序。传统上,通常是直接基于pip把Python库安装到执行机器上,对于DLI这样的Serverless化服务用户无需也感知不到底层的计算资源,那如何来保证用户可以完美运行他的程序呢?
DLI服务在其计算资源中已经内置了一些常用的机器学习的算法库,这些常用算法库满足了大部分用户的使用场景。对于用户的PySpark程序依赖了内置算法库未提供的程序库该如何呢?其实PySpark本身就已经考虑到这一点了,那就是基于PyFiles来指定依赖,在DLI Spark作业页面中可以直接选取存放在OBS上的Python第三方程序库(支持zip、egg等)。
对于依赖的这个Python第三方库的压缩包有一定的结构要求,例如,PySpark程序依赖了模块moduleA(import moduleA),那么其压缩包要求满足如下结构:
压缩包结构要求

即在压缩包内有一层以模块名命名的文件夹,然后才是对应类的Python文件,通常下载下来的Python库可能不满足这个要求,因此需要重新压缩。同时对压缩包的名称没有要求,所以建议可以把多个模块的包都压缩到一个压缩包里。至此,已经可以完整的运行起来一个大型、复杂的PySpark程序了。
Spark作业访问MySQL数据库的方案
通过DLI Spark作业访问MySQL数据库中的数据有如下两种方案:
- 方案1:在DLI中购买按需专属队列,创建增强型跨源连接,再通过跨源表读取MySQL数据库中的数据,该方案需要用户自行编写java代码或scala代码。
- 方案2:先使用云数据迁移服务CDM将MySQL数据库中的数据导入OBS桶中,再通过Spark作业读取OBS桶中的数据,如果用户已有CDM集群,该方案比方案1简单,且不会对现有数据库造成压力。
如何通过JDBC设置spark.sql.shuffle.partitions参数提高并行度
操作场景
Spark作业在执行shuffle类语句,包括group by、join等场景时,常常会出现数据倾斜的问题,导致作业任务执行缓慢。
该问题可以通过设置spark.sql.shuffle.partitions提高shuffle read task的并行度来进行解决。
设置spark.sql.shuffle.partitions参数提高并行度
用户可在JDBC中通过set方式设置dli.sql.shuffle.partitions参数。具体方法如下:
Statement st = conn.stamte()
st.execute("set spark.sql.shuffle.partitions=20")
Spark jar 如何读取上传文件
Spark可以使用SparkFiles读取 –-file中提交上来的文件的本地路径,即:SparkFiles.get("上传的文件名")。
说明lDriver中的文件路径与Executor中获取的路径位置是不一致的,所以不能将Driver中获取到的路径作为参数传给Executor去执行。
lExecutor获取文件路径的时候,仍然需要使用SparkFiles.get(“filename”)的方式获取。
lSparkFiles.get()方法需要spark初始化以后才能调用。
代码段如下所示
package main.java
import org.apache.spark.SparkFiles
import org.apache.spark.sql.SparkSession
import scala.io.Source
object DliTest {
def main(args:Array[String]): Unit = {
val spark = SparkSession.builder
.appName("SparkTest")
.getOrCreate()
// driver 获取上传文件
println(SparkFiles.get("test"))
spark.sparkContext.parallelize(Array(1,2,3,4))
// Executor 获取上传文件
.map(_ => println(SparkFiles.get("test")))
.map(_ => println(Source.fromFile(SparkFiles.get("test")).mkString)).collect()
}
}

