


写在前面
本文隶属于专栏《100个问题搞定大数据理论体系》,该专栏为笔者原创,引用请注明来源,不足和错误之处请在评论区帮忙指出,谢谢!
本专栏目录结构和文献引用请见100个问题搞定大数据理论体系
解答
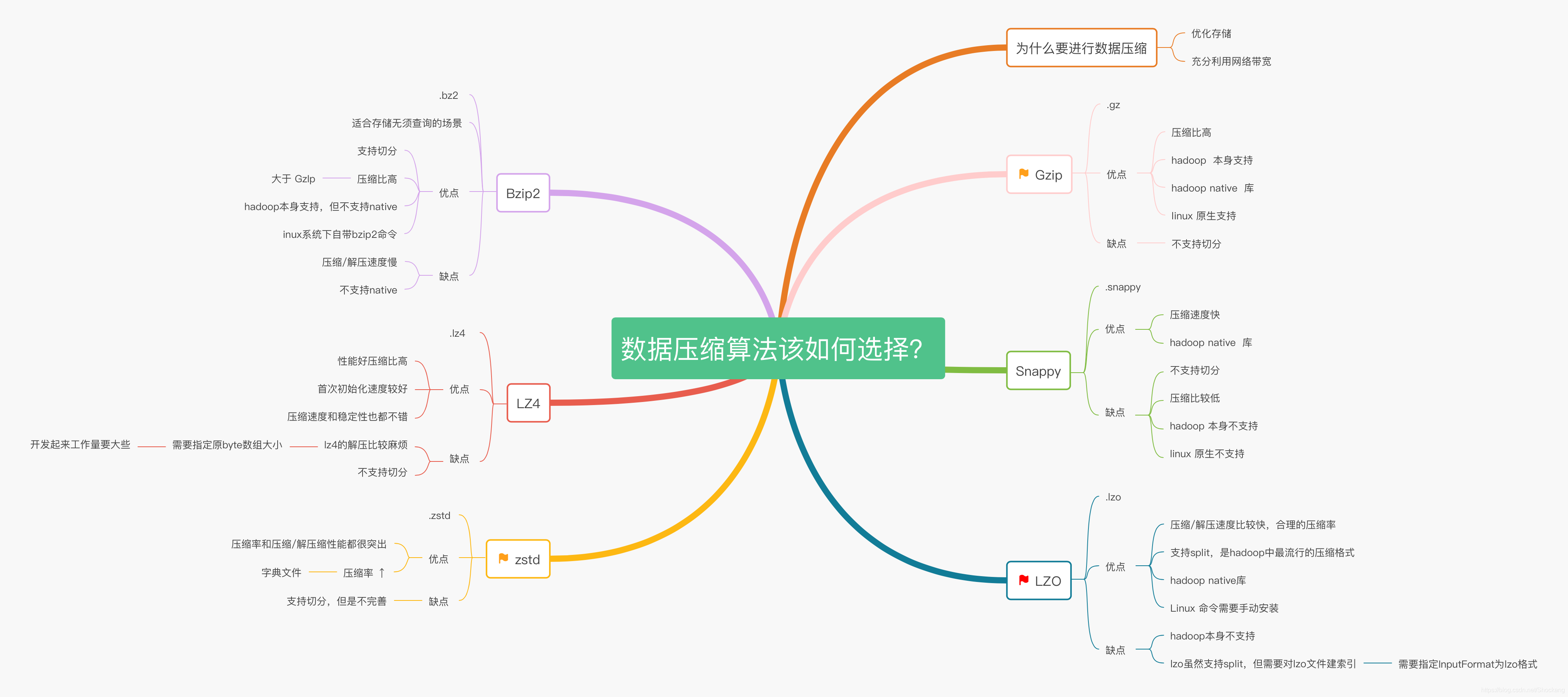
大数据领域常见的压缩格式有 gzip,snappy,lzo,lz4,bzip2,zstd。
补充
为什么要进行数据压缩?
为了优化存储(减少存储空间)和充分利用网络带宽,通常采用压缩方法。大数据需要处理海量数据,此时数据压缩非常重要。
在企业中存在的许多场景中,通常,数据源来自多种文本格式(CSV、TSV、XML、JSON等)数据。这些文件是人类可读的,但占用了大量的存储空间。
然而在大数据处理中数据应尽可能为机器可读。使用序列化的压缩技术将这些人类可读的数据压缩成机器可读的, 可确保存储所需的空间大大减少。
以下是一些众所周知的常用压缩格式(称为编解码器,允许数据压缩/序列化和解压缩/反序列化)
Gzip(扩展名为.gz)
即 GNU Zip(GZip),一种众所周知的压缩格式,并且在互联网世界中被广泛使用。可以使用此格式压缩请求和响应,以有效利用网站/Web应用程序的带宽。
优点
压缩比较高,hadoop本身支持,在应用中处理gzip格式的文件就和直接处理文本一样,有hadoop native库,大部分linux系统都自带gzip命令,使用方便。
缺点
不支持split
hadoop native 是什么?
鉴于性能问题以及某些Java类库的缺失,对于某些组件,Hadoop提供了自己的本地实现。 这些组件保存在Hadoop的一个独立的动态链接的库里。这个库在Unix平台上叫libhadoop.so.
Snappy(扩展名为.snappy)
由 Google开发的编解码器(以前称作Zippy),被认为是中等压缩比中性能最好的。对于该格式而言,性能比压缩比更为重要。Snappy属于最为广泛使用的格式之一,显然是由于其出色的性能。
优点
压缩速度快;支持hadoop native库
缺点
不支持split;压缩比低;hadoop本身不支持,需要安装;linux系统下没有对应的命令
LZO(扩展名为.lzo)
由GNU公共许可证(GPL)授权,与 Snappy非常类似,它具有中等压缩比,而压缩与解压缩性能很高。LZO是一种专注于解压缩速度的无损数据压缩算法。
优点
压缩/解压速度也比较快,合理的压缩率;支持split,是hadoop中最流行的压缩格式;支持hadoop native库;需要在linux系统下自行安装lzop命令,使用方便
缺点
hadoop本身不支持,需要安装;lzo虽然支持split,但需要对lzo文件建索引,否则hadoop也是会把lzo文件看成一个普通文件(为了支持split需要建索引,需要指定InputFormat为lzo格式)。
LZ4(扩展名.lz4)
优点
性能好压缩比高,首次初始化速度较好,压缩速度和稳定性也都不错
缺点
lz4的解压比较麻烦,需要指定原byte数组大小,所以开发起来工作量要大些
不支持split
Bzip2(扩展名.bz2)
或多或少与GZip类似,压缩比高于GZip。但如预期一样, Bzip2的数据解压缩速度比GZip慢。其中一个重要的方面是,它支持数据分割,这在使用HDFS作为存储时非常重要。如果数据只是被存储而无须查询,那么这种压缩将是一个不错的选择。
优点:
支持split;具有很高的压缩率,比gzip压缩率都高;hadoop本身支持,但不支持native;在linux系统下自带bzip2命令,使用方便
缺点:
压缩/解压速度慢;不支持native
zstd(扩展名.zstd)
zstd是Facebook在2016年开源的新无损压缩算法,优点是压缩率和压缩/解压缩性能都很突出。zstd还有一个特别的功能,支持以训练方式生成字典文件,相比传统压缩方式能大大的提高小数据包的压缩率。
对大数据量的文本压缩场景,zstd是综合考虑压缩率和压缩性能最优的选择,其次是lz4。
对小数据量的压缩场景,如果能使用zstd的字典方式,压缩效果更为突出。
支持split, 但是还不完善,详情可见——Is zstd splitabble in hadoop/spark/etc?
选择
前面的每种压缩算法都有其优点和缺点。如果压缩比比较高(压缩后节约较大空间)则解压缩速度通常很慢,反之,则解压缩速度快。
没有两全其美的办法,只能选择一种方法来使用。这取决于进入系统的数据,必须根据具体情况来选择。
当需要选择压缩算法时,以下选项可供参考
将文件分成若干块,然后使用适合的算法进行压缩。由于选择了 Hadoop(HDFS)作为数据持久化机制,因此需要确保这些数据块在压缩后能与预期的memory slot适配(在HDFS中配置)。
选择允许先分割、再压缩的压缩格式。
选择允许分割和压缩的容器文件格式,如Avro和Parquet。这些格式可以与其他压缩格式混合使用,以达到用户用例所要求的速度和压缩比。
————————————————
版权声明:本文为CSDN博主「Shockang」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/Shockang/article/details/116424217
