1.层次化存储结构
又叫分级存储体系,主要是为了解决解决存储的容量、价格和速度之间的矛盾
注意:不是为了解决存储器读写可靠性,读写可靠性都是通过增加冗余结构来增加的
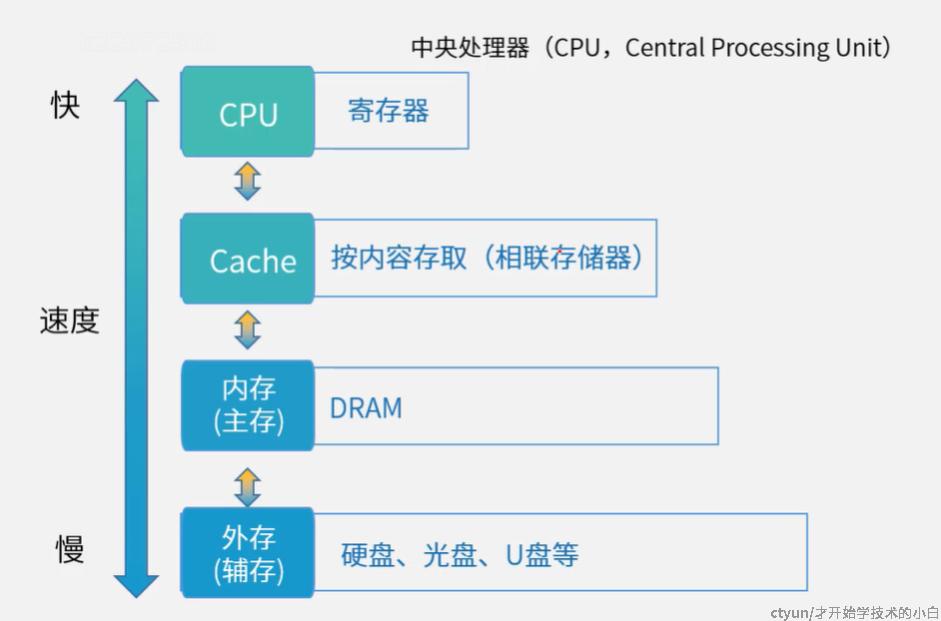
寄存机的存储结构是越靠近内部越快成本越高,cpu的缓存(寄存器)就是最快的,但通常只有64位,即我们常说的64位系统;
外存:比如硬盘,解决了主存容量不足的问题
内存,我们比较熟悉的内存条(DRAM,掉电数据丢失,动态随机存储,即会定时刷新的随机存储设备,rom掉电就不会丢失通常用到BIOS等比较重要的地方)
外存+内存:又叫做虚拟存储体系,其调用过程由os来控制
cache+外存+内存:又叫三级存储结构,他们可以通过程序操作(cache需要用汇编操作,但程序员是看不到cache的)
cache又叫缓存/高速缓存,基本在MB的级别,用的是相联存储器(按内容存取,通过页面的编号去查找存储位置,即内容与位置相关)
eg:我下载一个60g的游戏,存在外存(硬盘)里,如果我运行这个游戏,那么内存就会从外存里读取游戏数据(当然不会加载整个60g的游戏,是需要用什么就调用什么,这与程序的局部性原理相关),cache再从内存里调,cpu再从cache里掉
2.Cache(高速缓存)
是cpu与主存之间的告诉缓存,解决cpu与主存之间速度容量不匹配的问题(即冯诺依曼瓶颈),是计算机存储体系中除cpu寄存器外速度最快的层次,其设计思想为:在合理的成本下提高命中率h
cache具有透明性,其地址和映射关系由硬件直接完成,与程序员无关
为什么cache可以改善系统性能?——程序的局部性原理(时间局部性+空间局部性)
- 时间局部性:某条程序可能短时间要执行多次,比如程序中的多层循环操作
- 空间局部性:访问了某个存储单元,可能它附件的很多单元马上也要被访问(即一段时间内需要访问的地址都靠的很近),比如访问一个上千个元素的数组,并遍历它(即程序的顺序执行)
如果没有cache,这类代码cpu就需要频繁的从主存里读取,非常浪费时间
还有一个重要概念:
工作集理论——工作集是进程(运行的程序就叫进程)运行时被频繁访问的存储页面集合
cache的访问速度t3由h/t1/t2决定,他们分别是:
- h:cache访问命中率(1-h为失效率),比如cpu需要访问100个内容,其中10个可以从cache访问到,h就为0.1;h与cache替换算法有关,典型值为0.92
- t1:cache的周期时间,即从cache中获得数据的典型时间
- t2:主存的周期时间
- t3:cache+主存的周期时间(本质就是个加权平均值),t3 = h×t1 + (1-h)×t2
3.主存编址计算
在计算机中所有的数据,他们的本质就是以bit(也叫位)为单位的二进制(或者说机器语言),为了方便存储,计算机都会把一定位数的bit作为一个存储单元(即字长),比如说某计算机把4个bit作为一个字长,那么他的主存就被分成了许许多多个4bit字长的存储单元,每个存储单元有自己的地址编号,计算机就是根据这个地址编号来快速定位去哪里找数据(这个地方存的数据就叫做编址内容)。比如下图,是一个容量32位的8*4的存储器(即有8个存储单元,每个单元有4位),总容量 = 存储单元个数 × 编址内容容量
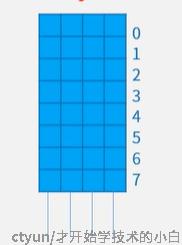 ——>虽然这里的地址编号是用十进制表示的,但实际在计算机里也是用二进制存的
——>虽然这里的地址编号是用十进制表示的,但实际在计算机里也是用二进制存的
回到我们的主存,本质上就是这样许许多多的小存储器(实际上是一些小存储芯片)拼接起来的(可以横着拼成8*8,也可以竖着拼成16*4),横着拼比较常见,因为8位为一字节(byte),比较常用
刚刚说的都是很简单的理想情况,那么现实中的计算机是怎么编址的呢?
- 按字编址:存储单元为字存储单元(即一个存储单元里面放一个字,这个字有多长不同的电脑不一样,刚刚的例子是4位,现在的计算机一般是64位,就是所谓的64位计算机),即最小寻址单位就是一个字,每个字我给他一个地址
- 按字节编址:存储单元为字节存储单元,即最小寻址单位就是一个字节,即每个字节我给他分配一个地址,所有的计算机里字节都是8位
eg:如果要按字节编址,有一种小型的存储芯片,它的规模是8K×4bit(注意在计算机里K=2^10,M=2^20,G=2^30,千万别用10^3这种来近似),如果要用它构成的地址范围为84000H-8FFFFH(H代表16进制hexadecimal)的内存,需要多少片?
- 先算一个芯片有多大的内存:有8K个存储单元,每个单元4bit,那就是一共有2^12个字节(即4K)的容量
- 再算需要多少内存:4000-FFFF一共有多少?其实很简单就是16-4个FFF,即12×2^12
- 除一下就完事了,需要12片,而且由于是按字节编址,需要6*2这样拼起来
4.磁盘管理-磁盘基本结构与存取过程
磁盘的基本结构如下图:
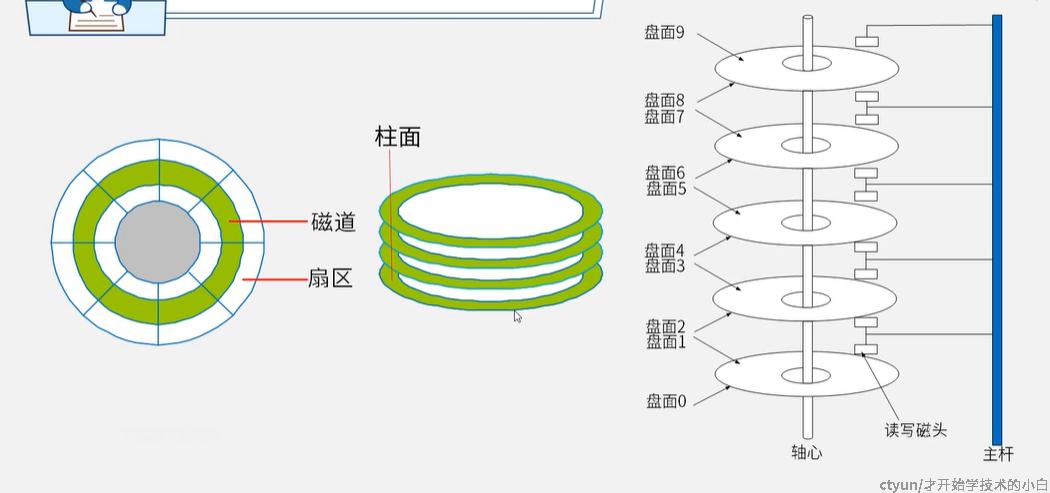
可以看到磁盘是一个立体的结构形态,是多个盘面堆叠而成的,且每个盘面都配备一个读写的磁头,这些磁头通过硬件连接在一个主杆上面;
所有的盘面都是固定围绕轴心来进行匀速且同向的运动的,而具体到某一盘面,他是多个同心圆组成的,每个同心圆都是一个磁道,如果把这些磁道按角度来切割,每个切割出来的内容就叫做扇区
在实际读取的过程中,我们都是通过扇区来读取数据的;磁道可以有自己的编号,一般从外往内是从0到n(扇区也有编号但不这样编,一般是R);磁头的编号通常是盘面的编号
所有盘面的同一号磁道可以组成一个圆柱,称为柱面;由于所有的磁头都在同一个主杆上(都是一起动的),因此磁头查找磁道的过程本质上就是查找柱面的过程
总而言之:从磁盘读取信息的本质,就是磁头在磁道上运动的过程
当然磁头的运动可以分为两个方向,或者说读取信息可以分为两个步骤:
- 垂直寻道:磁头向圆心移动,跨越不同的磁道,直到找到我们需要的磁道(所谓的移臂调度)(寻道时间)
- 读取扇区数据:找到对应磁道之后,等磁盘匀速转动,直到我们所需要的扇区转到磁头的下方,这个是计算机硬件的特性,没有规律(旋转延迟/等待时间)
(平均)数据存取时间 = (平均)寻道时间 + (平均)等待时间
注意:平均存取时间(Average Access Time)是磁头找到指定数据的平均时间,不包含数据传输的时间(而且这个时间通常很小,可以忽略不记)
5.磁盘管理-磁盘优化分布存储
扇区又可以叫做物理块,通常用Rn来表示,如果是顺序存放,那将会是这样的:
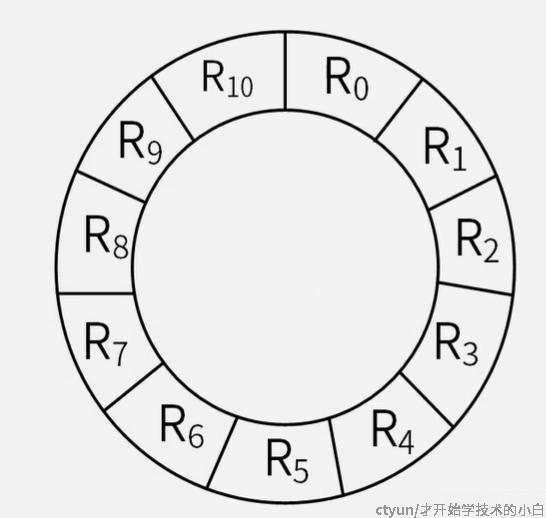
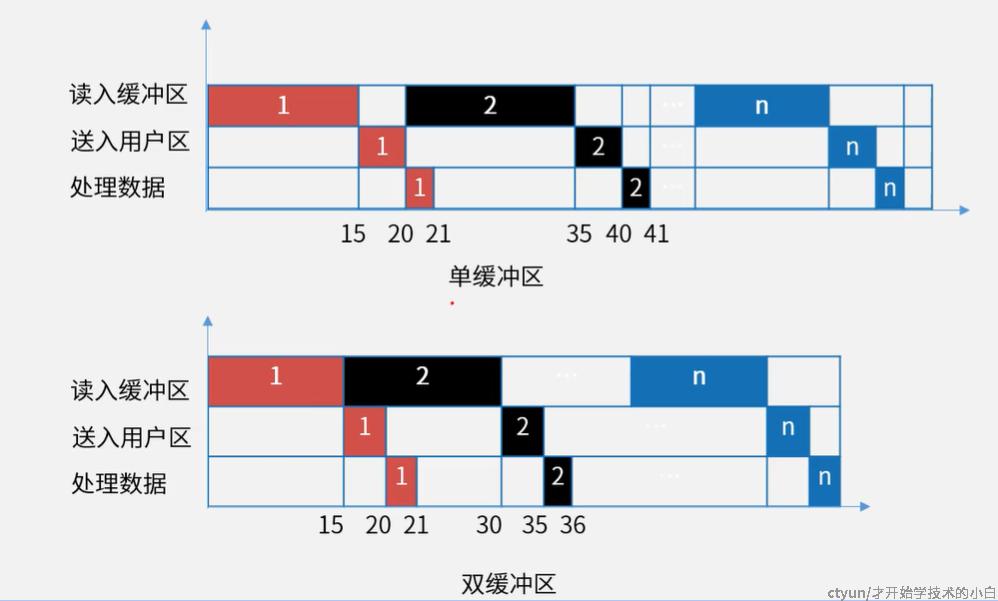
比如要读取R0,磁头划过R0之后,读取的数据会被存在一个单缓冲区(只能存一个,必须要把数据传出去才能读下一个),单缓冲区的数据传输出去是需要时间的,如果这个时候你需要继续读R1的数据,必须等磁头绕一圈之后才行(因为这个时候R0的数据已经处理完了,单缓冲区可以用了)
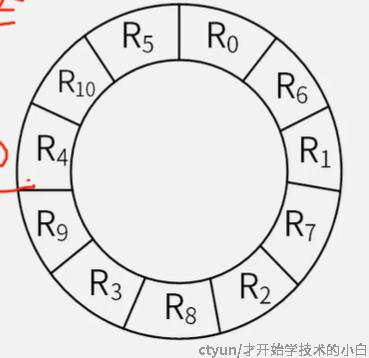
非常明显,这样太耗时间了,所以我们通常是需要优化一下这个扇区的分布,让连续的数据存储的不连续;比如要存一个两个扇区才存的下的数据,读的时候往往也是连续读的,我们就考虑采用下面这种间隔一个的方法来设置R:
6.磁盘管理-磁盘移臂调度算法
移臂调度实际上就是垂直寻道的过程,这个算法主要有四种(描述的是磁头的移动过程):
- FCFS:先来先服务,谁先申请就先去找谁,最简单的寻道方法,效率比较低
- SSTF:最短寻道时间优先,考虑距当前位置最短的寻道申请
- SCAN:扫描算法/电梯算法,类比电梯,比如电梯从1楼到10楼,中间所有楼层的响应都会被“顺便”处理;可以自内向外也可以自外向内,是双向的
- CSCAN:循环扫描算法,单向的扫描算法,比如说规定只能自外向内,磁头只能从外向内移动(移动到最内侧就会调回最外侧)
7.磁盘管理-磁盘单缓冲区与双缓冲区读取
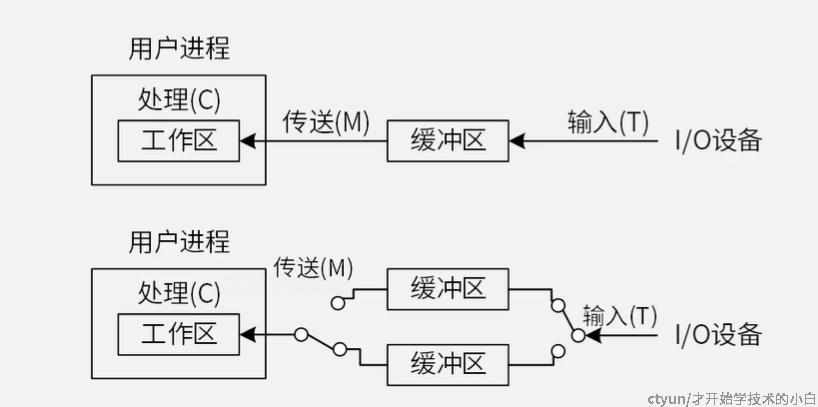
单缓冲区必须要等到数据传送入工作区之后,才可以输入下一个数据;双缓冲区可以在数据输入完成之后就进行下一个数据的输入。逻辑如下: