


数据机制
Zookeeper提供的命名空间非常像一个标准的文件系统,节点名称由斜杠(/)分隔的路径元素构成,在Zookeeper命名空间中的节点通过路径进行标识。

[Zookeeper的层级命名空间]
与标准的文件系统不同,Zookeeper命名空间中的每个节点都可以关联数据和子节点,这就好像拥有一个支持既是文件也是目录的文件系统。(Zookeeper设计上是用于存储协调数据的:状态信息、配置、地址信息等,所以每个节点上保存的数据通常比较小,一般是KB级别。)
我们使用术语znode表示Zookeeper的数据节点,除数据外,znode包含以下统计属性:
|
节点属性 |
说明 |
|
cZxid |
触发znode创建的事务ID |
|
ctime |
znode创建毫秒时间戳 |
|
mZxid |
触发znode最近修改的事务ID |
|
mtime |
znode最近修改毫秒时间戳 |
|
pZxid |
触发znode最近子节点变更(仅列表)的事务ID |
|
cversion |
znode子节点变更版本号 |
|
dataVersion |
znode数据变更版本号 |
|
aclVersion |
znode访问控制列表(ACL)变更版本号 |
|
ephemeralOwner |
临时节点所属的sessionID,如果非临时节点,则为0 |
|
dataLength |
znode数据长度 |
|
numChildren |
znode子节点数据 |
znode包含多种类型,按持久化、顺序和失效机制,可分为以下几类:
|
节点类型 |
说明 |
|
持久节点(persistence znode) |
不管客户端是否连接,该节点都存在有效,默认情况下所有节点都是持久的 |
|
临时节点(ephemeral znode) |
临时节点的生命周期和客户端会话绑定在一起,客户端会话失效,则这个节点就会被自动清除 |
|
顺序节点(sequential znode) |
表示节点顺序关系,创建时在路径后附加递增序号,序号在父节点下唯一,它也分为持久的和临时的 |
|
容器节点(container znode) |
当容器节点的子节点数量为0时,会自动删除该节点,除此之外和持久节点没有区别 |
|
TTL节点(ttl znode) |
针对持久或持久顺序节点,可以设置生存时间(Time To Live),当节点在TTL时间内未修改且没有子节点,将自动被择机删除 |
Zookeeper提供一套watch机制监听znode变更, 在3.6.0(不含)之前watch事件的触发是一次性的,即当设置的watch关注的数据更新时,会发送相应的watch事件给客户端,但后续znode再次更新时,就不会再发送watch事件了,除非客户端再次设置新的watch进行监听。一次性的触发机制存在获取当次watch事件和发起下次watch监听的延迟,如果znode变更频繁,将无法感知此期间的变更,使用时需了解这种情况并做对应处理。
在3.6.0(含)之后,Zookeeper支持设置持久化(触发后不移除)递归(在子节点上递归注册)的watch监听,可以避免上面监听空窗期事件丢失问题,主要支持下列事件:
- NodeCreated
- NodeDeleted
- NodeDataChanged
同步设计
依赖watch机制实现znode数据逻辑同步结构如图:

- FullExtracter:全量数据抽取,通过遍历节点和数据实现
- IncrementExtracter:增量数据抽取,通过监听节点事件实现
- DataTransformer:数据转换,将全量抽取和增量抽取的数据转换为待装载数据
- FullQueue:全量数据队列,全量数据抽取的待装载数据
- IncrementQueue:增量数据队列,增量数据抽取的待装载数据
- DataLoader:数据装载,从数据队列中读取数据并写到目标实例
数据同步分为全量同步和增量实时同步两个过程,但这两个过程不是串行的,而是交错运行,关注几点:
- 增量过程的事件监听需早于全量过程,避免监听空窗期数据变更丢失,如:
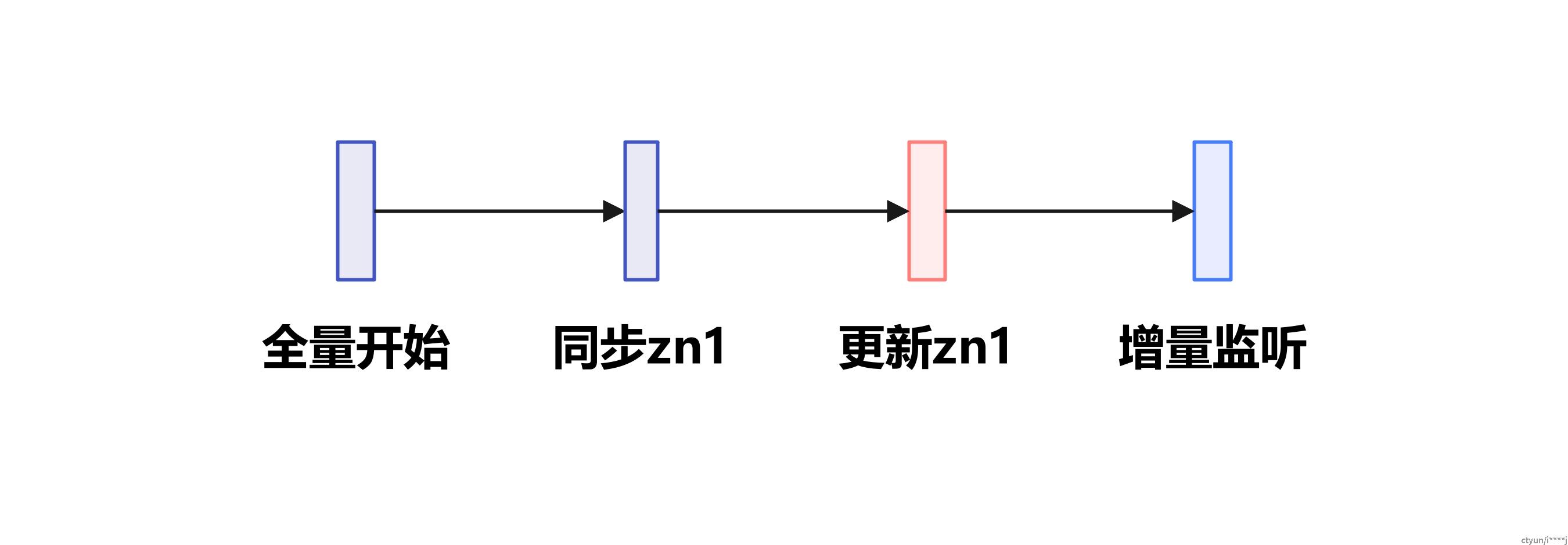
- 全量过程的数据装载需判断数据版本,避免覆盖增量过程的较新数据,如:

- 增量过程的节点更新事件可能早于全量过程的创建行为,需要转换操作,如:
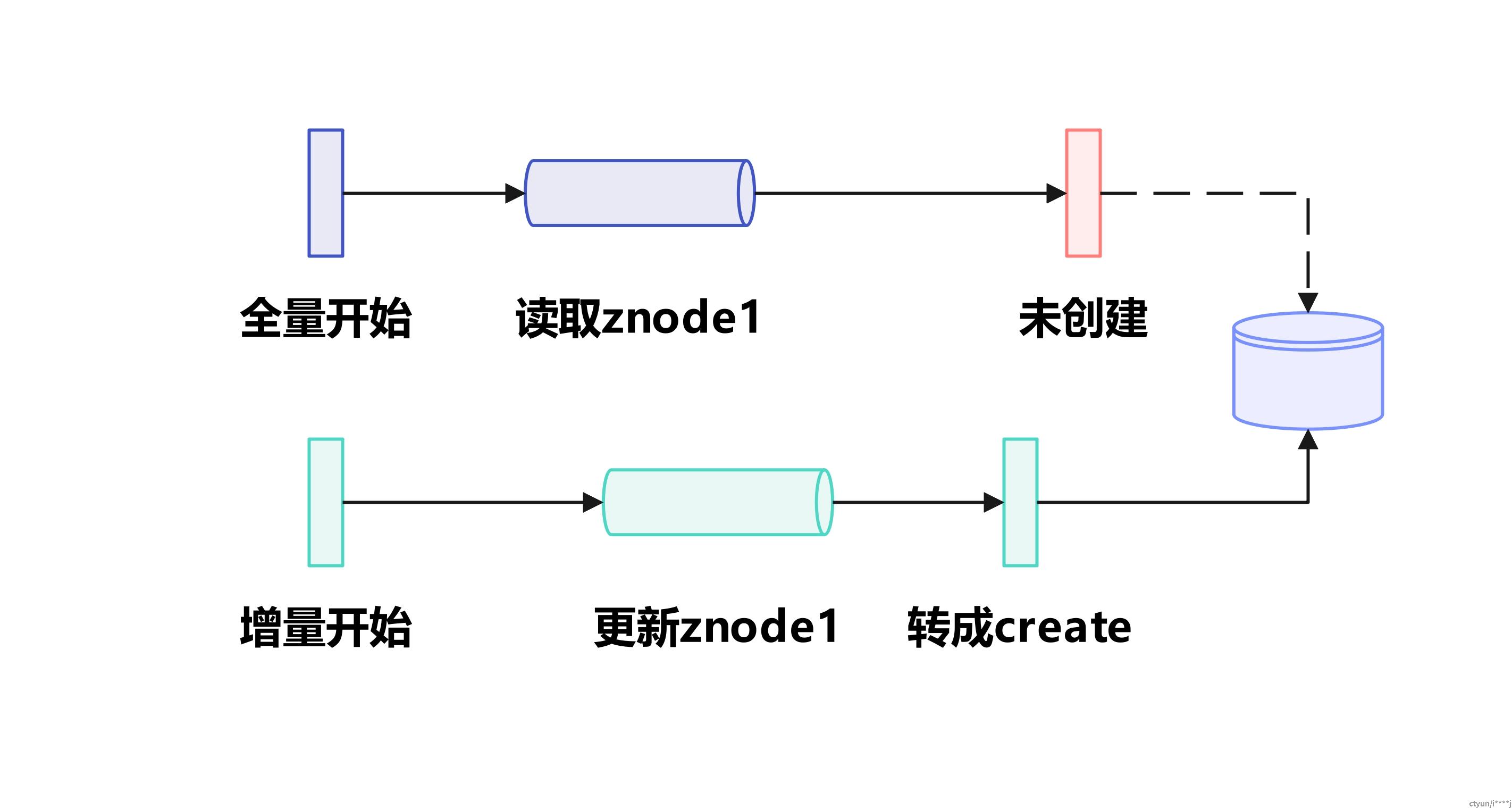
- 两次同步间隔的数据依赖全量补齐,需要位点减少重复,如:
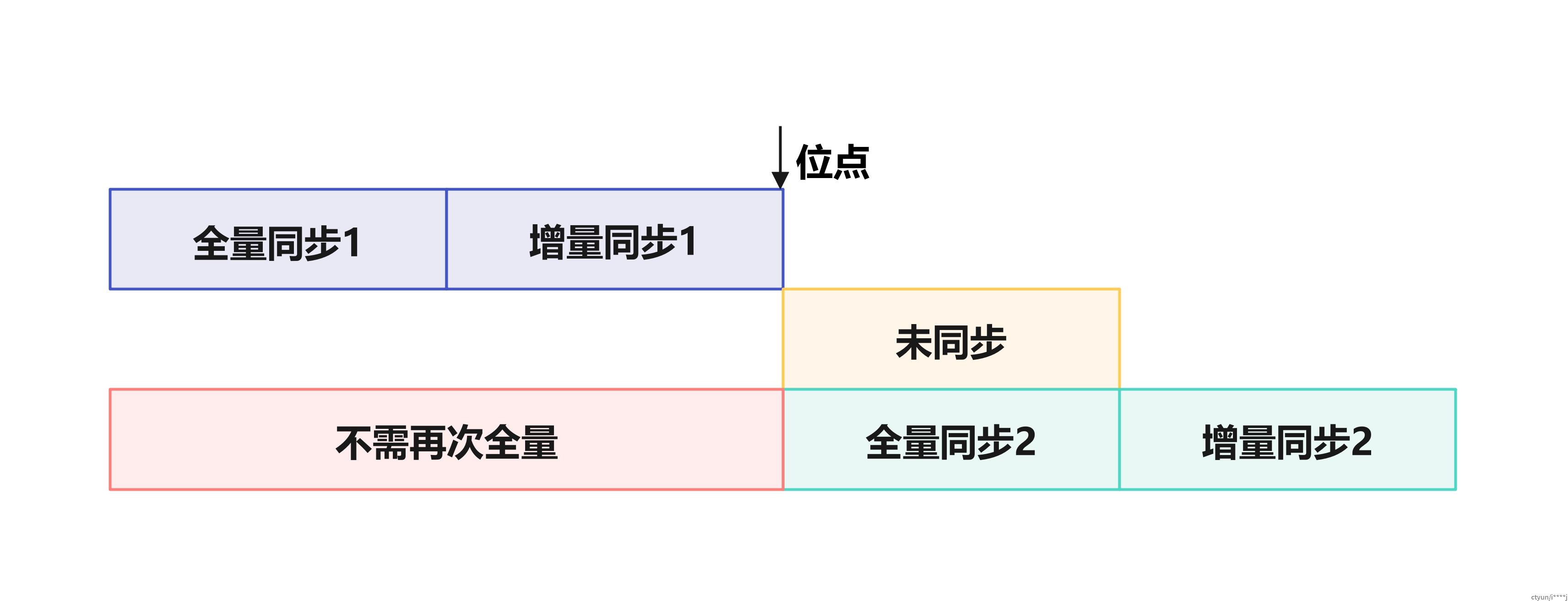
综上同步流程如图:
特别地,这里采用逻辑同步Zookeeper数据的方式不考虑ACL数据同步,本方案是模拟Zookeeper客户端读取和监听节点数据,ACL有特殊限制已不满足。如果确有需求,可在znode变更时,增加getACL和setACL操作代替。
另外再讨论不同节点类型对同步流程的影响,原则上同步过程只在目标集群创建持久节点,节点路径和生命周期通过监听源集群的事件来变更:
|
节点类型 |
说明 |
|
持久节点(persistence znode) |
正常同步 |
|
临时节点(ephemeral znode) |
可以不同步 |
|
顺序节点(sequential znode) |
根据持久和临时区分 |
|
容器节点(container znode) |
正常同步 |
|
TTL节点(ttl znode) |
正常同步 |
实现方式
Apache Curator是一个比较完善的Zookeeper客户端框架,通过封装的一套高级API,简化了Zookeeper的操作,因此在实际应用中被广泛使用。

Curator的使用比较简单,针对Zookeeper 3.6.0(含)以上版本需要配合5.0.0以上版本使用,重点关注CuratorCache在znode事件监听中的使用,它有几个特点:
- 支持节点或子树的本地缓存
- 支持响应create/update/delete事件
- 支持响应事件时数据前后对比
示例代码:
String connectString = "";
int sessionTimeoutMs = 1000;
int connectionTimeoutMs = 1000;
RetryPolicy retryPolicy = new RetryOneTime(1);
try (CuratorFramework client = CuratorFrameworkFactory.newClient(connectString, sessionTimeoutMs, connectionTimeoutMs, retryPolicy)) {
client.start();
try (CuratorCache cache = CuratorCache.build(client, "/test")) {
cache.listenable().addListener((type, oldNode, node) -> {
switch (type) {
case NODE_CREATED:
case NODE_CHANGED:
case NODE_DELETED:
}
});
}
}