


问题提出
当我们讨论容灾方案的时候往往倾向于讨论采用什么构架和如何去建设,大的方面像是冷备热备还是多活,小的方面像是单机房还是多机房、同城还是异地、单集群还是多集群等等,我把这些叫做静态容灾。但是容灾最终能取得什么效果,更多是看灾难发生后,如何引导请求流量和数据流量到正确的地方,我把这些叫做动态容灾。可以说,静态容灾描述了方案可能达到的上限,动态容灾决定了方案实际产生的作用。
从系统的终态来讲,数据的准确就代表着业务的准确,我们把上述动态容灾过程中引导数据流量到正确地方的过程叫做数据保护,实际也是对业务准确性的保护。容灾的核心是冗余跟转移,数据保护就是要在流量转移过程中解决冗余数据的一致性问题。
一般来说,主要在多活场景才考虑数据保护问题,灾备场景在容灾时基本没有写冲突。针对可能出现数据不一致问题的情况,列举如下:
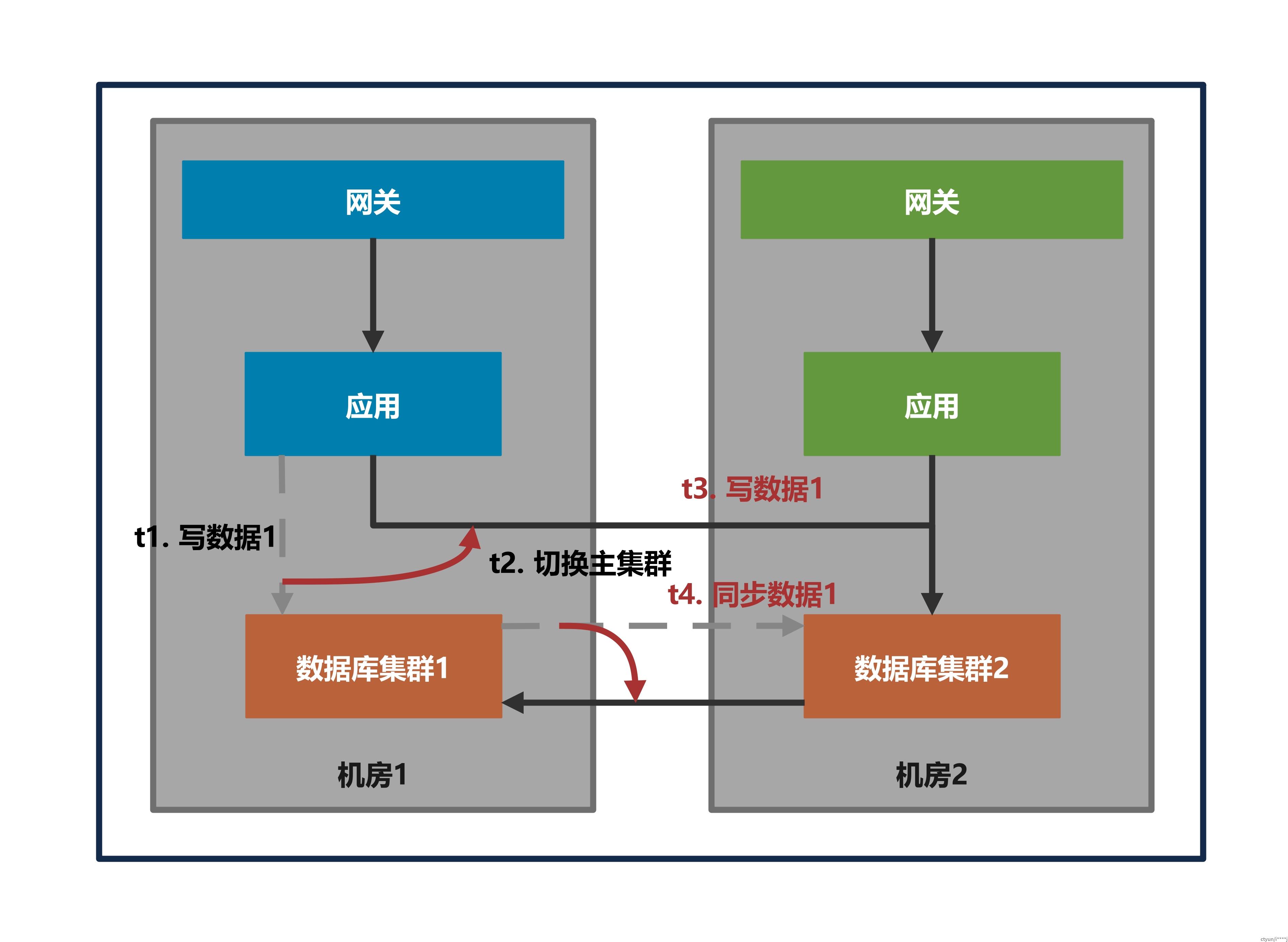
(一)在业务均读写主数据库场景,切换主数据库时,业务流量与数据同步写冲突。
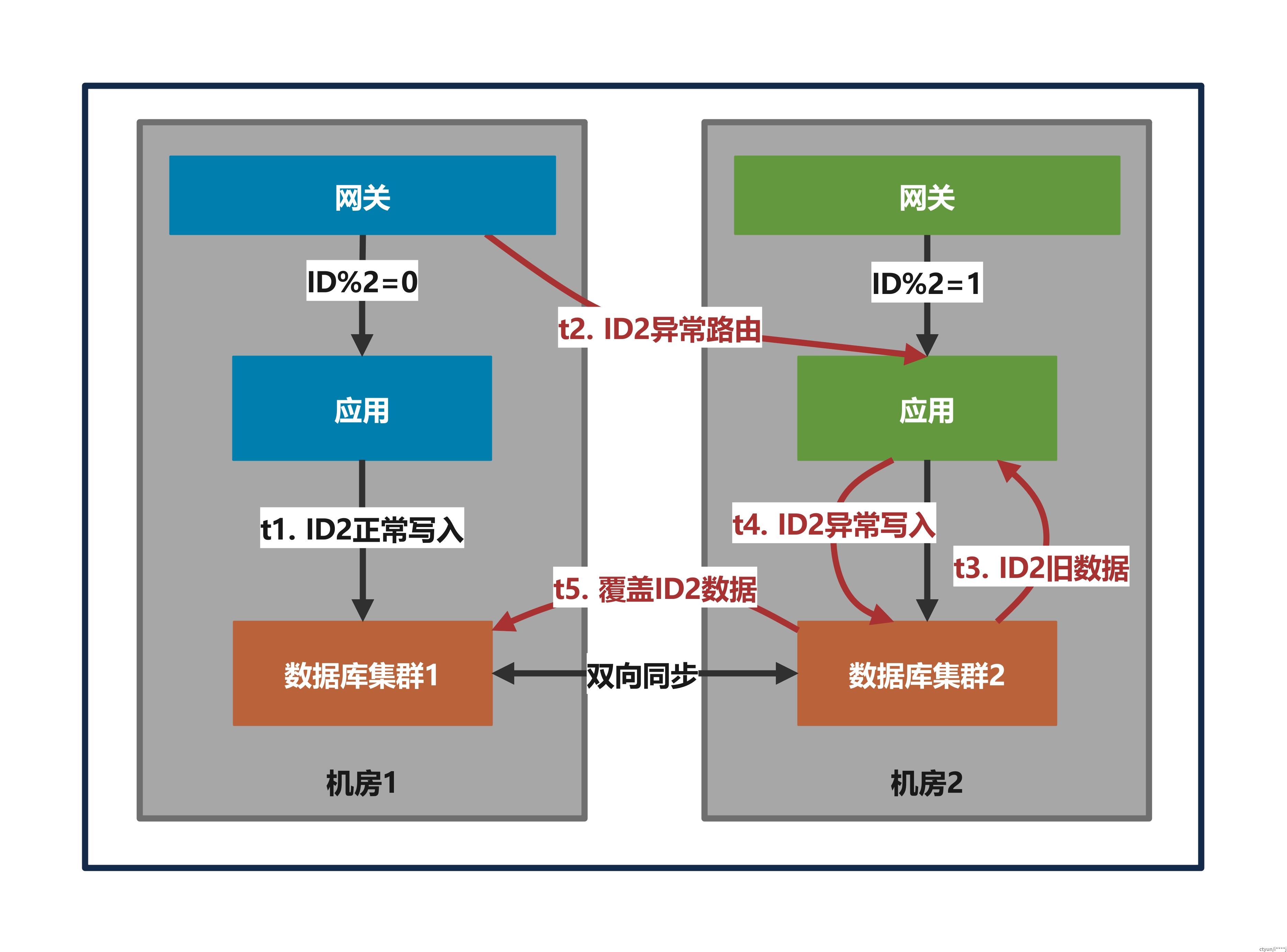
(二)在单元化场景,上游流量纠错发生异常(如路由标丢失、路由规则推送失败等),不同单元写冲突。
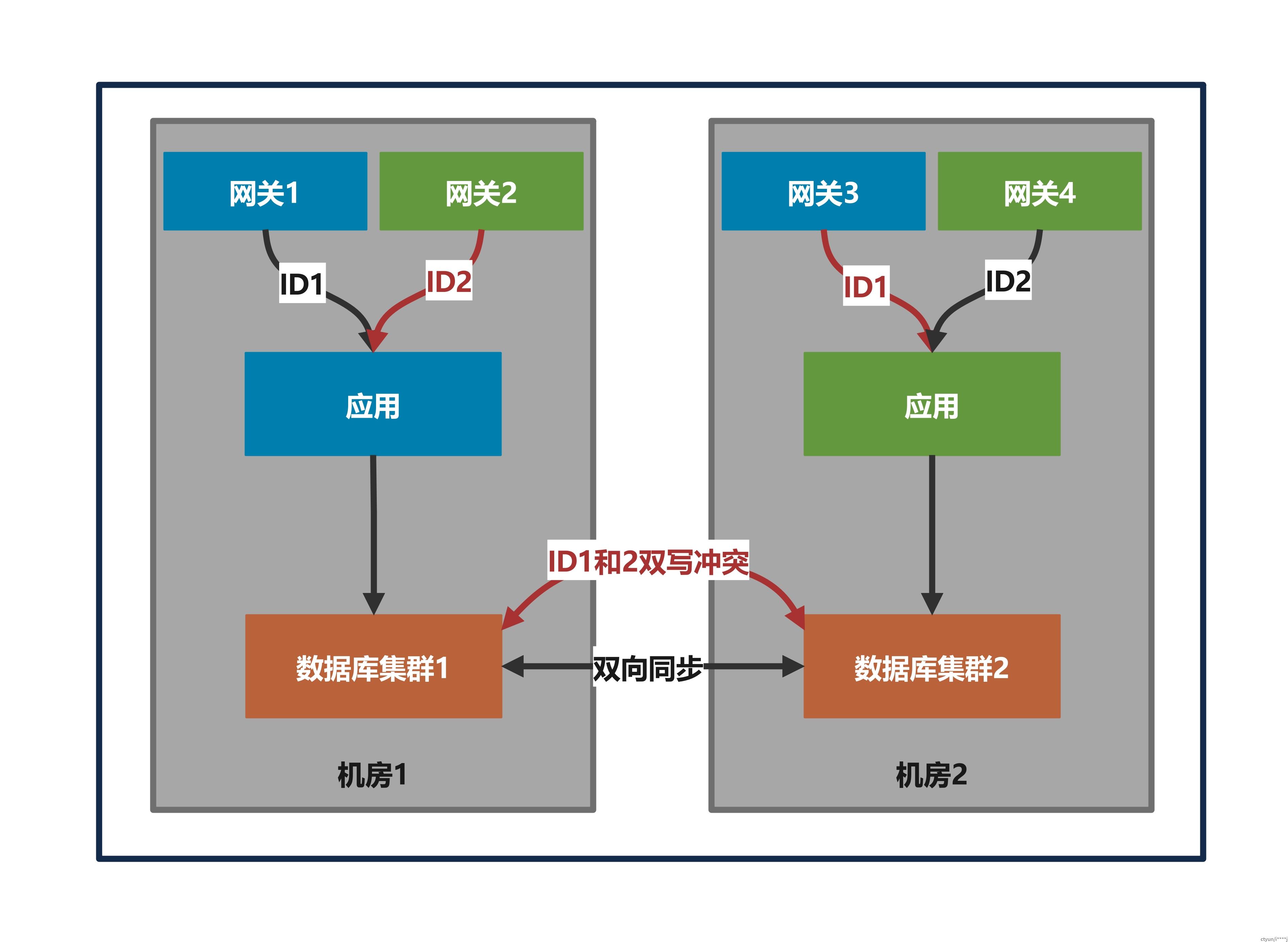
(三)在单元化场景,切流时接入网关和应用节点短时间会存在不同机器路由规则不一致的情况。
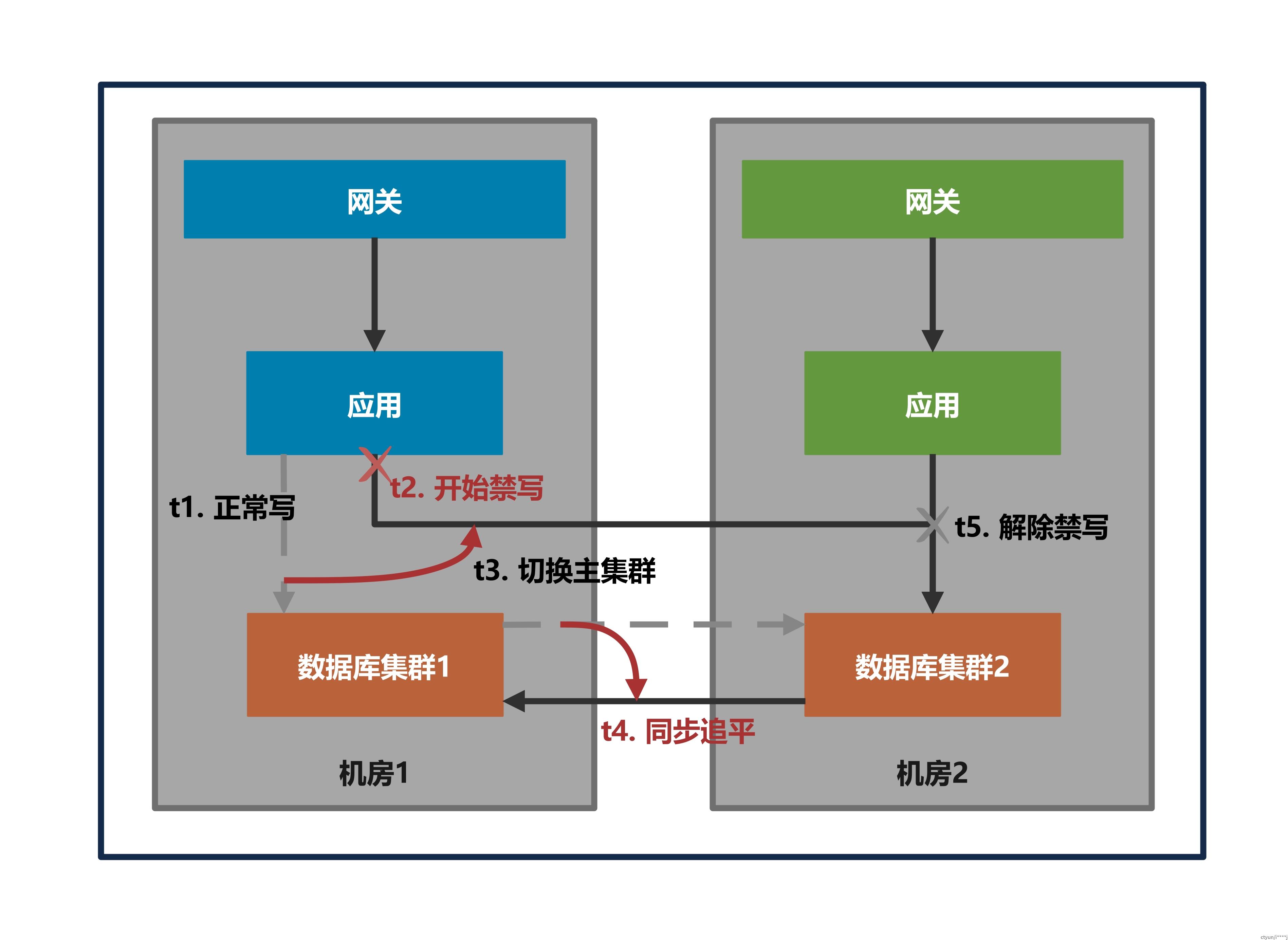
(四)在单元化场景,接入网关和应用节点路由规则更新后,数据同步如果存在延迟,目的机房内的应用可能会读到旧数据,以及更新的数据会被同步数据覆盖。

解决方案
数据层是读写数据库前的最后一道关卡,相比采用异步或定时数据对账来事后发现数据不一致问题的方式,在数据写入前通过路由正确性校验和错误流量禁写等保护措施,能够提早杜绝数据不一致的发生,从而避免此类问题的进一步扩大和蔓延。
业务集成数据层多活功能通常有SDK、Agent、Sidecar等不同形态,集成方式不影响功能逻辑,通过路由正确性校验和错误流量禁写进行数据保护的方式,需要考虑几个问题:
- 业务当前读写的数据源是哪个
- 业务当前的流量标识是什么
- 业务当前流量能否写当前数据源
其中流量标识从上层传递过来,数据源的选择是瞬时判断不是持续过程,正常情况下读写是不限制的,数据保护是对第3个问题在禁写上的判断:
- 什么时间开始禁写
- 禁写的范围多大
- 什么时候结束禁写
结合前面的问题场景讨论:
(一)在业务均读写主数据库场景,切换主数据库的流程需要禁写保护。
- 开始禁写:切换主数据库前
- 禁写范围:所有机房内的写操作
- 结束禁写:机房数据同步追平
这个场景不需要计算流量标识,应用节点感知多个数据集群并从中选择主集群,向应用节点推送主集群配置前应先推送禁写指令,避免原有同步链路延迟导致数据覆盖和应用节点不同机器规则不一致导致写冲突。(类似问题场景三和四)
在具体实现中,如何判断同步链路已追平也是个棘手的问题,不同的数据源和同步工具对同步位点的获取和管理难度不同,判断RPO的精度也可能大相径庭,兜底的方式是结合粗略的延迟信息,设置一个长等待时间,过期后解除禁写。
(二)问题场景二到四都是单元化场景,应用只写本地数据库集群,关键在于根据流量标识计算是否需要禁写,数据保护可以概括为日常态保护和切流态保护两类。
- 日常态保护:写数据时根据最新的路由规则进行计算,若是错误流量则禁止写入,避免正确流量和错误流量分别在多个机房读写数据,造成脏写。(对应问题场景二)
- 切流态保护:切流的过程就是向接入网关和应用节点推送路由规则的过程,数据保护分为规则全量前和规则全量后两个阶段。
- 规则全量前:在流量路由规则变更和推送到接入网关和应用节点期间,对所有单元内的应用采取禁写策略,保证切流期间数据不脏写。(对应问题场景三)
- 规则全量后:在数据同步延迟期间,对切流目的单元内的应用采取禁写策略,避免出现脏写以及写后又被同步数据覆盖的问题。(对应问题场景四)
单元化场景需要计算流量标识进行数据库写操作限制,在具体实现中一般需要代理数据库连接和执行对象(如Java的数据库Driver/Connection/Statement对象),并实现SQL解析进行拦截判断。
值得讨论的是如何最小化禁写的范围,以便最大程度地减少对用户的影响。前面切流态保护在规则全量前的禁写控制,实际也需要做一次全量的禁写规则推送,假设以用户作为流量路由标识,这期间禁止所有用户写操作不会产生写冲突,因为只导致写中断而不导致写飘移,影响范围是所有用户在两个规则全量周期不可写(禁写规则+路由规则)。从影响最小的角度来说,这个阶段只需要禁写所有因为规则变更导致写飘移的用户(即从切流终态来看,流量从原单元切换到其他单元的用户),但这需要计算所有单元的并集,而且复杂度不太可估计(复杂度与单元数、路由规则和标识数量等正相关),如果配置推送不是瓶颈,可以不考虑优化。
如图示例,两次规则差值很难计算和表达:
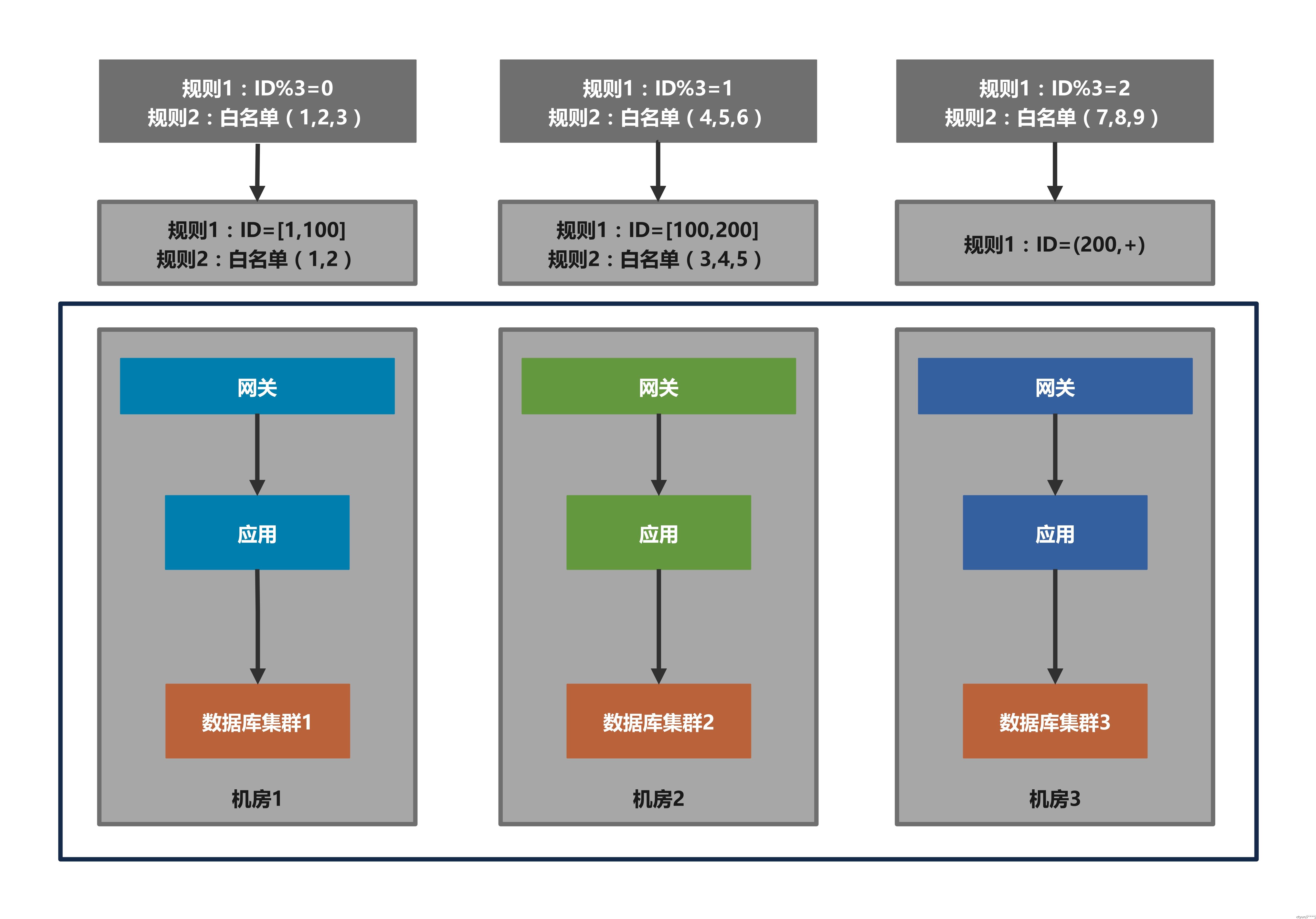
但是对于切流态保护在全量规则后的禁写控制,是可以只针对迁移过来的用户进行禁写的。因为每个机房都已有新旧规则配置:
- 如果路由标匹配新规则而不匹配旧规则,说明流量是迁移过来的,需要等同步延迟追平
- 如果路由标既匹配新规则也匹配旧规则,说明流量没有变化,可以正常读写
- 如果路由标不匹配新规则,说明流量已迁移出去,不能进行写操作(对应日常态保护)
这个阶段只需要本地进行匹配判断,不需要全局计算差值,也不依赖其他单元:

