


高可用系统的建设,不是单纯的技术设计考究,而是所有团队的工程化配合:除了考虑产品的SLA诉求,还需要考虑研发的迭代效率、运维的操作能力和整体的成本预算。
可以确定的是,SLA等级、成本花费和技术复杂度是成正比的,不是所有的业务都需要“5个9”的可用性,所以我们会对业务进行分层,在各方面取舍,最终形成某些解决范式。MySQL也是如此,针对不同的SLA要求,官方提供了不同的解决方案:
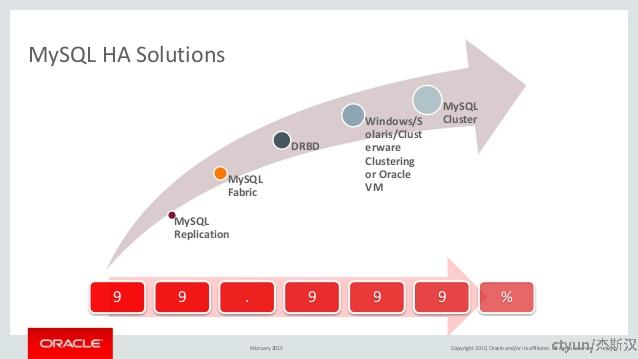
[图片来源:MySQL High Availability Solutions]
撇开不能横向扩展(Scale-out)的方式,MySQL高可用的基本方法有复制(MySQL Replication)和集群(MySQL Cluster)两种类型,细分下来有:
- Replication
- Semisynchronous Replication
- Group Replication
- MySQL InnoDB Cluster
- MySQL InnoDB ClusterSet
- MySQL InnoDB ReplicaSet
MySQL Replication
Replication是MySQL官方提供的主从同步实现,基于异步复制的主备集群是应用最广的MySQL高可用容灾方案,它有以下优点:
- 横向扩展(Scale-out solutions):从节点(replica)可以分摊负载以达到提升集群整体性能的效果。虽然所有的写入和更新操作只能在主节点(source)中进行,但从节点可以分担读流量,主节点也因为读压力降低从而具备更好的写入性能。
- 数据安全(Data security):这里可以有两层含义,一是从节点的数据和复制过程是独立的,在从节点上进行操作不会污染主节点的数据,二是主节点异常的时候,从节点的备份可以防止数据丢失和损坏。
- 数据分析(Analytics):数据在主节点产生,在从节点中进行数据分析任务不会影响主节点性能。
- 长距离数据分发(Long-distance data distribution):通过复制可以将本地数据提供给远程站点使用,而不需一直远程连接主库。
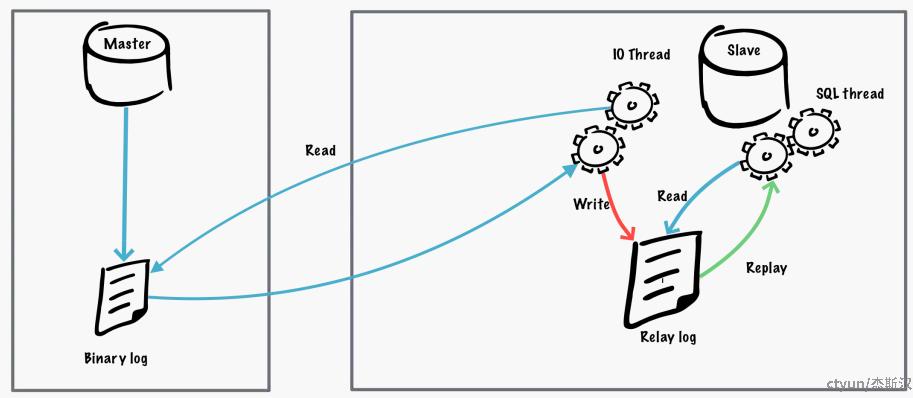
Replication的基本原理是基于变更日志(Binary log)的事件(Replicating event)重放,有如下线程模型和行为:
- 主库为每个连接的从库分配一个Dump thread,用于发送本地变更日志
- 从库创建IO thread,用于连接主库和拉取日志,并将日志写入本地重放日志(Relay log)
- 从库的SQL thread读取本地日志重放,完成主库数据传播到从库
除此之外,在MySQL 5.6.5版本增加了一种基于全局事务标识(GTID,Global transaction identifier)的复制方式,基本结构与事件重放一样,日志组成和处理有所不同,相比之下有以下优点:
- GTID由实例ID和事务ID组成,可以定位事务提交实例
- 故障转移(Failover)更方便,不需要指定文件和偏移量
- 可以实现基于库的并行复制,性能较好
- 可以确保事务只执行一次,更能保障数据一致性
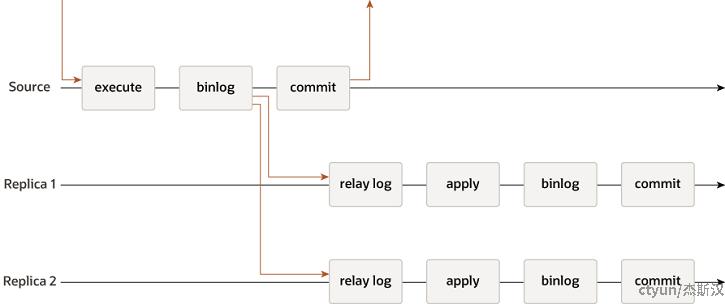
在同步模式上,根据主库等待从库执行的情况,可以分为三类:
- 异步复制:MySQL默认的复制方式,主库执行完客户端提交的事务后即返回,不关注从库是否已接收处理。 这种方式性能较好,主从同步基本不影响主库性能,但无法估算故障转移时数据丢失的范围。
- 全同步复制:主库在事务执行过程增加等待机制,确保所有从库将日志落盘才提交。这种方式像一种变相的2PC协议,能保障故障转移的数据一致性,但性能非常差,一般不使用。
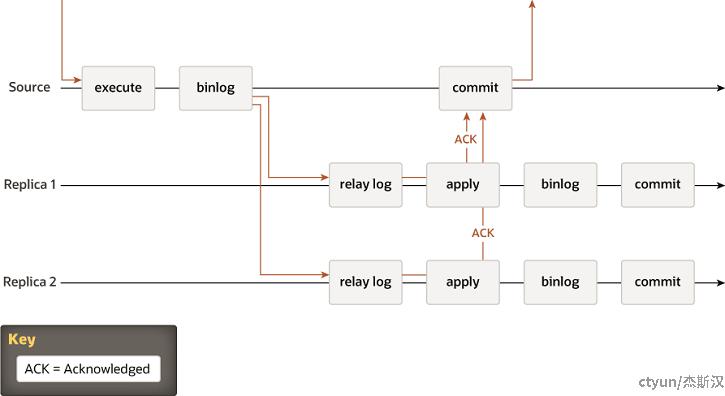
- 半同步复制(Semisynchronous Replication):介于异步复制和全同步复制之间,只等待至少一个从库日志落盘。之前是主库本地先提交事务(Commit)再等待从库响应(ACK),发生故障转移时可能会有幻读的情况(也是数据丢失的情况,即提升为主库的从库没有上个主库已提交的数据),在MySQL 5.7版本改成等待响应后再提交,修补了这个缺陷,也叫增强半同步复制。
半同步复制虽然确保事务要至少传播给一个从节点,但在故障转移时维持数据一致性还是很困难:
- 主库发生故障时,缺乏快速定位拥有最新数据从节点的方式:要么通过人工或外部工具检测集群中每个节点的数据状态,这样就拉长了恢复时间(RTO);要么无视从节点数据状态,任一选择恢复,这样就可能失去最新同步的数据(RPO),已提交最新同步数据的从节点还要进行数据回滚。
- 即使提升拥有最新数据的从节点为主库,也还有数据冲突的可能:如果故障前主库在等待提交(Pending),日志还未同步给从节点,在旧的主节点重启加入现集群时,不能自动提交Pending的事务,因为现集群的节点中没有这条事务,所以需要进行回滚。
其实也很容易理解,毕竟“如果光靠复制有用的话,那还要一致性算法干嘛”,前面提到的各种复制过程,只是尽可能在保障性能的情况下,数据能有最新冗余,至于如何故障切换、如何处理网络分裂这些是没过多考虑的。MySQL官方在2016年12月发布了组复制(MGR,MySQL Group Replication)方案,基于分布式Paxos协议,内置故障检测和自动选主功能,在集群大多数节点存活的情况下能持续工作,并保证数据一致性。
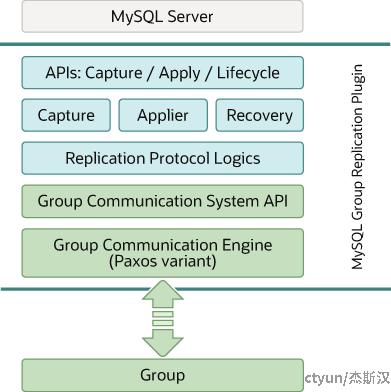
组复制并没有脱离MySQL数据复制的框架,通过插件的方式,在同步过程增加基于分布式一致性算法的认证(Certify)阶段。在这种模式下,集群是可以支持多点写入的,通过行级别的检测处理事务冲突,被集群拒绝的事务由发起者本地回滚。
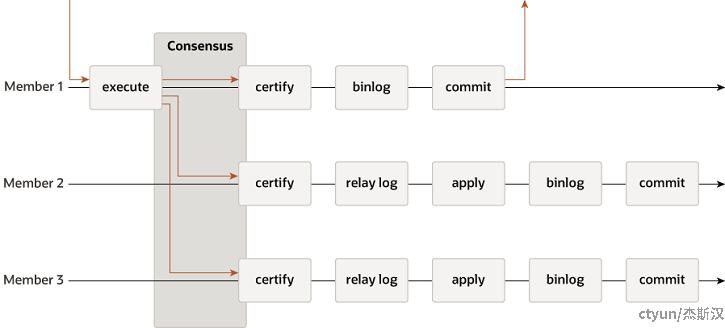
从业务的视角来看,MGR解决的是MySQL服务的高可用问题,并不能说数据库启用了MGR,业务就拥有了一个对节点故障无感知的数据库集群。例如,集群中的某个节点挂了,之前连接到这个节点的客户端请求需要能重定向或故障转移,这些功能需要额外的中间件(如Connector、Load Balancer、Router等),仅MGR方案本身是没有提供的,MySQL的集群(Cluster)方案通过集成路由组件(MySQL Router)提供了支持。
MySQL Cluster
MySQL InnoDB Cluster提供了一个完整的MySQL高可用解决方案,从结构上看,它由一个高可用集群和上层路由组件构成。
- HA Cluster:集群的数据节点,一组InnoDB数据库实例,通过组复制协议实现数据一致性和高可用。
- MySQL Router:集群的路由节点,客户端的实际连接对象,通过连接集群任一存活节点获取并更新可用节点列表,根据可用节点列表和路由规则转发客户端请求。
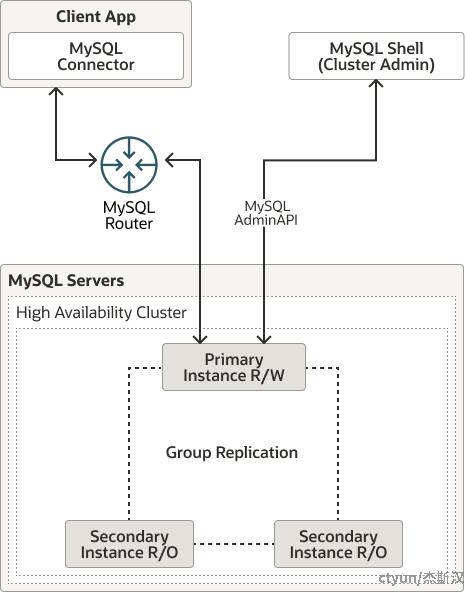
可以将MySQL Router看作MySQL Cluster的透明反向代理,一般将MySQL Router部署到应用相同主机上,一方面可以依靠系统支持的本地Socket减少多一个节点的网络开销,另一方面不需要处理Router高可用的套娃问题。
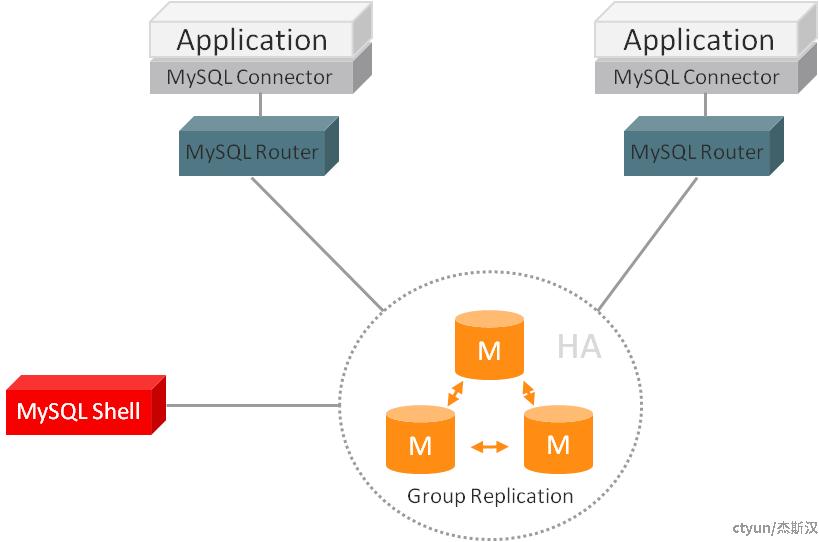
MySQL在2020年还提供了一种叫MySQL InnoDB ReplicaSet的解决方案,与MySQL InnoDB Cluster对比,主要的区别是数据节点不是MGR集群而是一主多从的集群,前面提到的Replication的毛病基本都有,好处就是集成了MySQL Router方便配置和故障切换。从能力上讲Cluster方案是更好的,但如果需要更高的写性能,或网络状况比较糟糕,那ReplicaSet可以弥补集群模式的一些缺陷。
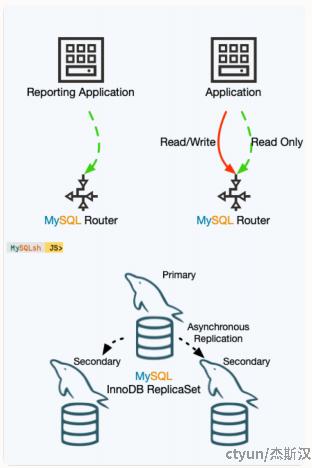
分布式一致性算法的共识过程受网络影响很大,网络稳定性和节点数量会增加阻塞和回退概率,从而影响集群的写入性能。MySQL InnoDB ClusterSet提供了一种解决方案,能够支持本地集群高可用和跨数据中心的容灾。
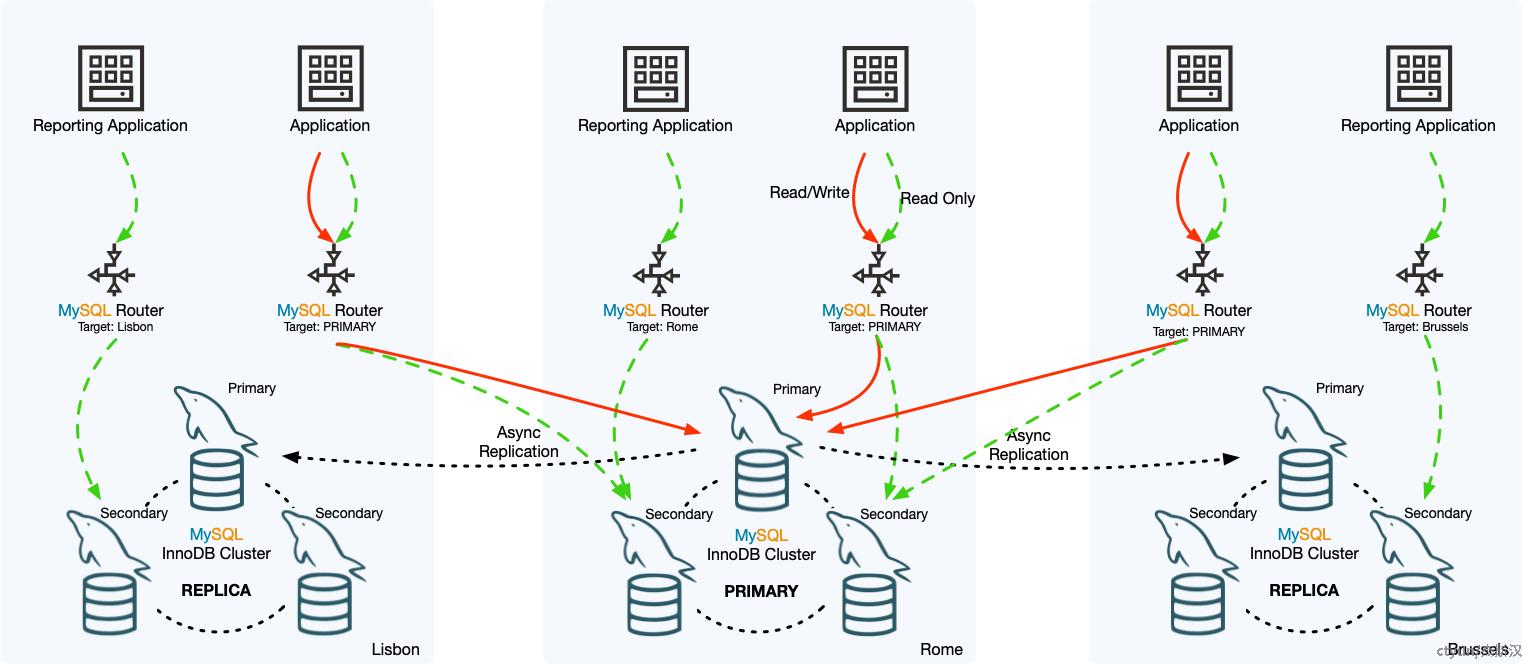
MySQL InnoDB ClusterSet和MySQL ReplicaSet在架构上是雷同的,只不过节点对象从单实例变成InnoDB Cluster集群,集群间数据同步在集群的主节点中进行。这样揭开面纱后,与ReplicaSet一样,ClusterSet的优缺点就呼之欲出了:
- 优点是集成了MySQL Router方便配置和故障切换,本地数据中心支持集群高可用,同时提供了远距离跨数据中心的容灾。
- 缺点是只支持单主构架和异步复制,远程数据中心业务需要跨中心写入,影响性能,由于同步延迟的缘故,只能支持少量对延迟不敏感的业务读扩展。另外这个方案只提供可用性保障,不保障数据一致性,业务无法自动故障切换(Failover),需要人工介入处理从集群不同程度延迟,旧主集群重新上线还需要尽快摘除并进行数据回退,以免产生数据冲突。
