


Distributed programming is the art of solving the same problem that you can solve on a single computer using multiple computers.
——《Distributed systems: for fun and profit》
一个计算机系统需要实现两项基本任务,存储和计算。如果有一台永远在线、无限容量、无限算力的设备,或许就不需要分布式系统了。可以说分布式系统是为了解决单机无法解决的问题引入的,而分布式程序又是为了让多台设备像单机一样处理问题设计的。
成本收益往往是我们率先考虑的问题,构建一个分布式系统,该用什么规格的机器,以及应该使用多少,通过不甚准确地引用《The Datacenter as a Computer: An Introduction to the Design of Warehouse-Scale Machines》中的两个图表,尝试进行说明。
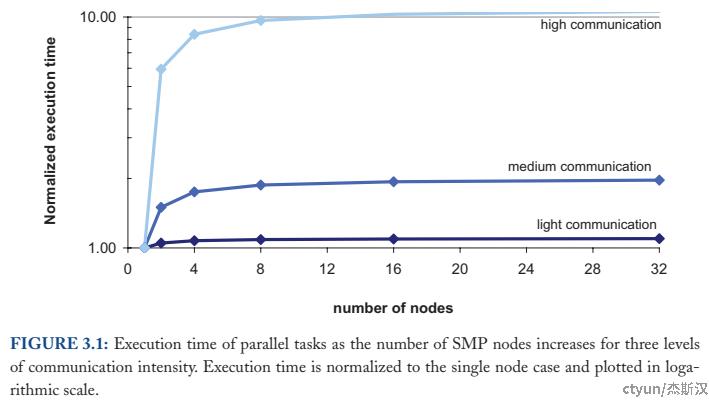
性能是描述一个系统运行效果的关键,速度指标体现计算能力,常用任务的执行耗时表示。从寄存器、内存、外存到局域网、广域网,逻辑节点间的信息交换速率,极大地影响任务的性能表现。
考虑一项单机任务拆分多个节点协同完成的场景,集群之于单机,虽然一定程度上扩展了存储和计算能力,但也增加了节点间的通信开销。如上图所示,以单机任务耗时为基准,越高的通信成本带来更多的性能惩罚(额外耗时),在少量节点时犹为明显,往后则边际降低。
从粗略定性的角度来看,一项任务不需要集群的所有节点参与,性能惩罚约略正比于节点间通信次数乘以节点间通信开销,所以随着节点数量增加而收敛。在这种情况下,相比于单任务耗时,系统的整体吞吐量是评估集群适宜规模的标准,而任务耗时可以作为判断边际收敛的条件。
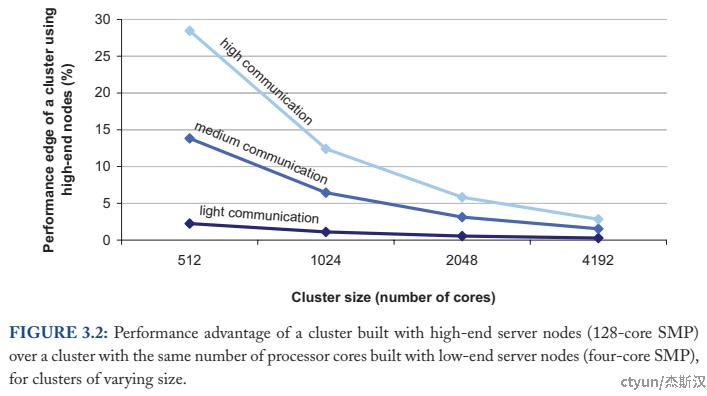
集群的计算资源常用CPU核数指代,在相同计算资源的情况下,高端硬件的计算性能优势很大程度来源于高速的内部内存访问代替较慢的远程网络访问。但是,只要节点间交互不可避免,通信开销就极大限制了单机硬件规格带来的性能优势。
上图展示了高端硬件相对普通硬件的性能差距随着集群规模增长而降低的情况,可以从内外访问比例的角度进行理解,当集群规模增长带动外部访问比例增加时,平均访问速度就越趋近于远程访问速度,硬件规格带来的内部访问性能影响被逐渐抹平。从这一角度出发,现今常用中等规格的普通机器构建分布式集群,有其可定量的合理性。
我们把分布式系统能消纳不断增长的工作量的特性称为可扩展性。在这过程中,既要关注“增长但稳定”的因素,
- 规模可扩展性:节点数量增长能带来处理能力线性增长,量级增长不影响系统的性能表现
- 地域可扩展性:多数据中心能够优化用户体验,跨数据中心交互在合理的延迟范围
也要关注“稳定但增长”的因素。
- 管理可扩展性:扩展规模和地域不显著增加系统的管理成本
通常来说,在分布式系统中机器堆叠的收益不完全是线性增长的,要使多台机器联合起来表现得跟一台机器一样,需要很多额外开销,例如存储复制,计算协同,凡此种种。同样的,不同规模的集群管理成本也不能简单线性外推,在少节点时无关紧要的问题,随着规模的增长可能会跨越某个临界点,变得一发不可收拾。也就是说,在分布式系统发展的不同阶段,都需要特定算法与之匹配,以解决当下最紧迫的问题。
衡量系统扩展良好的标准之一是系统表现保持稳定,一般从性能和可用性两方面分析系统的表现,每个方面都有多种指标和测算方法。
系统性能是通过给定时间和资源能完成的有效工作量或给定工作量所需的时间和资源来衡量的,根据侧重点不同,指标和测算也不相同:
- 低延迟:请求的响应时间短
- 高吞吐:任务的处理数量大
- 低负载:使用的计算资源少
就像鱼和熊掌不可兼得,这三个指标也伴随着取舍,低延迟依赖处理效率,往往需要更多的资源开销,高吞吐需要堆集批次,往往将单任务的响应时间拉长。在分布式的世界里,很少有非黑即白的绝对标准,权衡的艺术渗透到其中方方面面。
系统可用性相对来说易于计算但难以衡量,它可以用极其简单的公式表示:
- Availability=uptime/(uptime+downtime)
不存在判断系统是否正常工作的绝对标准,这是难以量化的业务容忍度,除了无可非议的连通性问题,有些业务接受10秒响应延迟,而有些业务却只能接受1秒,有些业务接受处理降级,而有些业务却只能硬性等待,不一而足。
但可以确定的是上层业务逻辑不在系统可用性的考虑范畴,影响系统可用性的因素分为两个方面:
- 系统内因素:指构成系统的部分模块异常,根据抽象层级不同,可以是单台机器、单个数据库、服务集群或整个数据中心
- 系统外因素:指系统无法掌控但又影响系统使用的部分,例如用户与系统接入点之间的外部网络
分布式系统的稳定性需要建立在不稳定的组件之上,解决方式是面向异常设计,也就是常说的要做容灾。容灾首先得定义会出现的异常,然后再设计一套方案来应对,我们没有办法“容忍”未曾考虑过的“灾难”,这也说明风险预案的必要性。
分治与冗余是分布式系统可扩展性的基础,体现在数据面上,就是分区(partition)与复制(replicate)两个基本方法。分区和复制都有拆分的意味,将特定的数据集放在离使用方更近的地方,从而提升系统的性能表现。对可用性来说,分区意味着隔离,能够压缩故障的影响范围,而复制的数据冗余则是一切恢复和连续性的基础。
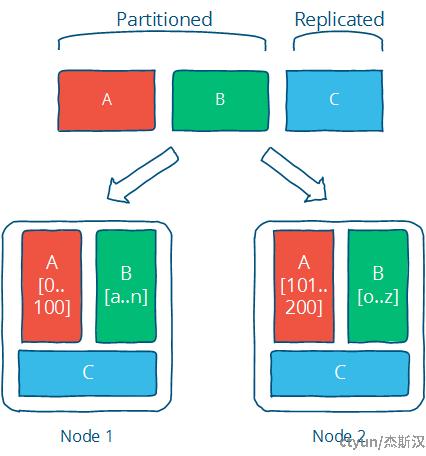
如果将系统任务比作建筑施工,那么数据分布就是建设的蓝图,凡涉及数据的任务,其运行或能抽象成数据分布收敛于某个既定设计的过程,可以说一个分布式系统的基本运转机制是对其分布数据维护的一个状态机。
回到计算机系统的两项基本任务,在分布式系统中单机的处理逻辑被淡化,任务的执行过程更多是对离散节点的协调过程。分布式系统中任何变更操作的终结,都依赖于集群的节点达成某种共识。
绝大部分情况下,不存在完全去中心化的应用,即便是由角色完全对等的节点构建的集群,落到具体操作上,多数会转变成局部中心化的模型,以提升整体的决策效率。在这个角度下,集群共识并不需要所有节点都参与决策,而是由协调者根据其他节点反馈的信息决定,其他节点按照某种既定规则“学习”这个结果。
