


传统BPF 主要用于网络包处理,扩展BPF简称eBPF能够实现更多功能,体现在跟多的hook点,更丰富的helper函数。
根本上讲,不论是BPF还是eBPF都是创建一个虚拟的执行环境,默认使用的环境为原生执行环境,符合当前处理器体系架构,执行效率高,原生的指令配套原生的CPU,效率杠杠的。在这种环境下,安全防护手段、攻击手段方方面面,演进过程中,出现了一种防护手段。这种手段随虚拟化产生,老早的IBM服务器本身就是共享型的大型服务器,这时候能做到的虚拟就是终端虚拟,虚拟的目的其实就是共享资源,起初是没有硬件虚拟化加持,技术演进过程中因为资源利用率不足,衍生出硬件虚拟化,目的也是提高资源利用率,让一台机器共享给多人使用。然后虚拟化又分为完全虚拟化、半虚拟化,在软件层面,也会用类似名称去描述,比如,虚拟机加密
虚拟机加密的工作原理大致可以分为以下几个步骤:
不管是硬件虚拟化,还是软件虚拟化,还是虚拟机加密,说到底,就是两个字“隔离“。隔离执行环境,保证虚拟机内部执行环境的安全性,这里的安全也只是有限安全,可以只考虑机密性,数据被破坏了也没关系,大不了直接撂摊子宕机,也要保证核心机密不泄露,类似以biba、blp一样,允许破坏数据也要保证机密性。当然这也是一般情况,实际不同“虚拟化”机制实现各有千秋,各有特色,总有一个侧重点。
回过头来,eBPF的“虚拟化“方式,它是构造了一个精简指令集执行环境,说白了就是苟在一个 “加减乘除“ 基本操作的环境,任何一种编程语言都可以这么玩。“根据给定的输入,执行返回结果“ 这里给定输入,分为精简指令、复杂指令,指令长度不同而已,执行,就分为用特有的硬件去执行,还是用软件模拟执行。 eBPF是支持通过硬件执行的,目前所知是智能网卡,能够执行特定的eBPF程序,只要是网络方面。但大部分eBPF,是通过软件模拟实现的。这跟Qemu、KVM有异曲同工之处。
进一步,虚拟机执行,就要区分,创建虚拟机、进入虚拟机、虚拟机内部执行、退出虚拟机一系列操作,区分不同的运行时上下文。eBPF类似,加载eBPF程序,attach到指定hook点,触发eBPF执行,结束退出。hook点从哪里来?eBPF直接用了Linux内核中已有的hook机制,典型的kprobe、tracepoint,它们都是在内核中,特定函数特定位置,增加钩子。常见钩子就是jump, 钩子是跟特定执行流关联,当内核执行流走到钩子位置,跳转到预埋的函数,执行完成后再回到原始位置(下一个指令)继续执行。kprobe有init3、jump机制,效率不同机制不同而已,本质还是为了执行扩展逻辑,这些扩展逻辑就可以花里胡哨了,什么内核热修复、热更新常用到这个。因此kprobe类型的ebpf程序,就是借用了成熟的kprobe 、kretprobe机制增加钩子,跳转到“虚拟机“执行ebpf逻辑
ebpf虚拟机,它是个每条指令定长的虚拟机,简单说,输入就是定长的字符串。下面用c写一个最简单的"虚拟机"
| #include #include // 定义指令集 typedef enum { OP_ADD, // 加法 OP_SUB, // 减法 OP_PRINT, // 打印 OP_HALT // 停止 } OpCode; // 定义指令结构 typedef struct { OpCode code; int operand; } Instruction; // 虚拟机状态 typedef struct { int *memory; // 内存 int *registers; // 寄存器 int pc; // 程序计数器 } VMState; // 初始化虚拟机 void initVM(VMState *vm, int memSize) { vm->memory = (int *)malloc(sizeof(int) * memSize); vm->registers = (int *)malloc(sizeof(int) * 10); // 假设有10个寄存器 vm->pc = 0; } // 执行指令 void executeInstruction(VMState *vm, Instruction *instr) { switch (instr->code) { case OP_ADD: vm->registers[0] += instr->operand; break; case OP_SUB: vm->registers[0] -= instr->operand; break; case OP_PRINT: printf("Register 0: %d\n", vm->registers[0]); break; case OP_HALT: printf("VM Halted.\n"); exit(0); default: printf("Unknown instruction.\n"); exit(1); } } // 运行虚拟机 void runVM(VMState *vm, Instruction *program, int programSize) { while (vm->pc pc]); vm->pc++; } } int main() { // 定义一个简单的程序 Instruction program[] = { {OP_ADD, 5}, {OP_PRINT, 0}, {OP_SUB, 3}, {OP_PRINT, 0}, {OP_HALT, 0} }; int programSize = sizeof(program) / sizeof(program[0]); // 初始化虚拟机 VMState vm; initVM(&vm, 1024); // 运行虚拟机 runVM(&vm, program, programSize); // 释放内存 free(vm.memory); free(vm.registers); return 0; } |
基本的虚拟机,少不了这几个组成部分:
- 指令集定义:使用枚举类型定义了虚拟机的指令集,包括加法、减法、打印和停止指令。
2. 指令结构:每个指令由操作码和操作数组成。
3. 虚拟机状态:虚拟机状态包括内存、寄存器和程序计数器。
4. 初始化虚拟机:分配内存和寄存器,并初始化程序计数器。
5. 执行指令:根据指令的操作码执行相应的操作。
5. 运行虚拟机:循环执行程序中的指令,直到遇到停止指令。
这个简单的虚拟机实现展示了如何使用C语言来模拟一个基本的计算机系统。通过扩展指令集和增加更多的功能,可以构建一个更复杂的虚拟机。
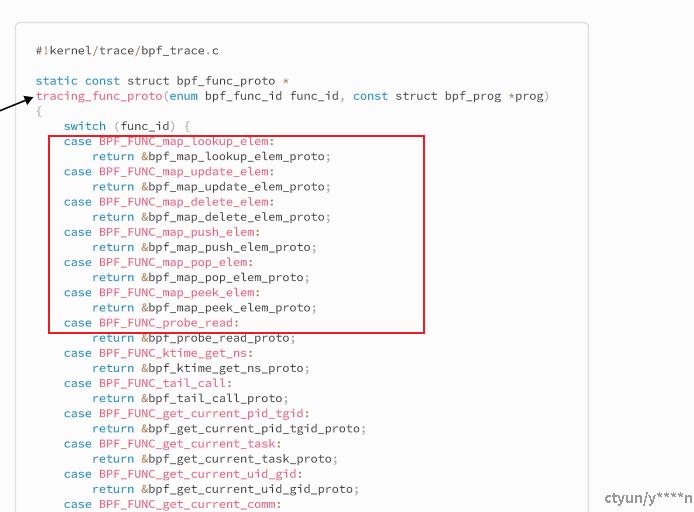
回过头来,eBPF在加载的时候就做了很多校验,包括对要放在虚拟机内部执行的代码做各种权限检查、函数替换等。为什么要替换函数?因为ebpf程序对虚拟机内部能执行的函数做了约束,所有函数都必须在可靠范围,才能保证整体可控,因此可靠性是体现在各个函数上的。如下面所示,从代码上看,kprobe ebpf就是定义了一个类型,在加载eBPF程序时候,明确用哪个hook,调用对应的verifier_ops检查helper函数。helper函数其实就是在虚拟机中,所能使用的,非常有限的一个函数集合。如果实在原生运行环境上,就跟ko模块一样,ko模块中的函数可以调用内核中所有导出的函数,而eBPF程序不行,它受到非常大的约束,以至于,虚拟机中能实现的功能,相对于ko模块,非常有限。除非,将对应功能函数也写成ebpf helper函数,这样才能在eBPF中使用
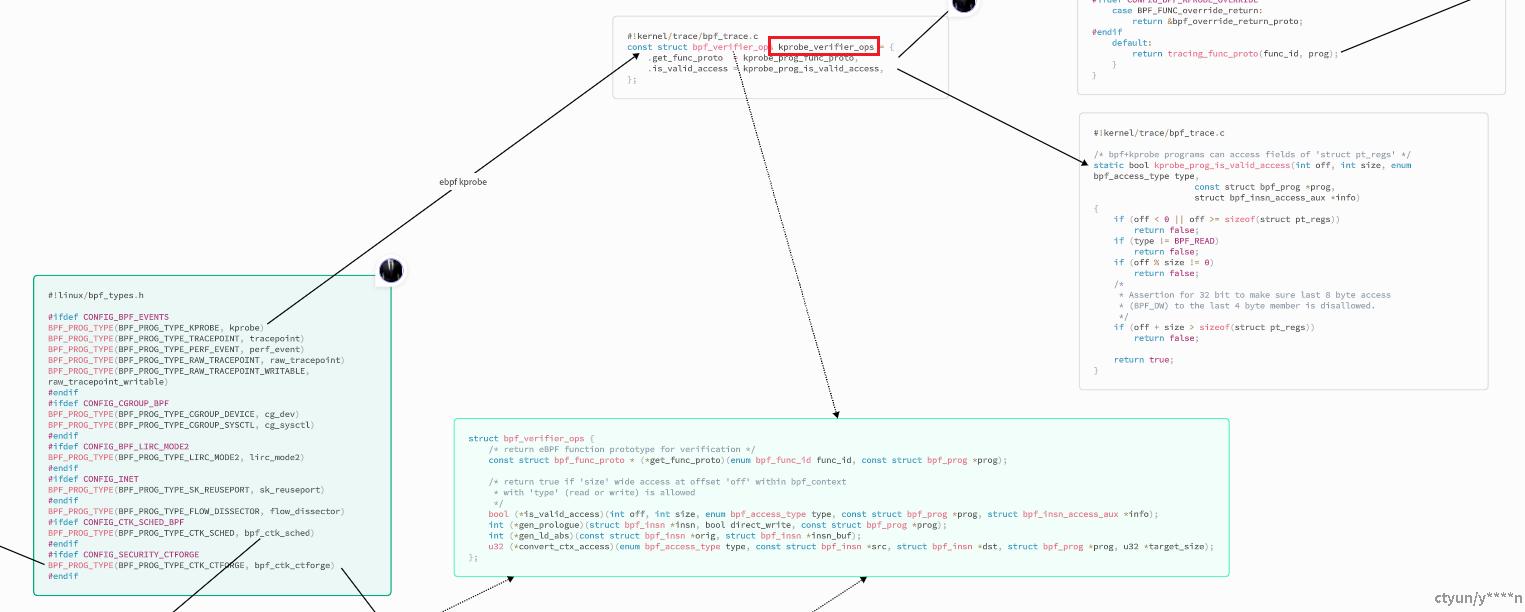
另外,对于eBPF程序中,helper函数是否有修改的功能,这里修改,是可能影响内核执行流的修改。比如修改kprobe返回值。biba、blp就可以通过这个函数,在lsm中新增模块实现。社区对这个很敏感,严格限制这类改动,也做了限制,并非所有函数都能修改,除非显示声明可修改返回值的函数。这又是一个约束,看出来了么?所谓eBPF可靠性,就是一层一层的约束,你也可以猜到,约束越多,你能做的事情也会受限。因此,使用eBPF程序对内核影响较内核模块方式要小,可靠性、安全性高,但这些纯粹相对而言,第一个很低端ebpf程序,不如一个精打细算的内核模块高效,这也不一定。对于生产环境而已,我始终认为,能经得起推敲,能满足需求,能稳定运行的就行,并不一定非得哪个哪个。不像有些公司,把python写的改成go,对外吹嘘对牛多牛,效率多高多高,线上运行一塌糊涂,何必呢,换个材料造轮子而已。

最后唠唠eBPF map,有程序总得有数据吧,eBPF的程序就是helper加常规的加减乘除,数据就是map,结构化的键值对,在eBPF程序中,所能持久化存储的就是map,通过key - value形式访问。那么其他内存地址空间,可否读写?可以,当然可以,用helper去读,不能直接读。用helper去写,不能直接写。你能想到的操作,必定有一层约束。大部分ebpf程序类型都会集成map的这些helper操作,说到底也是内核函数,ko模块中也可以调用,只是。。ebpf只能调用这些函数,其他函数调用不了而已。
综上所述,本文简单介绍了ebpf基本原理,kprobe hook方式,map的基本原理。实践出真知,建议读者看看内核代码,不复杂,很简单。
