


基本架构模型
分布式数据库天然具备多活的特性。通过写入时的分布式一致性算法,确保集群中大多数节点数据保持一致,在涉及少数节点的故障场景,能够实现无数据丢失的容灾接管(RPO=0)。
基于分布式数据库的业务应用,从节点存活的角度来看具有相同的可用性等级。不同于数据库一般从内部运行看待可用性的方式,业务应用往往从外部看待自身的可用性,即不单是实例进程的存活,流量也要同时适配实例角*的转移。在物理距离不可忽视的场景,由网络带来的性能问题,也是流量适配必然要考虑的因素。
在业务流量视角,自顶向下看是应用访问数据库的接入点问题,自底向上看是数据库的数据分布与操作暴露问题。两者不是单方面的依赖和约束,不同数据库自身的架构决定了框架上的制约,应用对数据的需求决定数据分布的规则。同时,通过引入上层管理中间件,可以调和应用与数据库的冲突,即实现对应用影响更平滑的数据库变更。
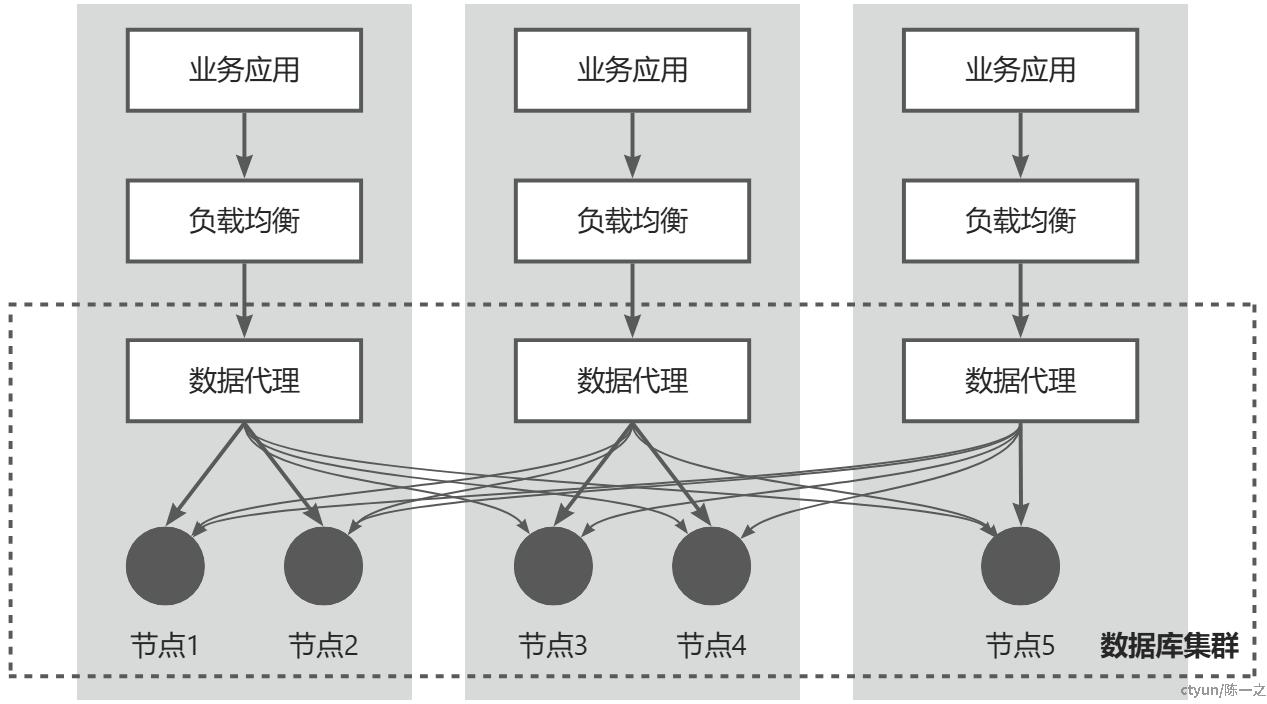
如上图所示,一般情况下,从业务应用到数据节点是一个四层架构。其中,数据库集群不直接对外暴露数据节点的情况,通过数据代理进行统一接入与数据寻址,数据代理应是无状态的,否则难以扩容与容灾;业务应用不直接连接数据代理,通过负*均衡组件平衡数据访问流量,同时解耦应用与数据库。
在流量路径上,业务应用访问本地负*均衡组件,负*均衡组件访问本地数据代理集群,数据代理可能会访问异地数据节点。可以看到,应用访问数据库的接入点是稳定的,核心是数据节点的分布和数据在节点上的分布。
TiDB整体架构
TiDB是PingCAP公司自主设计和研发的开源分布式关系型数据库,是一款同时支持在线事务处理与在线分析处理(Hybrid Transactional and Analytical Processing, HTAP)的融合型分布式数据库产品,具备水平扩缩容、金融级高可用、实时HTAP、兼容MySQL协议和MySQL生态等重要特性,适合高可用、*一致要求较高、数据规模较大等各种应用场景。
核心模块
在内核设计上,TiDB将整体架构拆分成了多个模块,各模块之间互相通信,组成完整的分布式数据库系统。对应架构如图所示:
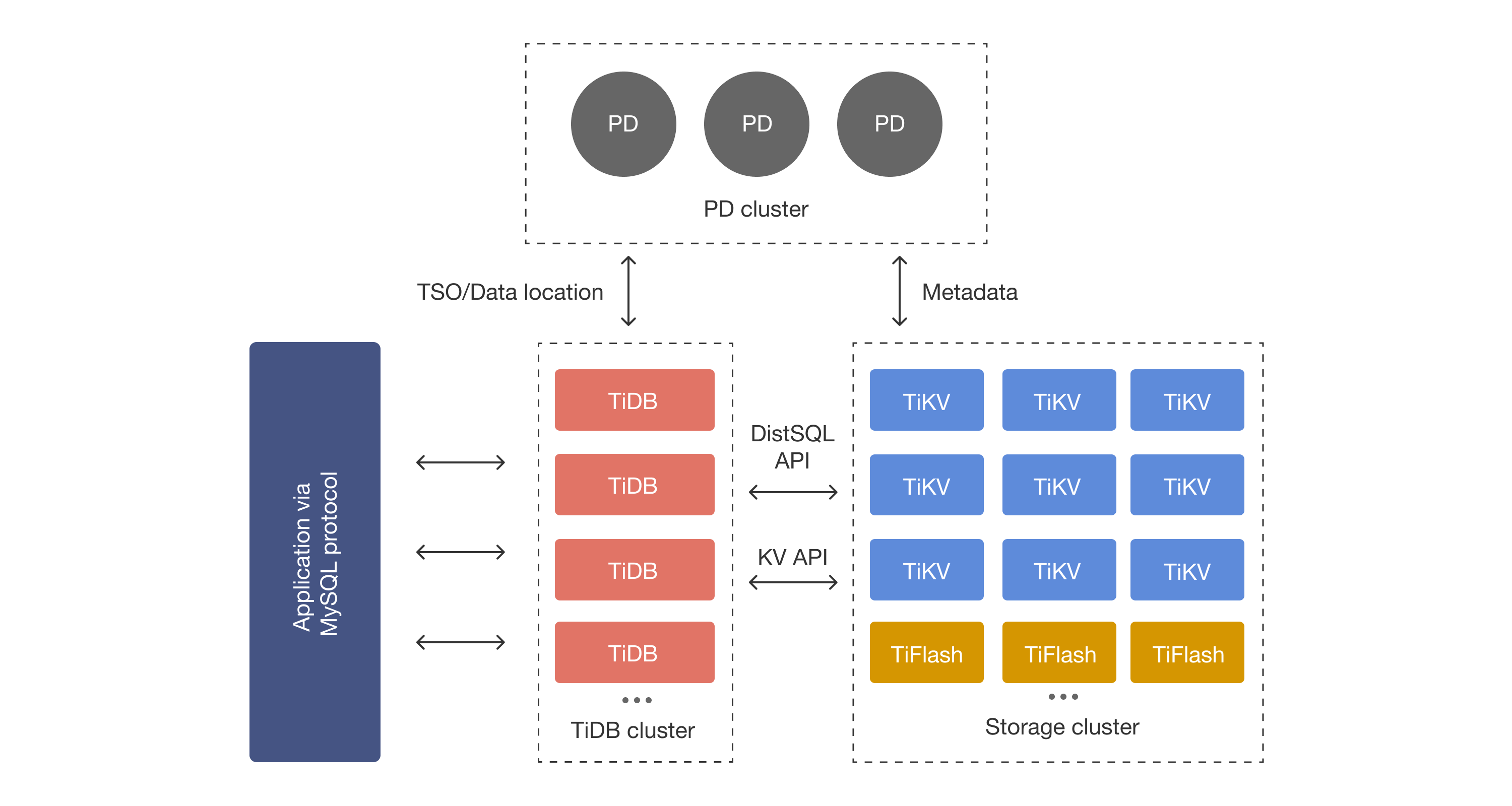
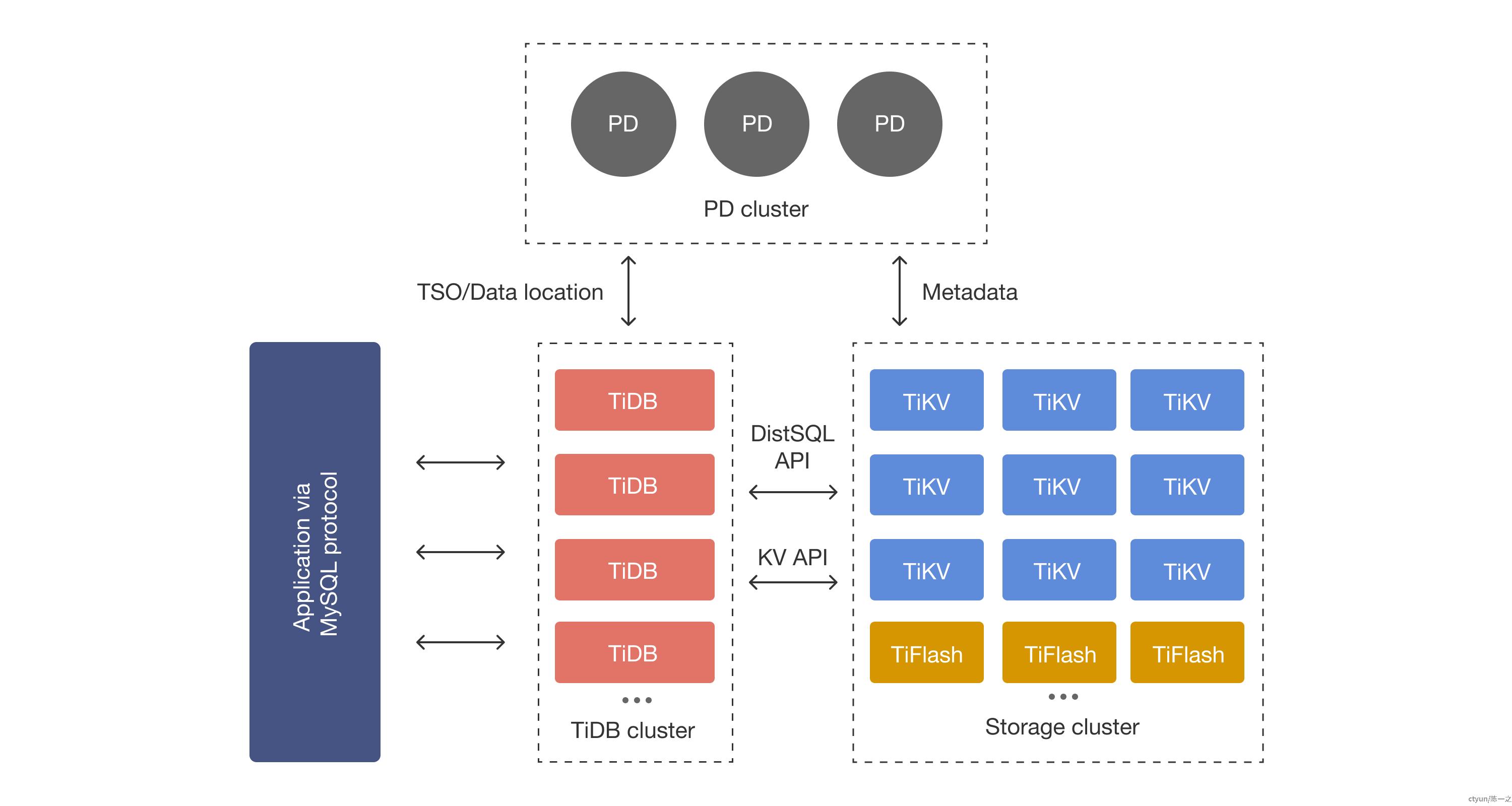
主要有三个成员:负责元信息管理的PD Server、负责请求接入的TiDB Server、负责数据存储的TiKV Server。
- PD (Placement Driver) Server:整个TiDB集群的元信息管理模块,负责存储每个TiKV节点实时的数据分布情况和集群的整体拓扑结构,提供TiDB Dashboard管控界面,并为分布式事务分配事务ID。PD不仅存储元信息,同时还会根据TiKV节点实时上报的数据分布状态,下发数据调度命令给具体的TiKV节点。
- TiDB Server:SQL层,对外暴露MySQL协议的连接endpoint,负责接受客户端的连接,执行SQL解析和优化,最终生成分布式执行计划。TiDB层本身是无状态的,不存储数据,可以启动多个TiDB实例,通过负*均衡组件(如TiProxy、LVS、HAProxy、ProxySQL、F5等)对外提供统一的接入**。
- TiKV Server:负责存储数据,从外部看TiKV是一个分布式的提供事务的Key-Value存储引擎。存储数据的基本单位是Region,每个Region负责存储一个Key Range[StartKey, EndKey)的数据,每个TiKV节点会负责多个Region。TiKV中的数据会自动维护多副本(默认为三副本),天然支持高可用和自动故障转移。
- TiFlash:TiFlash是一类特殊的存储节点。和普通TiKV节点不一样的是,TiFlash中的数据以列式进行存储,主要功能是为分析型的场景进行加速。
部署架构
在TiDB集群中,PD和TiKV都通过Raft来实现数据容灾。根据Raft的原理,集群副本数量应是奇数,集群会选举出唯一的Leader,数据读写有单点特性。
应用和数据库部署的物理区域相同,以距离和隔离程度,按地域和可用区划分,也就有跨地域容灾和跨可用区容灾。按照分布式集群特性,常见的架构有单地域多可用区架构和双地域多可用区架构,多地域多可用区架构管理模式与双地域多可用区架构雷同。考虑建设成本,TiDB还扩展了同步模式,可以支持单地域双可用区架构。
以上架构要做到高可用、一致性和对用户透明,需要特定的数据分布和调度策略共同配合实现。
单地域多可用区
单地域多可用区架构,一般是同城3AZ方案,满足任一中心故障不影响数据一致性和系统可用性。
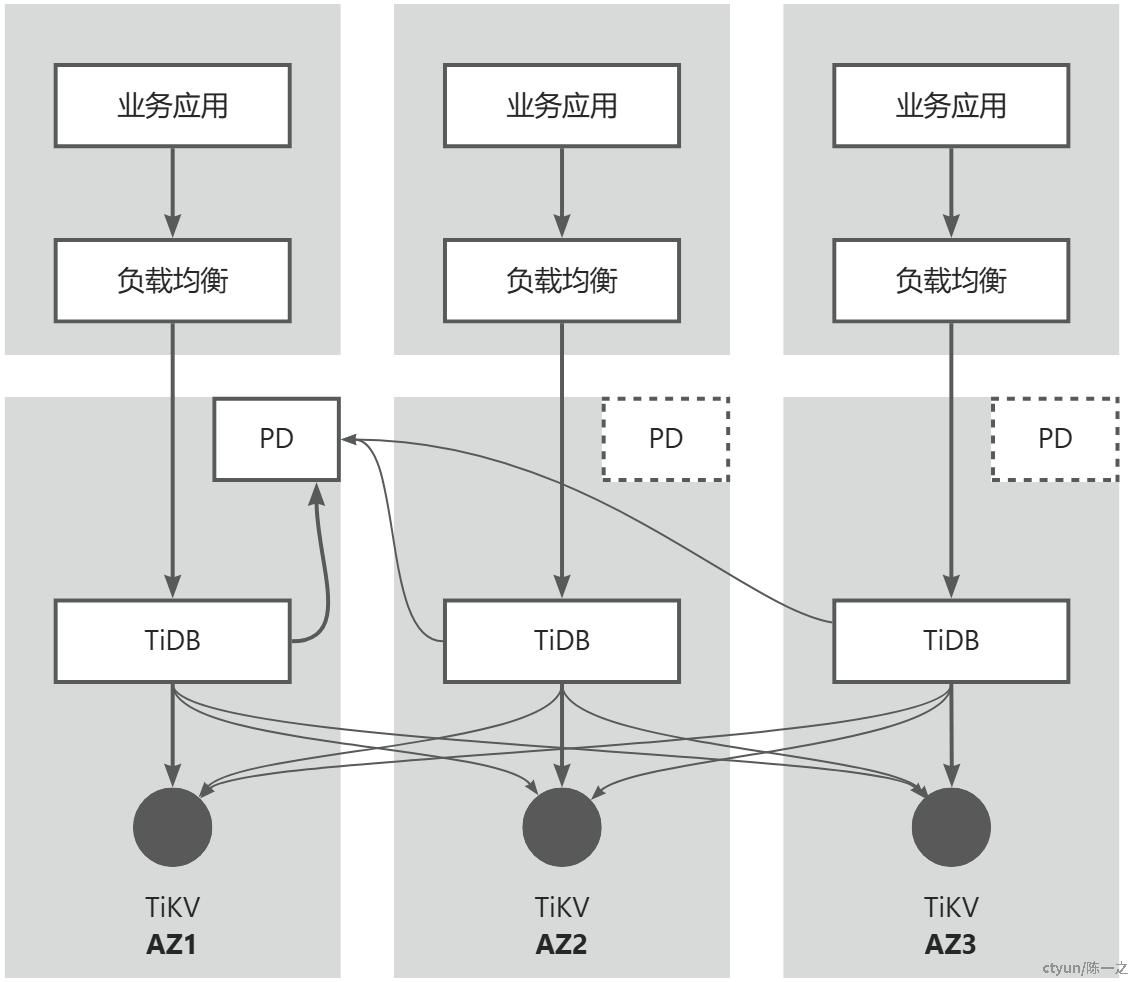
同城3AZ是TiDB集群最常规的部署架构,也是运维成本最低的方式。
- 对PD Server:
- 每个可用区部署1个PD实例,3个PD实例组成Raft集群;
- 选举其中1个实例作为Leader,PD实际在其中1个AZ进行读写;
- 任意1个PD实例故障不影响PD整体的可用性,但主PD故障会触发选举,有恢复周期(可能10秒级别)。
- 对TiDB Server:
- 每个可用区部署任意数量(不为0)的TiDB实例,可以根据流量负*决定;
- TiDB连接主PD获取元数据和TSO(Timestamp Oracle,用于全局事务时序);
- TiDB根据数据分布连接各个TiKV实例。
- 对TiKV Server:
- 每个可用区部署任意数量(不为0)的TiKV实例,数据Region的副本数和TiKV的实例数不需要完全一致,但要满足两个条件(副本数小于等于实例数,副本数为奇数);
- 任意1个TiKV实例故障不影响TiKV整体的可用性,但数据Region有主副本,固定在其中1个AZ进行读写,主副本所在TiKV实例故障会触发选举,同样有恢复周期;
- 副本数确定的情况下,增加TiKV实例数不一定能提升TiKV整体的可用性(例如3副本5实例,2个实例故障可能导致某些数据Region不可用),需要结合节点负*进行权衡。
同城3AZ架构下,节点实例故障是自愈的,一般不用进行干涉。主要副作用是跨AZ网络延迟:
- 所有写入操作需要同步复制到至少2个AZ当中,TiDB采用二阶段提交方式(Percolator事务模型),写入耗时至少为2倍AZ间网络延迟;
- TiDB中的每个事务都需要向主PD获取TSO(一般写入事件2次,只读事件1次),如果TiDB和主PD不在同一个AZ,会受AZ间网络延迟影响;
- TiDB连接数据主副本读取数据,如果TiDB和数据主副本不在同一个AZ,也有跨AZ网络延迟。
实际上不能完全避*跨AZ流量,数据写入必须要进行同步复制,这是数据集群构建的基础。可以通过调度策略将PD和Region的主节点迁移到同一个可用区,业务流量也全部路由到这个AZ,这样除复制外的流量都能在AZ内闭环,但这种方式资源闲置太多,现实意义不大。
双地域多可用区双地域多可用区架构,一般是两地三中心方案,以一地为主,有生产数据中心、同城容灾中心、异地容灾中心。
一般认为地域间的网络稳定性是不可控的,跨地域的网络延迟也不为业务所接受。根据Raft单点读写的特性,完全没有跨地域的请求是不可能的,尽可能避*跨地域延迟要满足以下条件:(1)主节点和多数集在同一地域;(2)流量尽可能分发给主节点所在地域。
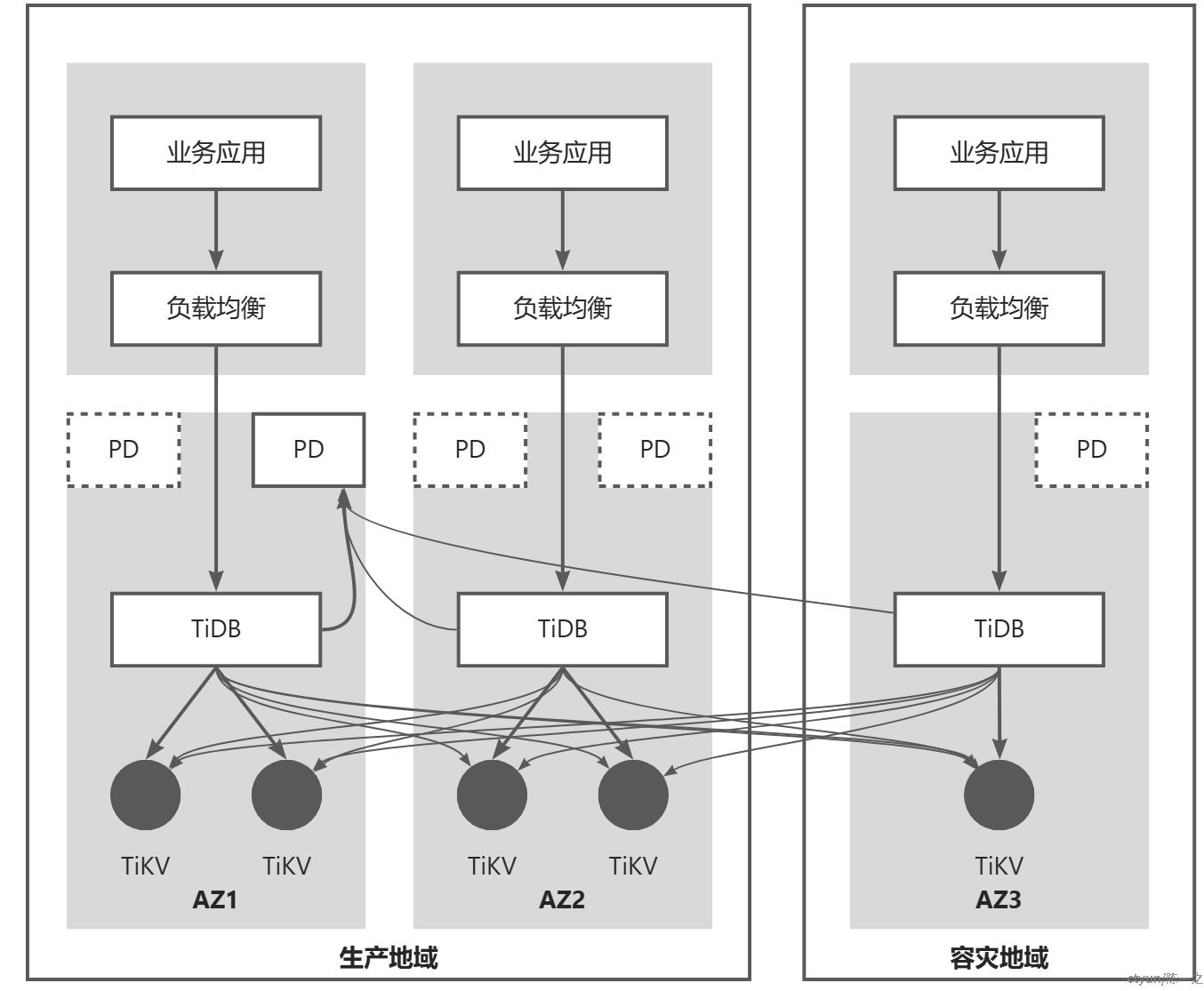
所以,两地三中心架构的设计目标以一个地域为主提供服务,能够容忍任一中心发生故障,容灾地域故障不影响生产地域业务,生产地域故障能在容灾地域恢复。为实现上述目标,TiDB官方推荐采用2-2-1的5副本数据分布模式,如上图PD和TiKV,同时通过调度策略将PD和Region的主节点限制在生产地域。
- 从可用区级别故障容忍度来说,3副本也是可行的,每个AZ持有1个副本,生产地域2AZ也能组成多数集。副本数的选择还是要*合考虑可靠性、性能、成本等方面,例如:是否有更细粒度容灾需求(如机架、主机等)、写多副本的开销、资源投入等等。
- 限制主节点仅在生产地域之后,容灾地域的业务流量必然会跨地域读写(PD、TiKV),需要业务从上层流量入口进行规划。TiDB提供了只读节点的实践,算是额外扩展,不属于集群组建的部分。
- 容灾地域故障不影响集群运转,生产地域任一AZ故障将导致集群需要跨地域达到共识,会对性能产生影响,但保障了可用性。
- 生产地域故障将导致集群暂时不可用,需要从容灾地域单副本中恢复集群,此时需要对集群进行重配置操作,也会丢失部分未同步的数据。
简单地形容两地三中心架构,可以说是跨中心的多活,跨地域的主备,中心级别故障可以自愈,主要地域故障需要外部干涉,干涉的及时性和有效性将显著影响地域级别的容灾效果。
单地域双可用区
单地域双可用区架构,指同城双活方案,一般是应用进行高可用扩展最先考虑到的方式,边际收益最高。
分布式一致性的大数原则天然不适应偶数分区,尤其是两个分区,任一分区故障可能会导致整体不可用,相较单个分区的可用性没有稳定提升。TiDB提供自适应同步(Data Replication Auto Synchronous, DR Auto-Sync)模式,通过Raft集群角*分配和状态控制来达到双活的效果。
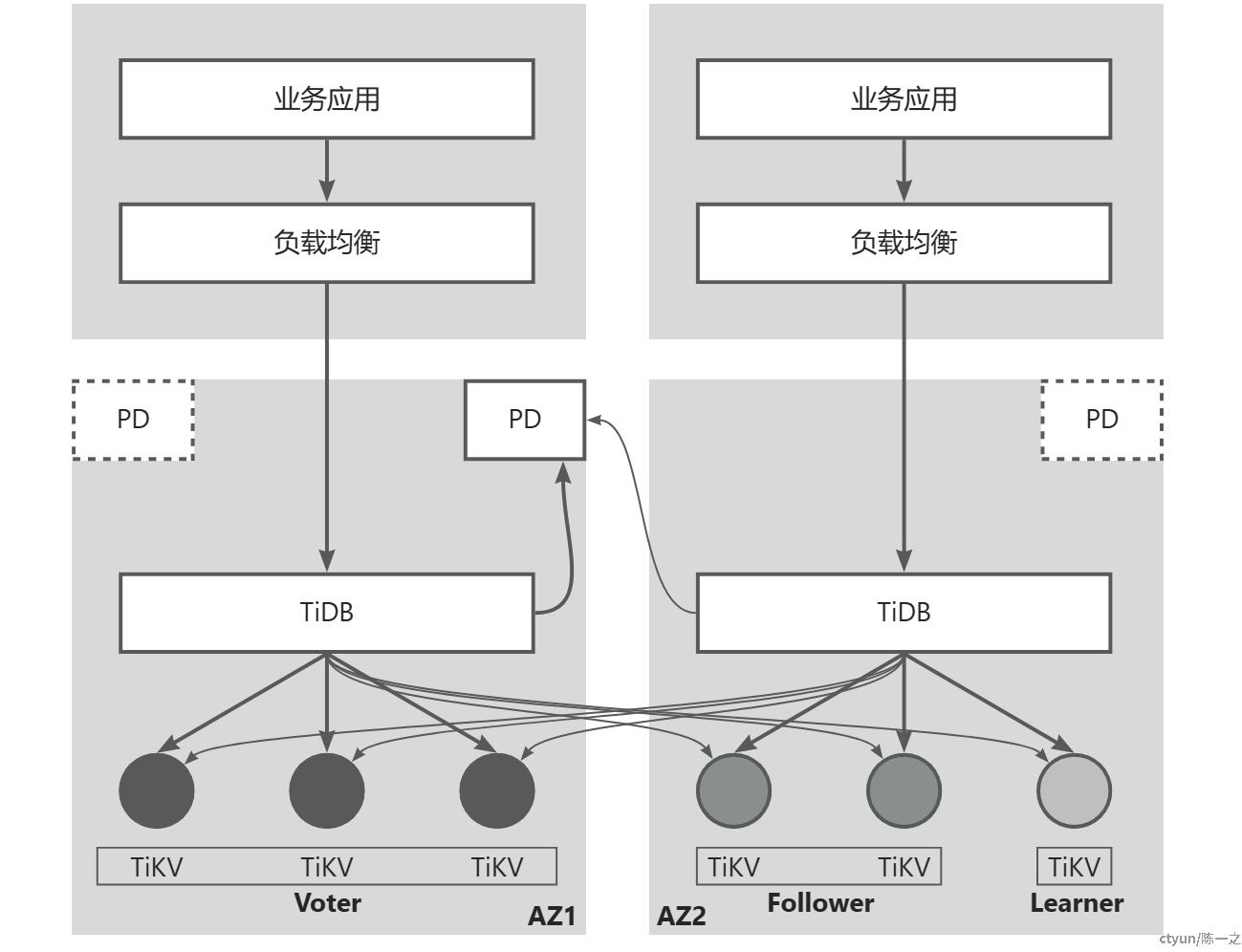
在这个解决方案中,TiDB将Raft集群的角*划分为Voter/Follower/Learner。实际上Voter和Follower都是组成数据集群的节点,是相同节点在不同场景不可角*的体现:
- 在Leader正常工作时,响应Leader请求进行数据同步的叫Follower;
- 当Follower判断与Leader断连,会触发选举,将自己变成Candidate;
- 选举发生后,Follower会变成Voter,为选举进行投票;
- Learner只同步数据,不参与选举,不参与投票。
上图所示架构描述了一个6副本集群,实际参与共识的只有5位成员,即Voter+Follower。同城双活需要指定主中心,主中心分配3个Voter,副中心分配2个Follower和1个Learner,通过调度策略限制Leader只在主中心产生。最少数量来说,4个副本(2个Voter+1个Follower+1个Learner)也能达到相同效果,容灾粒度不同。
正常情况下,主中心3副本构成多数集可以快速提交写操作。但这样的话,副中心的数据节点就是异步写入,主中心故障时可能会丢失数据。TiDB增加了Group的概念,可以要求每个分组至少有一个节点提交,将Voter和Follower分别编组,就能实现数据同步写到副中心的至少一个节点。
这种架构可以容忍任意两个数据节点(TiKV)发生故障,副中心的3节点同时故障也不影响系统正常运行,主中心的3节点同时故障则需要对集群进行重配置操作,将Learner加入到集群中构成多数集(3节点)继续提供服务,这也是Learner存在的意义。
相对应的,TiDB的自适应同步定义了三种状态来管理数据同步:
- sync:同步复制。主副中心网络正常,副中心至少有一个节点保持数据同步,保障灾备数据完整性。
- async:异步复制。副中心故障、网络隔离或超时,不保证副中心数据保持同步,主中心多数集正常运行,优先保障可用性。
- sync-recover:恢复同步。节点故障恢复,数量满足同步复制的条件,集群进入恢复的中间状态,数据恢复后切换回同步复制模式。
虽然同城双活看起来是性价比最高的方式,但违背了分布式集群固有的设计,有削足适履的嫌疑,实际隐性成本很高,比如:最少4副本,资源冗余多;状态管理复杂,容灾预期不可控;需要较重的人工干预等等。
逻辑数据模型
TiKV是一个Key-Value的存储引擎,底层依赖的是RocksDB(Facebook基于LevelDB开发的)。
存储单位
TiDB按Key的连续顺序切分数据,每个分段作为数据存储的基本单位,术语叫做Region。
每个Region负责存储一个Key Range[StartKey, EndKey)的数据,每个TiKV节点会负责多个Region。Region也是Raft进行同步的基本单位,一组通过Raft算法分布到多个TiKV实例的多副本Region叫做一个Raft Group。
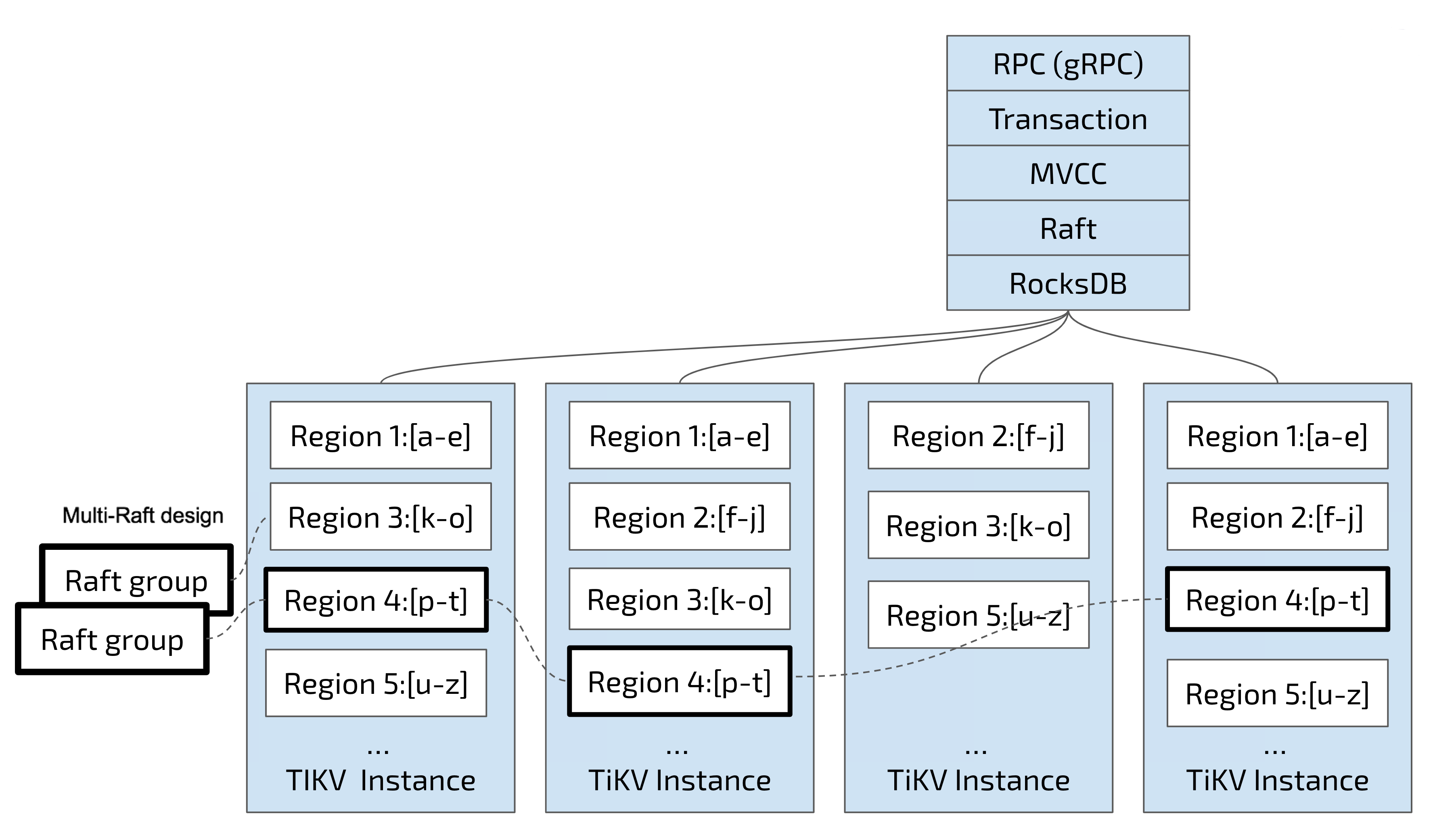
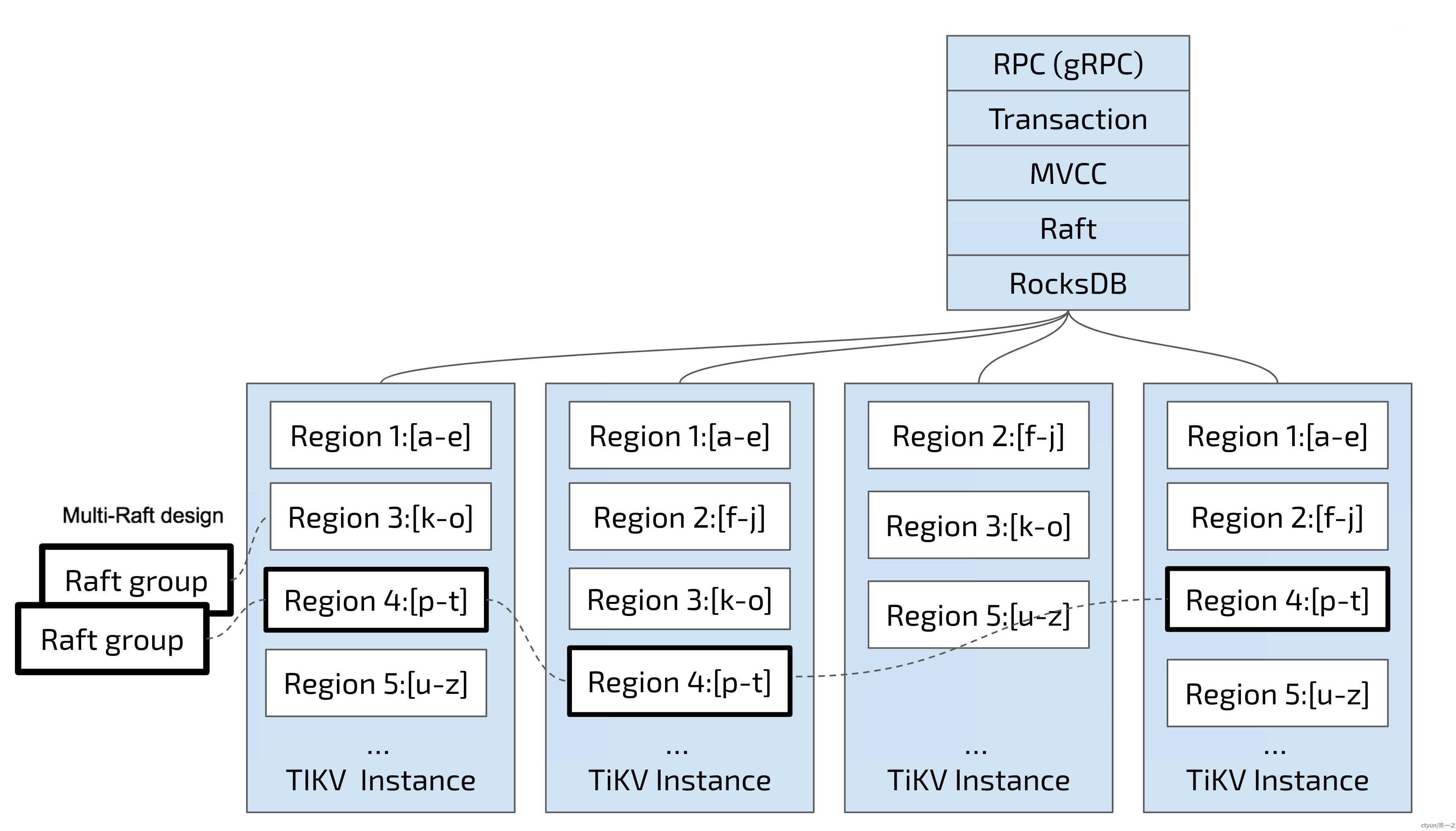
TiDB对Region有自适应调度策略,主要围绕几个方面进行:一是资源利用率,二是Raft分组容灾,三是节点伸缩。所以,Region的Range不是固定的,可能会根据容量拆分合并;Region副本的分布也不是固定的,可能会根据资源情况腾挪迁移。
可以通过调度配置指定某些数据分区的Leader优先落在哪个TiKV实例,这在期望流量尽可能在某个AZ闭环的场景往往很有用,但Region自适应调度隐含了与之相悖的冲突——Region是可分裂、可迁移的,流量路由并不稳定。硬要控制Region不可分裂和不可迁移往往适得其反,即使不考虑资源利用率均衡问题,可用性和性能的优先级也高于预定规则。
最好不要过度干涉TiDB的自适应调度,选择合理的物理区域,尽可能保障网络条件,结合容灾架构,以容灾区域为粒度进行调度配置是更合适的选择。
表映射
TiDB兼容MySQL协议,逻辑上要实现关系模型到K-V模型的映射,主要有表数据映射、表索引映射和MVCC数据映射,锁数据等不展开。
|
对象 |
映射 |
示例 |
|
表数据 |
|
|
|
表索引 |
|
主键索引:
二级索引:
|
|
MVCC |
|
|
从TiDB表映射的设计可以判断:
- 表数据是聚合的,Region按RowID顺序拆分;
- 表数据和表索引的Key前缀不同,同一行的数据和索引可能分布在不同Region;
- 同一行多版本数据是Key后缀拼接,按行拆分Region,同一行的数据在相同Region。
分区表
业务视角的应用数据是关系表,除了基础的单表外,TiDB还支持多种分区表。分区表就是大表的横向拆分,主要有Range分区、Range COLUMNS分区、Range INTERVAL分区、List分区、List COLUMNS分区、Hash分区和 Key分区。
|
类型 |
说明 |
|
Range分区 |
|
|
Range COLUMNS分区 |
|
|
Range INTERVAL分区 |
|
|
List分区 |
|
|
List COLUMNS分区 |
|
|
Hash分区 |
|
|
Key分区 |
|
在多活容灾场景,可以为分区表指定放置策略配合流量调度:例如按UserID哈希分区,p0分区的主节点放在az0、p1分区的主节点放在az1,将p0、p1分区的用户流量分别导向az0、az1。
从前面的讨论可以知道,TiDB对这样的放置策略只是最大努力(Best-Effort),不是严格保证,放置策略的生效速度也跟集群所处的环境和资源使用情况有关,不是即时的过程,作为部署架构锦上添花的优化可能合适,严格进行数据流量拆分明显不足。
