


根据图片1展示的FPGA内部架构,网络数据报文的GSO(Generic Segmentation Offload)处理流程应用可分为以下步骤:
1. 数据报文输入阶段
• Host/SOC侧输入
数据报文通过PCIe接口从两个方向进入FPGA:Host侧和SOC侧均通过上方pcie_subsystem接入。两个子系统分别完成PCIe协议的解包和DMA传输,将数据传递至对应virtio_subsystem。
• VirtIO虚拟化处理
virtio_subsystem对报文进行虚拟化设备层处理(如队列管理、前后端通信),确保数据格式符合后续模块要求。
2. 数据聚合与路由(MUX)
两个virtio_subsystem的输出通过MUX模块进行聚合,可能根据优先级或负载均衡策略选择输入源,统一输出到gso_subsystem。
3. GSO核心处理(gso_subsystem)
• 分片卸载(Segmentation Offload)
gso_subsystem(粉色模块)是核心处理单元,如图2是GSOH模块的核心处理;负责将大报文分片:根据MTU(如以太网1500字节)将超大TCP/UDP报文拆分为多个小报文,降低CPU负载。
如图3,数据通道位宽为64字节。绿色template_header为最大支持报文长度,为64字节整数倍;header为真实报文头长度,不一定是64字节整数倍;使用模板header承载真实header +切片后payload,然通过挤“气泡”的方式将无效字节去掉,该种方式避免了大量数据移位带来的逻辑开销;
• 协议头处理:保留原始报文头信息,仅对负载分片并生成新头(如TCP序列号调整)。
• 校验和计算:预计算分片后的校验和,减少后续处理开销。
4. 虚拟交换与输出(ovs_subsystem)
分片后的报文进入ovs_subsystem(虚拟交换机),根据流表规则(如MAC/IP/端口)路由到目标以太网接口。
5. 物理层输出
报文最终通过选定的以太网接口(如eth1)发送至外部网络设备,完成GSO全流程。
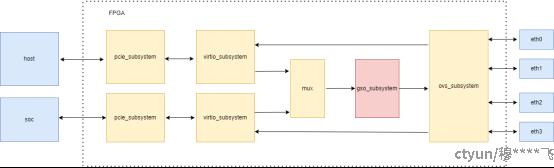
图1 DPU处理的流程框图

图2 GSO内部处理图
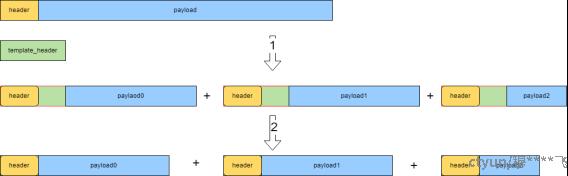
图3 报文内部分包过程
该方法优点:
1.不存整包,随路切片,减少整包缓存带来的延迟;
2.支持bypass通路,不切片的报文,直接通过延迟更小;
3.支持多种协议以及自定义协议;可以支持RDMA的多种自定义报文头;
与传统软件切包的对比:本方案具有延迟小、协议扩展性强以及性能提升明显等优势。
|
对比 |
传统GSO(软件/网卡) |
当前设计(FPGA GSO) |
|
处理位置 |
主机CPU或网卡固定逻辑 |
FPGA可编程流水线 |
|
协议灵活性 |
仅支持标准协议(如TCP) |
可配置分片规则(支持私有协议) |
|
延迟优化 |
依赖CPU调度(微秒级) |
硬件并行(纳秒级) |
