


关键词: DDR 、bank复制、双倍速率同步动态随机存储器;
1. DDR基本概念
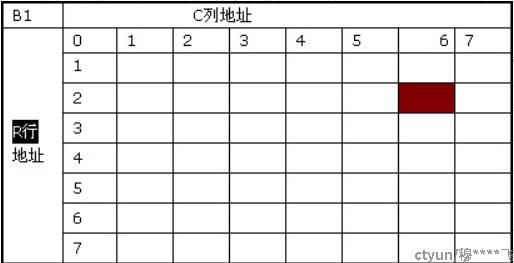
DDR SDRAM的内部是一个存储阵列,每个bank类似一张表格,寻址时先执行每个SDRAM内包含若干个Bank,从DDR4开始增加了Bank Group的概念,两个bank如果处于不同的BG,其切换速度会比相同BG下要快一些;DDR的示意图如下:
接口调用时满足2个基本原则:
- 相同bank的不同row,不可以同时打开;只允许同时打开1个row
- 不同bank之间可以同时打开多个row(哪怕row号一样也可以)
2. 常见DDR时序参数
Bank地址与相应的行地址是同时发出的,此时这个命令称之为“行激活”(Row Active)。在此之后,将发送列地址寻址命令与具体的操作命令(是读还是写),这两个命令也是同时发出的,所以一般都会以“读/写命令”来表示列寻址;
tRCD:即RAS to CAS Delay(RAS至CAS延迟,RAS就是行地址选通脉冲,CAS就是列地址选通脉冲):从行有效到读/写命令发出之间的间隔。

CL(CAS Latency,列地址脉冲选通潜伏期):相关的列地址被选中之后,将会触发数据传输,但从存储单元中输出到真正出现在内存芯片的 I/O 接口之间还需要一定的时间(数据触发本身就有延迟,而且还需要进行信号放大);
背景:目前内存的读写基本都是连续的,因为与CPU交换的数据量以一个Cache Line(即CPU内Cache的存储单位)的容量为准,一般为64字节。而现有的Rank位宽为8字节(64bit),那么就要一次连续传输8次,这就涉及到我们也经常能遇到的突发传输的概念。
突发长度(Burst Lengths,简称BL)
突发(Burst)是指在同一行中相邻的存储单元连续进行数据传输的方式,连续传输的周期数就是突发长度。
在进行突发传输时,只要指定起始列地址与突发长度,内存就会依次地自动对后面相应数量的存储单元进行读/写操作而不再需要控制器连续地提供列地址。这样,除了第一笔数据的传输需要若干个周期(主要是之前的延迟,一般的是tRCD+CL)外,其后每个数据只需一个周期的即可获得。

突发连续读取模式:只要指定起始列地址与突发长度,后续的寻址与数据的读取自动进行,而只要控制好两段突发读取命令的间隔周期(与BL相同)即可做到连续的突发传输。
突发中,如果部分数据不要,可采用数据掩码(Data I/O Mask,简称DQM)技术屏蔽掉;这里需要强调的是,在读取时,被屏蔽的数据仍然会从存储体传出,只是在“掩码逻辑单元”处被屏蔽。
tRP(Row Precharge command Period,行预充电有效周期),单位也是时钟周期数。 :从开始关闭现有的工作行,到可以打开新的工作行之间的间隔。在数据读取完之后,为了腾出读出放大器以供同一Bank内其他行的寻址并传输数据,内存芯片将进行预充电的操作来关闭当前工作行。还是以上面那个Bank示意图为例。当前寻址的存储单元是B1、R2、C6。如果接下来的寻址命令是B1、R2、C4,则不用预充电,因为读出放大器正在为这一行服务。但如果地址命令是B1、R4、C4,由于是同一Bank的不同行,那么就必须要先把R2关闭,才能对R4寻址。
3. DDR控制器结构

(1)控制器单元:包括输入命令解析,模式配置&控制部分;
(2)行地址选通单元:行激活通过此处操作;
(3)Bank控制逻辑:行/列地址解码用到bank选通
(4)列地址选择单元,读写操作同时在打开列地址的时候送到1;
(5)内部存储阵列,此处分8个bank,已4g8bit的颗粒为例;每个 bank分65536行,128列,每个cell存储8*bl的数据宽度;
(6)读写数据缓存及接口驱动;dq数据在此变换位宽后内外交互;
(7)锁存与控制逻辑:刷新与预充电用到该模块。
上图为X8data的单颗DDR3架构图,行(Row)地址线复用14根,列(Column)地址线复用10根,Bank数量为8个,IO Buffer 通过8组数位线(DQ0-DQ7)来完成对外的通信,故此单颗DDR3芯片的容量为2的14次方乘2的10次方乘8乘8,结果为1Gbit,因为1B包含8bit,1GB/8=128MB。如果我们要做成容量为1GB的内存条则需要8颗这样的DDR3内存芯片,每颗芯片含8根数位线(DQ0-DQ7)则总数宽为64bit,这样正好用了一个Rank。
4. DDR状态流程
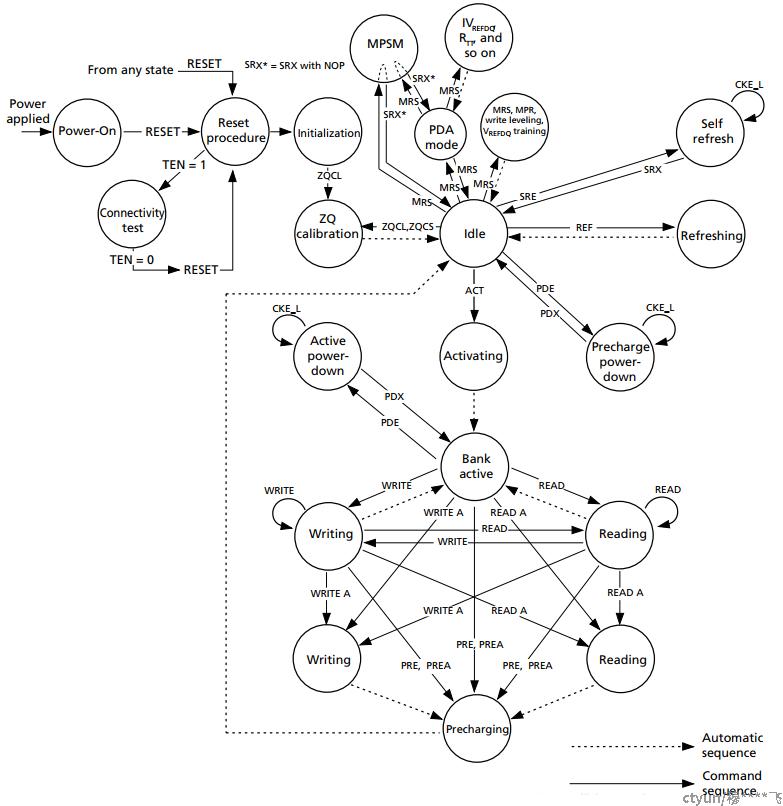
ZQCL: 上电初始化后,用完成校准ZQ电阻。
ZQCS: 周期性的校准,能够跟随电压和温度的变化而变化。
Al:Additive latency是用来在总线上保持命令或者数据的有效时间。
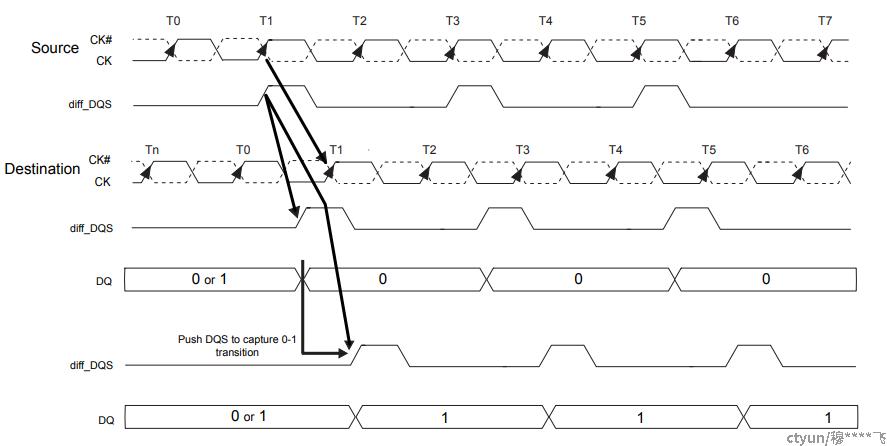
write leveling:来允许控制器来补偿倾斜(flight time skew)。存储器控制器能够用该特性和从DDR3反馈的数据调成DQS和CK之间的关系。在这种调整中,存储器控制器可以对DQS信号可调整的延时,来与时钟信号的上升边沿对齐。控制器不停对DQS进行延时,直到发现从0到1之间的跳变出现,然后DQS的延时通过这样的方式被建立起来了,由此可以保证tDQSS。
MRS: MODE Register Set, 模式寄存器设置。为了应用的灵活性,不同的功能、特征和模式等在四个在DDR3芯片上的Mode Register中,通过编程来实现。模式寄存器MR没有缺省值,因此模式寄存器MR必须在上电或者复位后被完全初始化。
工作原理
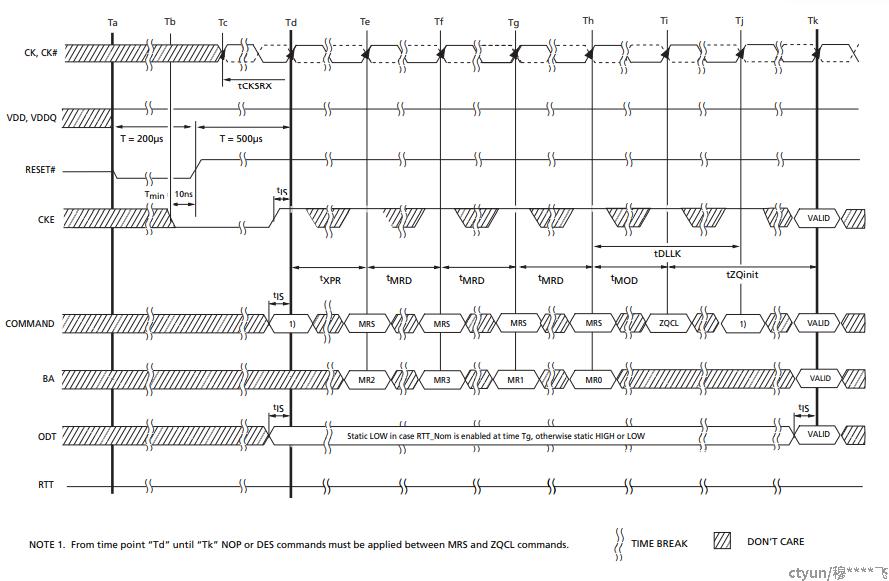
在描述了上述的一些基本概念后,就可以对图中的DDR3工作原理进行基本的描述了理解了。
首先,芯片进入上电,在上电最小为200us的平稳电平后,等待500usCKE使能,
在这段时间芯片内部开始状态初始化,该过程与外部时钟无关。在时钟使能信号前(cke),
必须保持最小10ns或者5个时钟周期,除此之外,还需要一个NOP命令或者Deselect命令出现在CKE的前面。
然后DDR3开始了ODT的过程,在复位和CKE有效之前,ODT始终为高阻。
在CKE为高后,等待tXPR(最小复位CKE时间),然后开始从MRS中读取模式寄存器。
然后加载MR2、MR3的寄存器,来配置应用设置;然后使能DLL,并且对DLL复位。
接着便是启动ZQCL命令,来开始ZQ校准过程。等待校准结束后,DDR3就进入了可以正常操作的状态。对于基本的配置过程,现在就可以结束了。
5. DDR物理规格
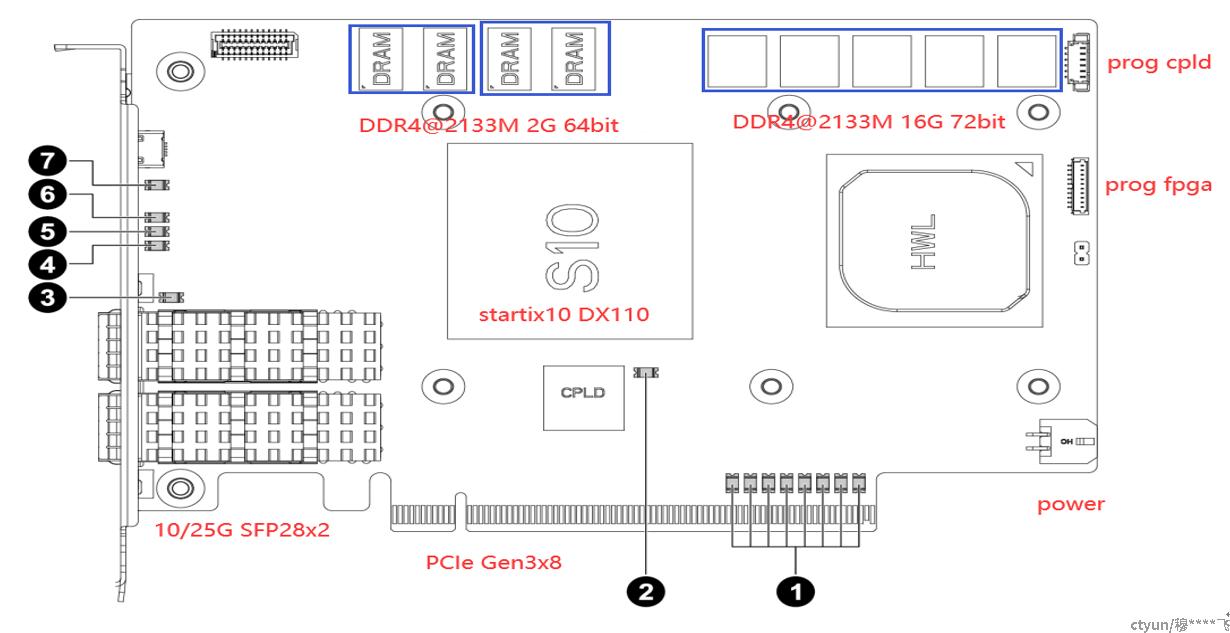
如下图所示目前FPGA使用的2个channel的DDR4,每个channel由4颗DDR4颗粒组成,位宽为64bit,容量2G Byte,主频可达到2133M,从资料照片来看用的是micron的颗粒:从micron官网可以查到符合条件的只有以下型号颗粒

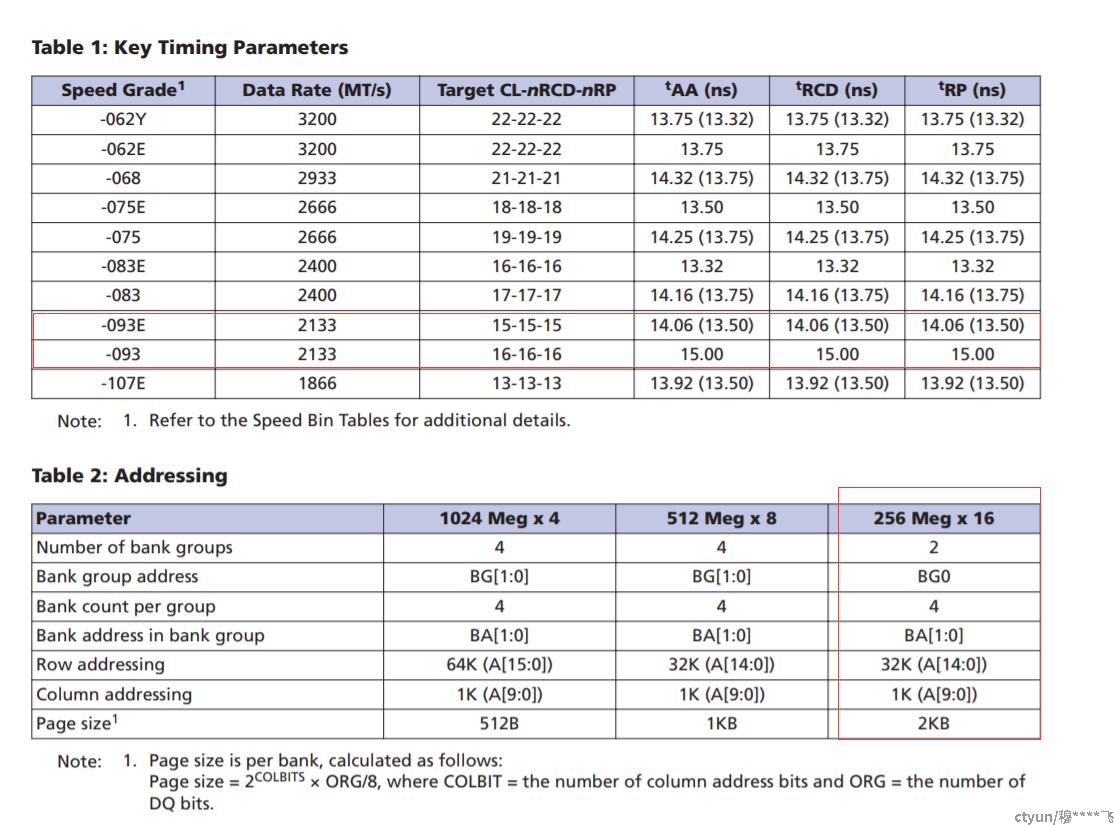

下面按照MT40A256M16GE-093E的DDR4颗粒状态列举其关键参数:
|
channel数 |
2 |
channel1:精确查表用 channel2: CT+统计表 |
|
channel容量 |
2G Bytes |
单channel |
|
channel 位宽 |
64 |
总数据位宽64 |
|
channel 颗粒数 |
4 |
由4颗16bit DDR4颗粒组成:MT40A256M16GE-093E |
|
DDR4颗粒主频 |
2133M |
时钟频率=1066M |
|
DDR4颗粒规则 |
2Gbit |
=256M*16bit ---28bit |
|
BANK GROUP(BG) |
2 |
2个bank group ---1bit |
|
BANK 数 |
4 |
4bank/BG ---2bit |
|
Row数 |
32K |
32K ---15bit |
|
Colum数 |
1K |
1Kx16 ---10bit |
|
Page Size |
2K |
2Kx8 |
|
CL (tCAS) |
15 clocks |
Read指令到数据输出延时 |
|
tRCD |
15 clocks |
Row Active到Read指令延、>14.06ns |
|
tRP |
15 clocks |
row prechage到下一个row active时间,>14.06ns 对不同的bank可以交错执行row active, 以上描述仅针对同一个bank内的不同row的交替打开 |
|
tRAS |
36 clocks |
Row Active到prechage时间 >33ns |
|
tRFC |
260 ns |
执行一次refresh所需要的时间 |
|
tREFI |
7.8 us |
平均refresh周期 |
|
tRRD_S |
6 clocks |
不同bank group之间最小的row active 间隔 |
|
tRRD_L |
7 clocks |
相同bank group之间最小的row active 间隔 |
|
tCCD_S |
4 clocks |
不同bank group之间最小的read指令间隔 |
|
tCCD_L |
6 clocks |
相同bank group之间最小的read指令间隔 |
|
tFAW |
32 clocks |
最多同时打开4个bank的时间间隔, 30ns |
6. DDR空间规划与使用
|
channel 0 ping-pong PHY模式 |
DDR4颗粒1+2 |
Hash表 (<512bit) |
|
|
DDR4颗粒3+4 |
key 表(1024bit) |
1M 条(复制8份) |
|
|
channel 1 ping-pong PHY模式 |
DDR4颗粒1+2 |
CT+统计表 (未知) |
|
|
DDR4颗粒3+4 |
空闲 |
其中channel0的表项分布如下,8个bank内容是一样的

7. 高效使用DDR
- ping-pong PHY 模式
如下图所示,2颗DDR4颗粒在ping-pong模式下等效为2组独立的DDR channel,
1组用于查找hash表,1组查找key表;
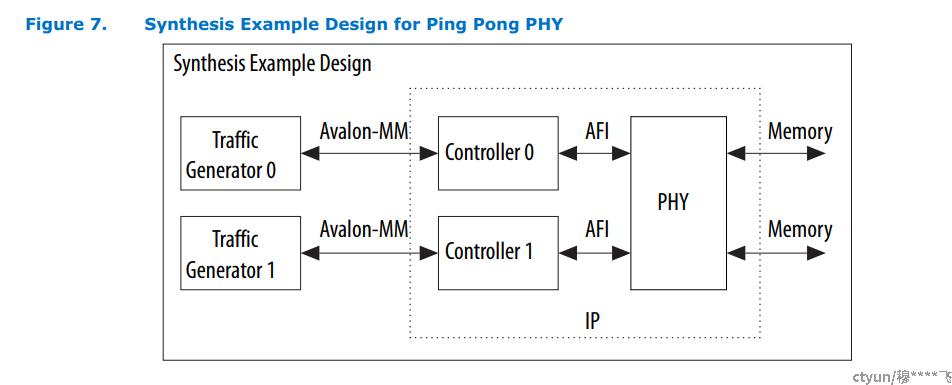
- hash表和key表复制到8个bank,尽可能利用bank interleave访问
- hash表=512bit=2次burst 8(每次8*32)
- key表=1024bit=4次burst 8 (每次8*32)
- Additive Latency +Bank Interleaving+Auto-Precharge
- 可能的时序图
相邻的2次burst采用back-to-back的访问方式,占用8个clock
然后切换到下一个bank,tRRD最大是7clock,这样就可以流水起来
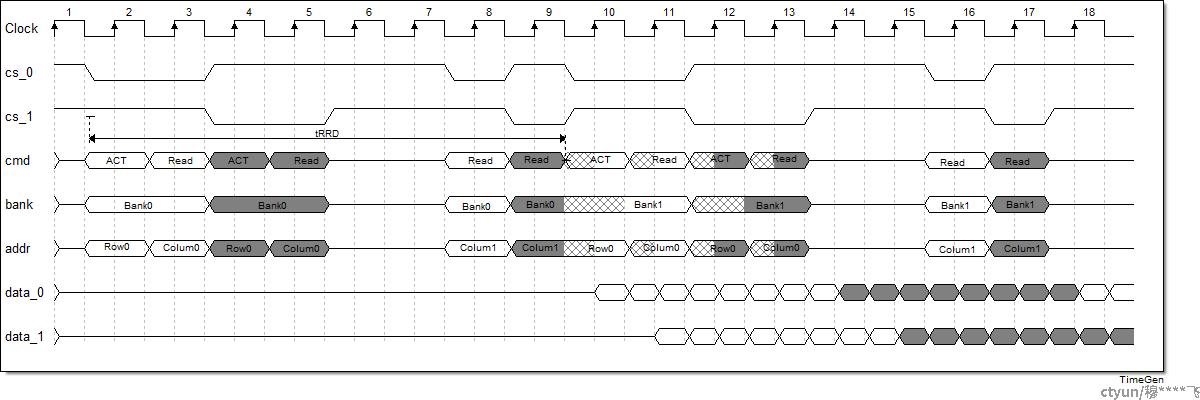
|
说明 |
用途 |
位宽 |
换算成clock |
97%利用率 |
|
ping部分 |
hash表 |
512bit |
=16*32bit =8clock |
1066M/8= 125M pps |
|
pong部分 |
key表 |
1024bit |
=32*32bit =16clock |
1066M/16= 64M pps |
