


AI Coding的困境
AI 编码助手已经成为了很多开发者的标配工具。你能够通过人类语言告诉它你想要什么,它就能给你一个可运行的成品,感觉效率拉满!
但 AI 给出的代码真的是你想要的吗?
答案却是: That depends! (看情况)
- “帮我实现一个网页版象棋游戏”, 这类任务AI通常能够很好的执行, 因为它足够独立。
- “后端API访问需要添加鉴权管理,每一个API都需要和用户角色关联,确保用户角色取得访问权限后才可以执行”,然后它给我重构了半个项目:添加了新的数据表,实现新接口和鉴权逻辑。 而这些原本是存在的,仅需要补充字段,添加关联映射即可。
- “之前网页通知模式采用js 的websocket存在连接不稳定情况,请撤销重做,并修改为基于后端请求的轮询模式",然后它重新实现了一套基于轮询的通知机制,并且之前ws 模式下的代码依然遗留在系统中,调用的API也为完全切换。
- ...
以上种种,您是否似曾相识?
问题不在于 AI 不够聪明,而在于 AI 的记忆是会话级别的(Seesion/Context)。
你今天在 Cursor 里讲好的架构决策,明天新开一个对话它全不记得了;你在聊天框里给 AI 讲了二十分钟的上下文,它在第 21 条消息时就开始"忘事";事先约定了很多细节,在上下文压缩时已经 被 summary 了。
更要命的是:当你的需求稍微复杂一点——比如同时涉及数据库 Schema 变更、接口改动和前端组件重构——AI 在没有明确规格约束的情况下,很可能:
过度实现:你要的是加个按钮,它给你重构了整个状态管理
欠拟合:你要的是完整功能,它给你实现了一半然后说"其余你自己补吧"
需求漂移:做到第三步发现已经偏离原始设计十万八千里
这就是开发者们熟悉的"AI 乱猜" 或 “AI幻觉” 状态。
总结而言,传统AI coding 最大的困境是: 因contex上下文限制,而呈现出来的记忆缺失 和过程不可预期!
这些问题的原因,我们在上一章中,已经讨论过了。
传统解法
当然,有经验的开发者会说:把需求写清楚嘛!在 prompt 里把上下文交代清楚!用agent.md readme.md 记录
确实,这能缓解问题,但不能根治。因为:
- Context 是一次性的:写在聊天框里的需求,换个会话就消失了
- 同步成本高:团队协作时,每个人告诉 AI 的上下文不一致
- 不可追溯:代码里看不出当初做这个决策的理由是什么
- 难以复查:没有结构化的"变更说明",代码评审只能靠猜
SDD新思路
规格驱动开发(Spec-Driven Development, SDD) 是一种以规范文档为核心的软件工程方法论:主张"规范先行,代码自动",将规格说明作为人、团队与 AI 之间的动态契约和唯一事实来源。把" 我们要做什么、为什么做、怎么做"写成结构化的 Markdown 文件,和代码一起存进 Git 仓库。AI 助手不再依赖你在聊天框里的临时描述,而是从仓库里读取持久化的规格文档,然后照单执行。
而 OpenSpec,就是把 SDD 落地的那把利器。
OpenSpec 介绍
OpenSpec 是一个轻量级、开源的规格驱动开发框架,通过结构化的 Markdown 文件帮助人类和 AI 编码助手在写代码之前就达成一致。
它本质上是一套工作流规范 + CLI 工具,让你的 AI 助手能够:
- 读懂你真正想要什么(proposal.md)
- 理解具体的需求约束(specs/)
- 知道技术怎么实现(design.md)
- 按步骤系统地执行(tasks.md)
整套文档住在你的项目仓库里,持久存在,永不遗忘。
核心概念速览
在深入使用方法之前,先认识几个关键词,别让它们在后面绊倒你:
| 术语 | 描述 |
|---|---|
| Change(变更) | 一个独立的功能开发或修改任务,是 OpenSpec 的最小工作单元 |
| proposal.md | "我们为什么要做这件事,做什么,不做什么"的说明书 |
| specs/ | 具体需求场景,用 Given/When/Then 格式写清楚验收条件 |
| design.md | 技术方案文档,怎么做,用什么技术,关键决策是什么 |
| tasks.md | AI 实现时的步骤清单,打勾制度,做一步标一步 |
| AGENTS.md | 给 AI 助手看的项目级说明书,告诉它这个项目怎么运转 |
| Fast-Forward(ff) | 一键生成全套规划文档的快捷操作,懒人必备 |
| Archive(归档) | 变更完成后,将变更文件夹归档,并将规格合并到主文档 |
OpenSpec 的文件夹结构
初始化后,你的项目会多出这样的目录:
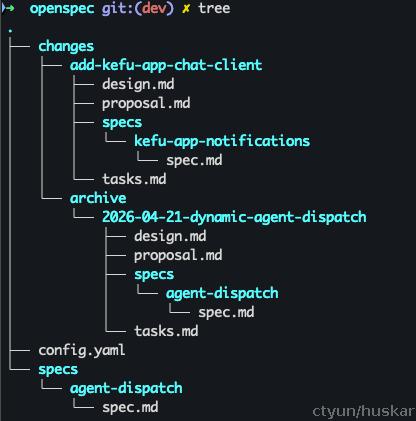
其中:
changes: 就是你的进行中队列,一目了然看到有哪些功能在开发(任务专注);
archive: 是历史记录;
specs: 是反映当前系统真实状态的活文档——每次 archive 操作都会自动把变更同步进来(工程级记忆的关键)。
OpenSpec 的核心四阶段工作流
step 1: 需求探索(Explore)
产品功能描述 转化为 需求规格的关键。通过多轮次的对话,将需求目标、范围、边界进行定义和决策,技术方案选型,细节对齐。
step 2: 定义变更 (Propose)
将需求定义为一个独立的变更,并形成提案(proposal.md);
基于提案,梳理规格,形成规格说明(spec.md);
基于规格说明,进行方案设计,形成设计说明(design.md)
基于设计说明,进行任务拆解,形成任务计划(tasks.md)
step 3: 实施(Apply)
该步骤时AI真正执行实施的过程, 按照tasks.md 逐条实现,并进行确认,每完成一条对该条目进行打钩。包含部分测试验证条目。
注意,部分条目需要人工进行验证(比如涉及到生产环境上的一些验证)。
所有tasks完成后,本任务完成。
step 4: 归档(archive)
当所有tasks均完成后, 该任务完成。
注意,这一步最后人工验收(编译、构建、安装、关键功能验证等)。
验收通过后, 对当前变更进行归档:将 changes 内容移动到archive 中,同时合并到主specs中。
后续的变更,可以参考主specs中的记录,让AI理清整个项目的演化(全局记忆), 编译前后关联。
为什么要分四阶段?
因为这四个阶段对应着四种种不同的思维模式:
- 探索阶段: 是"发散思维",核心是想清楚要做什么,允许反复推敲
- 规划阶段: 是"正规化",核心是确认方案和边界,是需求 转换为实现 的关键映射
- 实现阶段: 是"收敛执行",核心是严格按照规格,保障计划任务完成,不做规格之外的事
- 归档阶段: 是"沉淀知识",核心是让完成的工作成为持久的项目知识
OpenCode + penSpec 工程化实践
注意:当前验证是基于linux 环境验证和记录,windows 类似,但需要注意默认配置路径等需要对应调整!
安装
通过npm 直接安装 OpenSpec
# 需要 Node.js 20.19.0 或更高版本
# 安装openspec
npm install -g @fission-ai/openspec@latest
# 验证安装
openspec --version
注意:openspec 本身是一套skill规范,需要搭配AI 编程工具使用(Claude-cli,Codex-cli,opencode,cursor等等),因此openspec 本身并不需要配置大模型!
核心工作流实战演示
这里我们选择opencode。
如果还没有安装、配置opencode, 请参考上一篇 《玩转 AI Coding(二):基于opencode 的AI编程初体验》。
接下来,我将结合一个实际场景:
“为操作系统AI智能组手(ctsh-asst)新增息壤大模型接入能力”
为大家演示OpenCode + OpenSpec 的工程化过程。
开始之前,先对ctsh项目执行 openspec init,初始化工程配置,并指定AI 工具为opencode:
完成后,在当前目录运行opencode,进入交互式终端,进入正题!
step1 需求探索
首先,将我们的需求通过 opencode 内置命令 /opsx-explore (通过openspec init 注入skill实现) 发起需求探索。
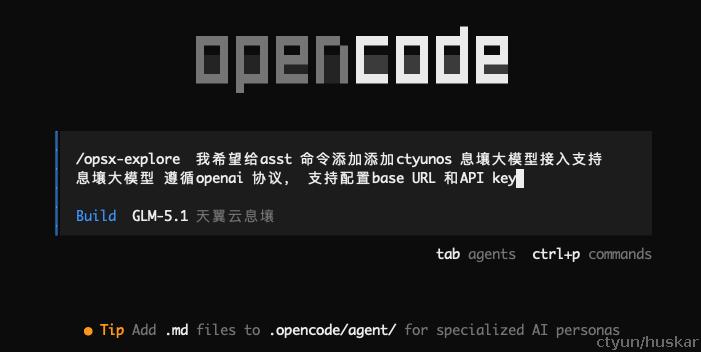
之后opencode 会依据openspec 定义的explore 探索方式,展开对代码的分析和历史spec的检索,以确认方案;过程中,通常会识别到一些不同的实现方式,需要开发人员交互式的进行确认(方案选择、边界确认、需求细化的过程)
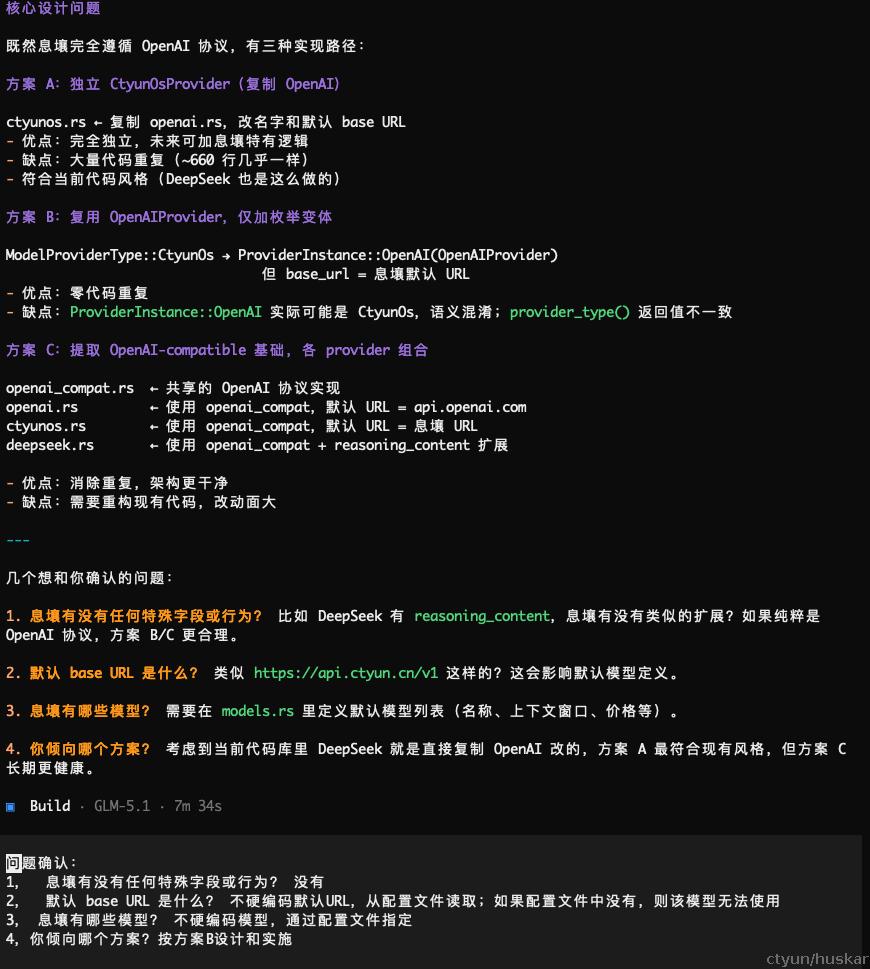
该过程可以持续多轮,直到AI能够明确设计:

step2 创建变更
探索阶段,AI没有修改任何工程文件,它仅是梳理和明确了本次变更的顶层目标、范围、和大体方案。
然后需要通过 /opsx-propose 将需求进行明确、设计,并拆解为可执行的多个任务。
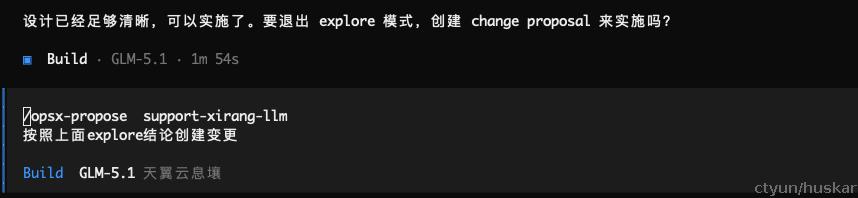
同样,在该过程中,您需要关注proposal.md 文件内容,确保与真实需求是匹配的;也可以与AI进行多轮次对话,确保设计方案与预期相符。
最终, 变更创建完成,并记录到change目录下

注意: 变更名字尽量自命名,并保证 见文知意(类似git 提交的title,一眼就能看出这个变更的大体内容)
step3 执行
仅需要 键入 /opsx-apply, 剩下的事情交给AI!
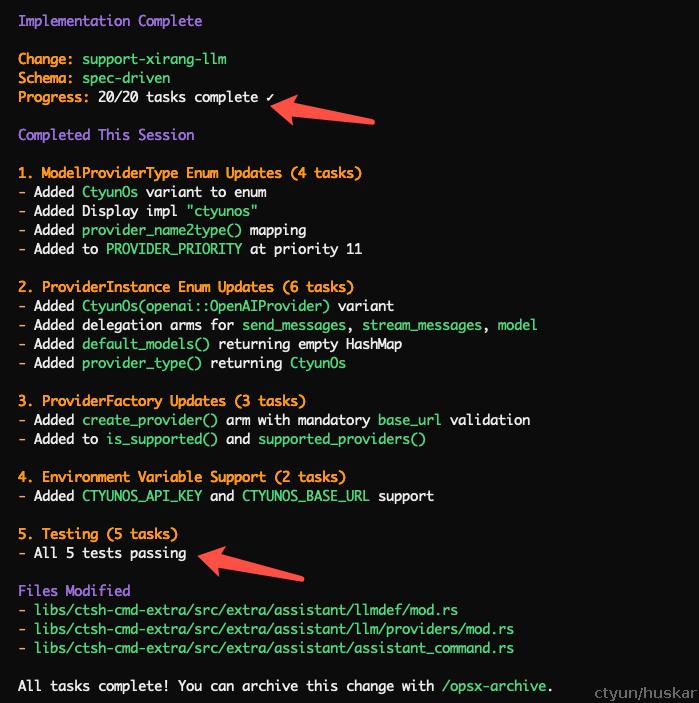
注意,因部分task环境、资源依赖的原因,可能有部分需要人工验证;验证ok后,可以知会AI,task xxx已验证!
另外,人工验收也是必要;过程如果发现问题,让AI迭代修改。
step4 归档
验收完成后,通过 /opsx-archve 归档该任务。
通常,归档完成后,在进行git 提交。
写在最后
openspec 通过预先澄清目标和设计,并以spec规格文档,通过项目级记忆的方式保存了项目的演化过程;当你再提及 “昨天添加的导出功能时”,AI能够通过spec记录找到对应的变更。
因此,openspec赋予了项目完整的演化记忆!
但openspec 每一次闭环局限在一个change中,因此,要求每一个change不能太复杂,必须保证在一个会话过程中能够闭环。
故而,openspec模式适合于项目渐进式迭代开发的过程,而不太适合复杂项目的初始构建。
下一章,我们会介绍另外一个 工程化实践SKILL, superpower: 一个基于流程驱动的开发SKILL。
superpower会带来哪些新东西? 我们下回分解。
