


缘起
一个项目中,一开始使用mysql+gorm的方式开发,上线后,因一些原因需要切换使用postgresql作为业务数据库。切换过程,采用数据库导出、再导入的方式;一切进展似乎很完美,切换后程序正常执行,数据正常展示。
但是,在添加数据时,却出现了错误:
ERROR: duplicate key value violates unique constraint "xxx_pkey" (SQLSTATE 23505)
主键冲突。
可是,添加的数据是从页面提交的,后台组织后插入数据库,过程中压根没有设置主键(ID),而是采用数据库的自增长ID,怎么可能会主键冲突???
排查
1, 通过打印,程序在数据库写入前,原始数据中,确实没有指定ID,确定是使用了数据库的自增长ID;
2, 将程序所执行的SQL语句打印到日志,通过终端连接数据库,执行相关的SQL语句,报同样的错误:
ctadmin=# insert into sys_users ("username","password", "nick_name") values ('test', 'test@passwd.org', 'A5');
ERROR: duplicate key value violates unique constraint "sys_users_pkey"
DETAIL: Key (id)=(1) already exists.注意,这条语句插入时,自动生成的ID是1,确实与数据库现存数据存在ID冲突(该表中,已导入有多条数据,其中包括ID为1的条目)。
联想到该表的数据是通过外部导入的,怀疑是导入过程中,没有触发自动ID 计数刷新,从而导致新增数据条目插入时,自动ID还是按数据库初始化的值进行增长,从而产生与现存数据主键冲突!
但直观上,不应该出现这种问题,按以往使用mysql的经验,设置了自增长ID,当外部插入数据带ID时,数据库表会根据当前插入数据的ID去更新当前自增长ID计数器,从而避免ID冲突的问题。这么日常的问题,postgresql不应该存在问题......
验证
就着开发环境,写了一段验证程序
type TestDbTable struct {
ID uint64 `json:"id" gorm:"primarykey"`
OutIds Uint64Array `json:"out_ids" gorm:"type:text"`
Names StrArray `json:"names" gorm:"type:text"`
}
func TestUint64Array_Scan(t *testing.T) {
if global.GVA_DB == nil {
t.Fatal("database not connected")
return
}
err := global.GVA_DB.AutoMigrate(&TestDbTable{})
if err != nil {
t.Error(err)
}
dt := TestDbTable{
ID: 5,
OutIds: Uint64Array{98, 889, 8889},
Names: StrArray{"tangSan", "Lisi", "Alice Jenson", "Li"},
}
if err = global.GVA_DB.Model(&TestDbTable{}).Create(&dt).Error; err != nil {
t.Error(err)
}
for i := 1; i < 7; i++ {
dtx := TestDbTable{
OutIds: Uint64Array{uint64(i)},
Names: StrArray{fmt.Sprintf("mini-%d", i)},
}
if err = global.GVA_DB.Model(&TestDbTable{}).Create(&dtx).Error; err != nil {
t.Error(err)
}
}
}测试程序很简单:
1, 自动创建一张新表,ID为主键(自动增长);
2, 先向表中插入一条数据,并指定ID 为5;
3, 随后,采用自增长ID的方式,向表中插入6条数据,检测是否出现ID冲突的问题。
[0.523ms] [rows:0] INSERT INTO "test_db_tables" ("out_ids","names") VALUES ('[5]','["mini-5"]') RETURNING "id"
dbtype_test.go:39: ERROR: duplicate key value violates unique constraint "test_db_tables_pkey" (SQLSTATE 23505)遗憾的是,程序未能通过测试。postgresql 并没有像mysql 那样,当自增长ID被带值插入时,自动更新计数到当前最大的记录值。
问题总结
为了进一步了解原因,我在网上搜索了一下该错误,在StackOverflow上找到一篇帖子:
其中被大家认同的回复是:
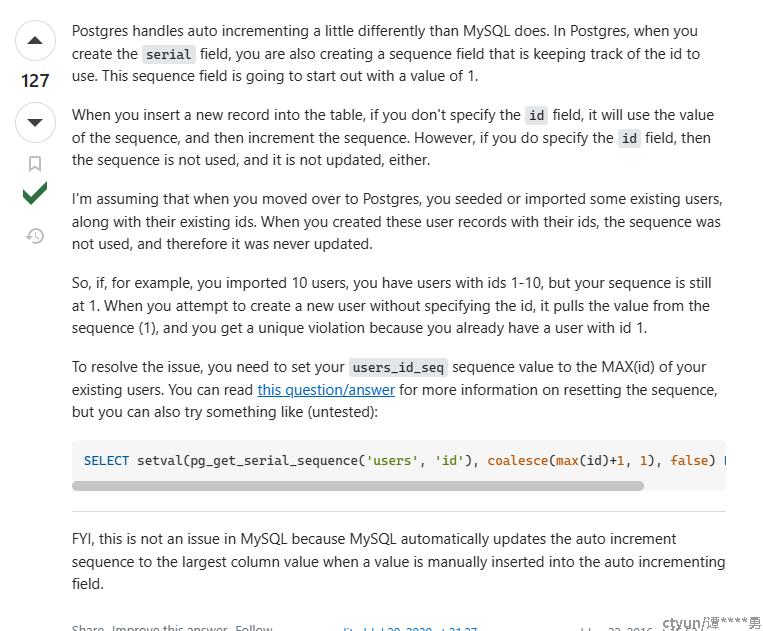
总结而言:
1, postgresql 的自增长ID和mysql实现是有差异的;postgresql通过sequence来记录一个自增长序列。
2, 在数据插入时,如果对应的字段没有赋值,那么postgresql会通过自增长序列动态取值,并同步更新自增长序列计数;相反,如果插入的数据对应字段有值,postgresql不会调用自增长序列获取值,同样也不会更新序列计数。
3, 当进行外部数据导入时,由于外部数据已经携带了ID值,所以导入过程中,并没有更新表的自增长序列;后续,在新数据插入时,采用从自增长序列中自动取值,此时还保持着导入前的计数值,就可能与表里的数据出现冲突!
解决或规避方案
同样,在帖子中也给出了解决方案:那就是手动更新对应自增长序列的计数值。命令如下:
SELECT setval(pg_get_serial_sequence('[your-table-name]', 'id'), coalesce(max(id)+1, 1), false) FROM [your-table-name];
LAST
以上,就是对该问题的跟进过程。
事情就这么点事情,情况就这么个情况!
望路过的诸君,都可以了然,避免掉这个坑里。
另外,为何postgresql 在自增长序列的处理上,不像mysql一样支持动态update(应该也是顺手实现,而且也有必要感觉);这样的设计缘由,笔者还没有找到出处。如果有大佬了解,万望回复指教!
