


Superpowers是什么
在 Superpowers 出现之前,大家使用 Cursor或 Opencode 等 AI 编程工具的方式大多是“对话式编程”。这种方式有个致命伤:不可预测性。表现为:
- AI 经常跳过设计阶段直接写代码。
- AI 写的测试要么没有,要么只是为了应付而写的占位符。
- 随着项目复杂度增加,AI 容易在上下文里迷路,产生大量的“代码垃圾”。
至于原因,我们在第三篇中已经普及过了...
劳苦大众,面对于此,只能死磕提示词,对AI进行三藏式的谆谆教诲; 而资深黑客 Jesse Vincent 在深度使用这些工具后,敏锐的发现:**不是 AI 不行,而是它缺乏一套严谨的工程 SOP(标准作业程序)**。
他把过去几十年人类程序员总结出的“硬核”开发心法,固化成了 AI 必须遵守的指令集。
于是superpower就诞生了!
它的核心目的不是为了“自动化写代码”,而是为了“通过强约束(Guardrails)将 AI 升级为专业的软件工程师”。
核心目标包括:
- 强制工程纪律:AI 天生懒惰(趋向于生成最简单的文本)。Superpowers 强制它执行 TDD(测试驱动开发),如果测试没跑通,AI 甚至被要求删除刚写的代码重新开始。
- 降低认知负担:通过 writing-plans 将复杂的重构任务拆解成 2-5 分钟就能完成的“微任务”。这不仅降低了 AI 的幻觉概率,也让人类更容易 Review。
- 系统化排障:拒绝“试错式 Debug”。它内置了一套基于科学方法的调试协议(Root Cause Tracing),要求 AI 必须先定位根因,再写防御性代码。
- **心理学操纵(有趣的黑科技)**:Jesse 在指令里引入了一些“社会工程学”技巧。例如,他会告诉 AI:“如果你不使用这个技能,就是一个不负责任的开发者。”这种通过身份暗示来提升 AI 输出稳定性的做法,在 Superpowers 里被玩到了极致。
大体的,Superpowers是一个为 AI 编程智能体(Agent)设计的高标准工程流水线。它不是一个简单的工具,而是 一套约束(Guardrails) 和 **技能库(Skills)**,强制 AI 像顶级资深软件架构师一样思考和工作,而不是拿到需求就直接“无脑”写代码。
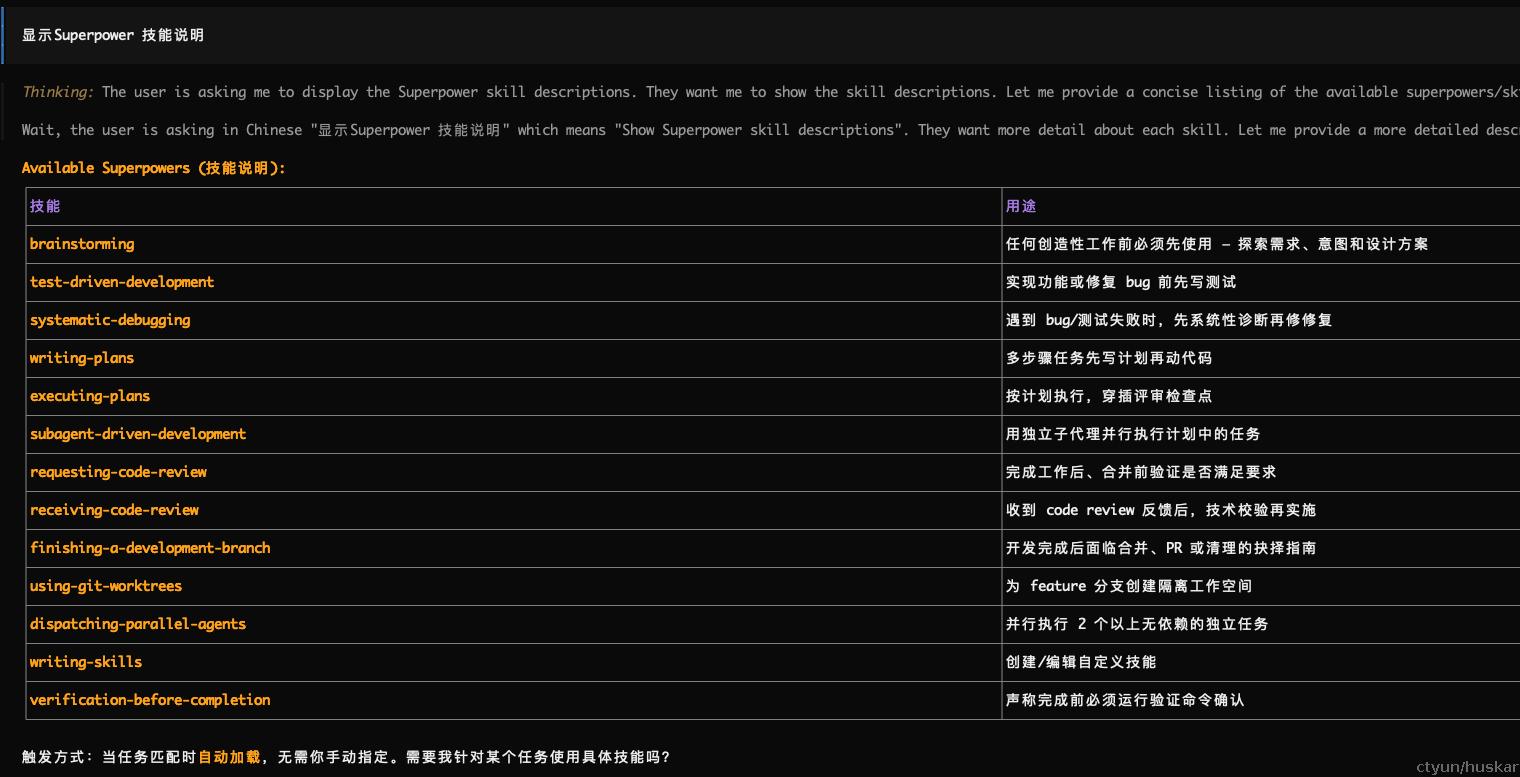
这些Skill包括:
| Skill | 解决的问题 |
|---|---|
using-superpowers |
让 Agent 在每次任务开始前先判断是否有 Skill 适用 |
brainstorming |
在写代码前先澄清目标、约束、方案和边界 |
writing-plans |
把设计拆成可执行、可验证的小任务 |
test-driven-development |
用 RED-GREEN-REFACTOR 约束实现过程 |
systematic-debugging |
遇到 bug 先找根因,不靠猜 |
subagent-driven-development |
让多个子 Agent 按任务执行,并经过规格和代码质量 review |
verification-before-completion |
在声称完成前必须运行验证命令 |
requesting-code-review |
在关键节点主动请求代码审查 |
writing-skills |
把新的经验继续沉淀成 Skill |
这套东西看起来像 AI 版研发流程手册,但它比普通文档更进一步:普通文档是写给人看的,读不读看心情;Skill 是写给 Agent 执行的,触发条件、硬约束、步骤、反模式都写在里面。
换言之,它更像是给 AI 配了一套 项目带教 SOP 。
Superpowers 的核心工作流
Superpowers 官方文档里给出的基础工作流,大体可以理解为七个阶段:
step 1:先 Brainstorming,把问题对清楚
当你说“帮我做一个功能”时,Superpowers 不鼓励 Agent 直接开干,而是先进入 brainstorming。
这个阶段的核心目标,是把问题确认清楚:
- 目标是什么?
- 有哪些可选方案?
- 每种方案都有哪些优点和缺点?
- 每种方案代价是什么?
- 哪些事情明确不做?
- 让程序员补充信息或进行确认...
这一步很像我们做需求评审。
相比于openspec 的 explore , superpower 的 brainstorming 会显得更繁琐、更细致。
不过,这一步对复杂任务很有价值。因为很多 AI 失控,恰恰是因为一开始就把目标定歪了...
so, 千万不要嫌它啰嗦,反而应该更仔细的去分析和审视它给出的目标、可选方案、边界、约束,确保和你期望的一致。
一个标准,AI反馈的内容你都看得懂,且符合预期!
step 2:用 Git Worktree, 隔离开发现场
复杂任务进入实施前,Superpowers 会建议使用 using-git-worktrees 进行工作区隔离:当前主工作区不被打乱,新任务在独立分支、独立目录里推进。
对于人类开发者,这叫“不要在主干上瞎搞”;对于 AI Agent,这叫“给它一块可控施工区域”。
尤其是 AI 会批量改文件、跑命令、生成测试。没有隔离时,多个任务互相污染,很容易出现“我都不知道这些 diff 是谁改的”的情况。
step 3:Writing Plans,把设计拆成可执行任务
对清楚目标了,不代表可以直接开写。
Superpower 使用 writing-plans 把设计继续拆成细粒度任务,确保每个任务明确:
- 要改哪些文件
- 要新增哪些测试
- 每一步怎么做
- 用什么命令验证
- 什么时候提交
经过这一步细化,进一步明确执行计划和细节,确保每一条计划是可清晰可落地的。
计划完成后,Superpower也没有着急开工,而是动停下来,等待你的确认。 当然,你也应该仔细的对所有计划(规格)进行review确认,并对不合理的计划进行修正。
如果在这里选择偷懒,听之任之,那么验收时的痛苦会加倍返还。
step 4:执行计划,可以手工,也可以子 Agent 驱动
进入执行阶段,Superpowers 有两种常见路径:
executing-plans:按计划逐项执行,中间保留人工检查点subagent-driven-development:每个任务派发独立子 Agent,实现后再进行规格审查和代码质量审查
如果平台支持子 Agent,subagent-driven-development 是 Superpowers 很有代表性的能力。
它的思路是:
- 控制者读取完整计划
- 每个任务派发一个新的实现 Agent
- 实现 Agent 只拿到完成该任务需要的上下文
- 实现完成后,先做规格符合性 review
- 再做代码质量 review
- 通过后才进入下一个任务
这很像把一个大任务拆给多个同事做,但每个同事只看自己负责的部分,最后还有 reviewer 把关。
这样做有两个好处:
- 降低上下文污染:每个子 Agent 都是新上下文,不背前面一堆无关聊天记录
- 强化检查点:不是“实现完就算了”,而是要过规格和质量两道门
当然,代价也很明确:更耗 token、更依赖平台的多 Agent 能力,也更适合中大型任务。你让它改一个错别字还开子 Agent 流程,那就像买瓶水还走招投标,场面很正式,但没必要。
step 5:TDD,不要先写实现再补测试
test-driven-development 是 Superpowers 里很硬的一条纪律。
核心流程就是经典的 RED-GREEN-REFACTOR:
- 先写一个失败测试
- 确认它确实失败,而且失败原因正确
- 写最小实现让它通过
- 所有测试变绿后再重构
AI Coding 里 TDD 的价值会被放大。因为 AI 很擅长“看起来实现了”,但不一定真的覆盖了需求。先写测试,相当于先把验收标准钉在地上,再让 AI 去够这个标准。
这里有个重要细节:如果没看见测试先失败,就不能证明这个测试真的测到了问题。
这也是很多 AI 辅助测试最容易糊弄人的地方。它补了一堆测试,全是绿色。看起来很美,但你不知道这些测试是因为功能正确才绿,还是因为根本没测到关键路径。
step 6:系统化 Debug,不靠玄学补丁
遇到 bug 时,Superpowers 会触发 systematic-debugging。
它不鼓励“先试一个修复看看”,而是要求先做根因调查:
- 认真读错误信息和调用栈
- 稳定复现问题
- 检查最近变更
- 在组件边界补充诊断信息
- 找到数据从哪里开始变坏
这听起来慢,但在复杂问题里通常更快。
因为随机修 bug 的时间黑洞大家都懂:第一版修复没用,第二版引入新问题,第三版开始怀疑人生。最后你发现根因是一个配置项写错了。
step 7:完成前必须 Verification
verification-before-completion 解决的是 AI Coding 里最常见、也最危险的句式:
“已完成。”
Superpowers 对这个动作要求讲究求真务实:talk is cheap, show me the 验证证据
什么叫验证证据?
- 跑了测试,并且看到通过结果
- 跑了构建,并且退出码为 0
- 重新触发了原始 bug 场景,并且确认不再复现
- 对照需求清单逐项检查,没有缺口
实战演练
安装Superpower
我们还是以opencode 集成为例。
在opencode中安装Superpower 有两种方式。
自动安装
通过配置文件添加 plugin字段(无则新增,有则追加)
{
"plugin": [
"superpowers@git+仓库地址(obra/superpowers.git,因审核不能给完整路径,自行搜索补充)"
]
}
然后重启opencode。 重启后,opencode 会自动下载、安装、注册所有技能 (这里可能会比较慢,github访问问题)。
重启后,在opencode中输入 /skills 联想skill可以看到相关技能。或者输入指令让opencode显示supperpower相关skill 说明:
手动安装
手动克隆仓库(如果github无法访问,可以使用gitee等代理仓库)
mkdir -p ~/.config/opencode/superpowers
git clone 仓库地址(同上) ~/.config/opencode/superpowers
为opencode 创建插件和技能目录
mkdir -p ~/.config/opencode/plugins ~/.config/opencode/skills
将supperpower 相关的技能链接到opencode 的技能目录下
# 插件链接
ln -s ~/.config/opencode/superpowers/.opencode/plugins/superpowers.js ~/.config/opencode/plugins/superpowers.js
# 技能目录链接
ln -s ~/.config/opencode/superpowers/skills ~/.config/opencode/skills/superpowers
重启opencode,输入 /skills 联想skill可以看到相关技能。
后续,如果有技能更新, 在~/.config/opencode/superpowers 目录下执行git pull命令即可更新。
使用Superpower
一个真实的项目需求: 可信源服务,支持通过大模型分析开源License文本,并分析许可证条款,给出许可证类型(左权,弱左权,宽松等),并可以分析多个许可证条款,判定组合许可的兼容性;一个新需求是,将这部分功能从项目中剥离出来,封装成一个独立的工具,方便用户线下使用。
step1:提示词组织
这一步是我们需要花时间自行分析和组织的,为整个任务开展奠定基础。
该需求的核心是,将现有功能从项目中分离出来成为独立的子模块(工具),因此功能实现不是重点(已实现),重点在于切割边界,和配置方式(原配置方式用了可信源服务的系统配置)。
于是总结如下任务提示词:
当前,relrepo项目中,集成了基于AI大模型的开源License 分析能力,包括License 文本翻译,License条款分析,License兼容性分析;核心实现在 @server/modules/license/service/aitool.go 以及 同目录下的ai_xxx.go 文件中。
现在,需要将这部分功能复制出来,形成一个独立的工具 lcstool, 方便用户脱离平台使用。
子工程放置在 @server/tools/lcstool下,用golang 开发,注意保持跨平台适配性(macos,linux,windows)。
该工具支持默认在用户配置目录生成和读取配置文件(包括大模型 地址、模型、API_KEY等)。
step2: 开始 brainstorming
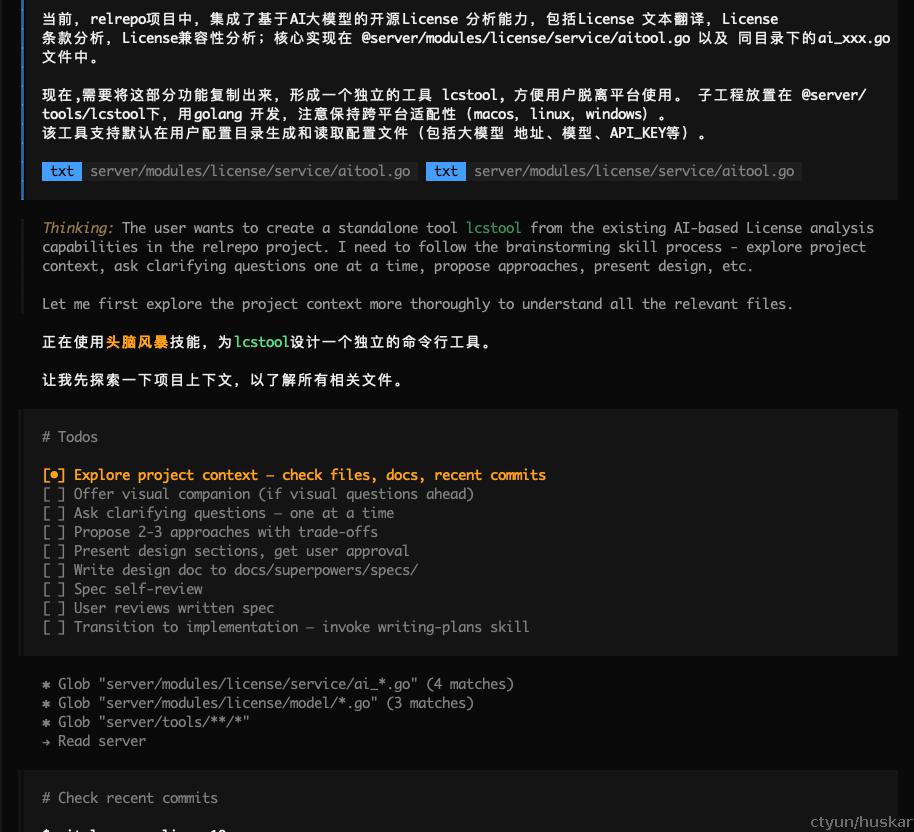
opencode 调用Superpower 的brandstorming skill进行工程上下分析,了解整个项目的结构,和关键内容,然后开始需求确认和拆分。
然后,进入交互式需求(范围、方案)确认环境:
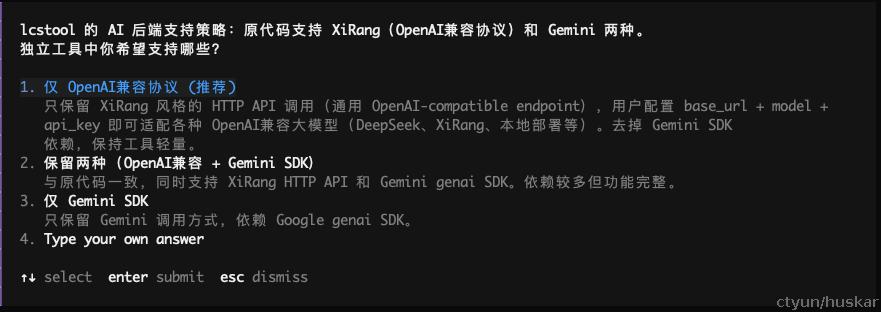
该过程会进行多轮,直到所有问题均已澄清:
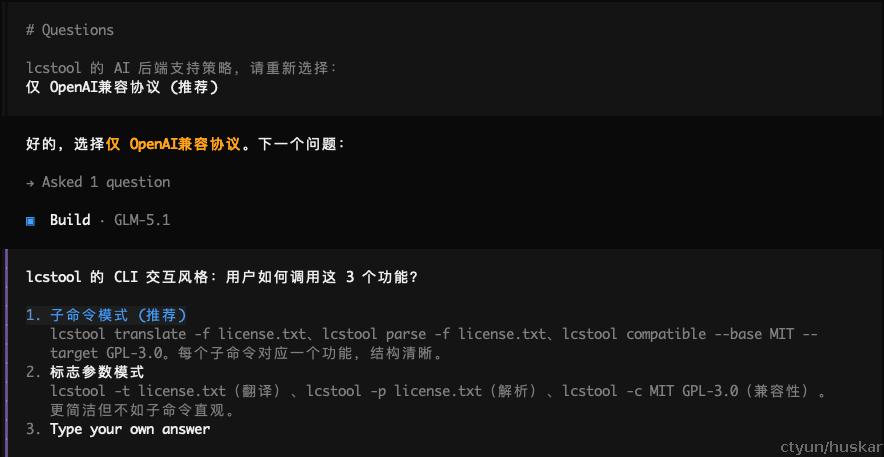
最后,待所有问题澄清后,会进行初步方案设计:
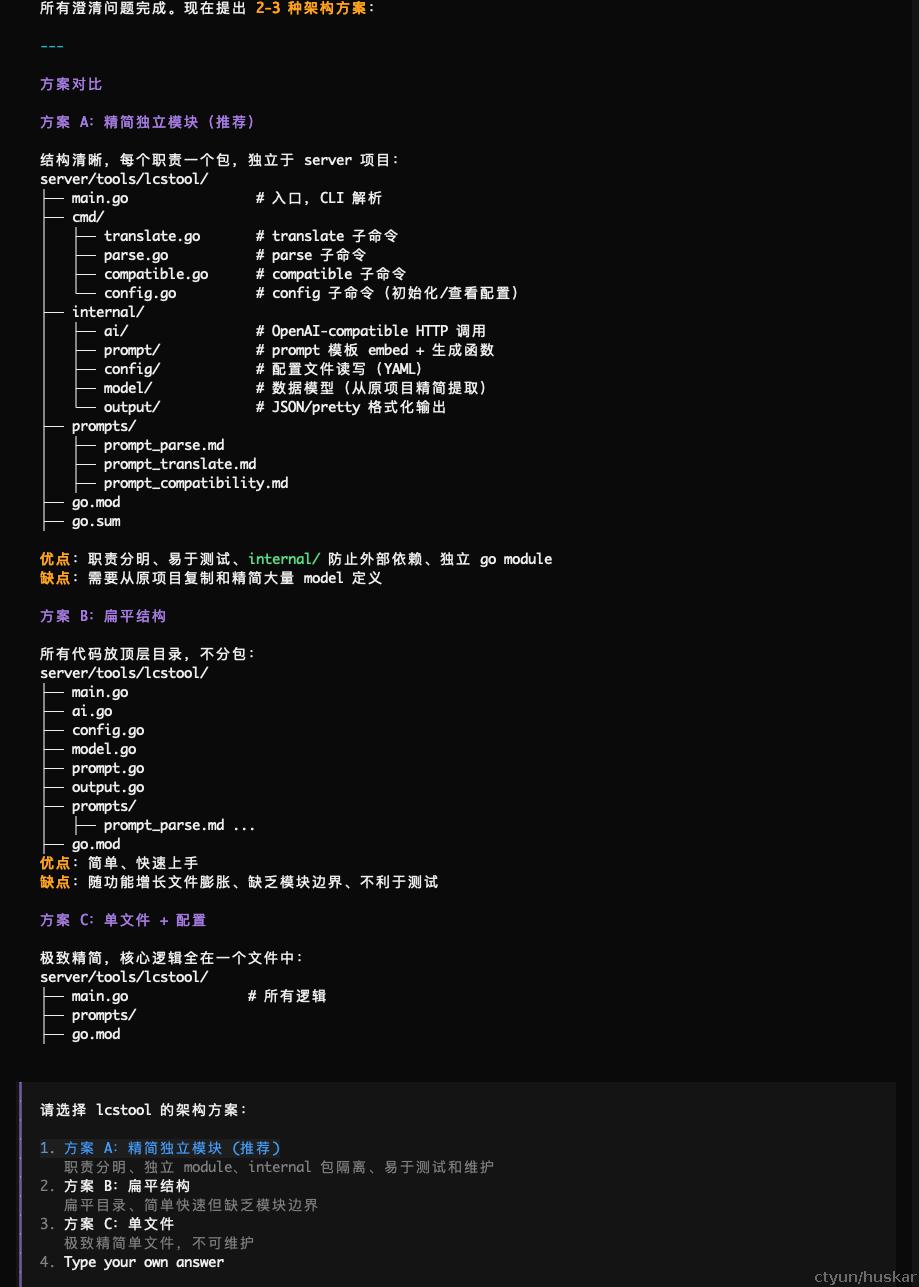
step3:设计与确认
当方案敲定后,AI开始逐节设计,并交互式确认。同样这一步也会进行多轮,直到所有设计均已确认。
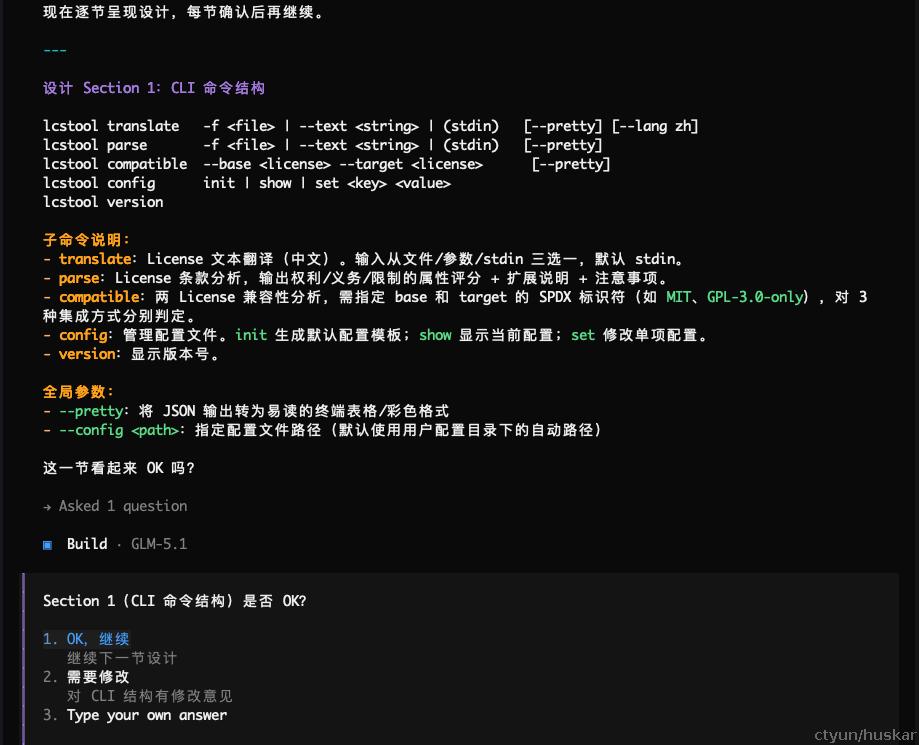
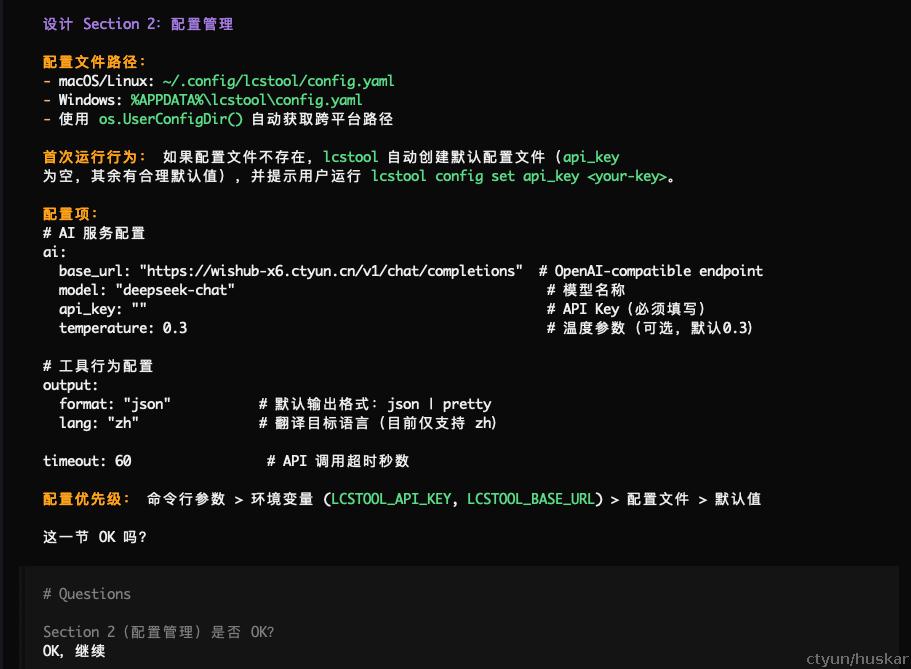
所有设计确认完毕后,开始写设计文档
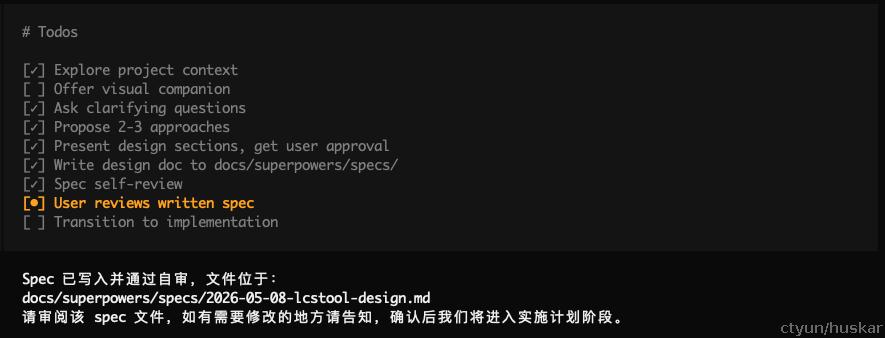
step4: 设计&规格review
这一步也是我们需要花时间自行确认的,开工前的规格review,纠偏的黄金时机。
小小tips: 如果读者和我一样,英文不太好,让AI单独出一篇中文设计文档...
step5:AI拆解任务
当我们确认过规格后,让AI进入实施阶段。
AI并没有立马开干,而是先做了任务拆分:

计划完成后,开始选择执行方式:

- Subagent-Driven (推荐) — 我按任务逐个派发子代理执行,每任务完成后审核,快速迭代
- Inline Execution — 在当前会话中使用 executing-plans 技能批量执行,设置检查点审核
选择执行方式后,开始执行任务。
step6:编码阶段
硅基劳工的后台表(摸)演(鱼)时间...

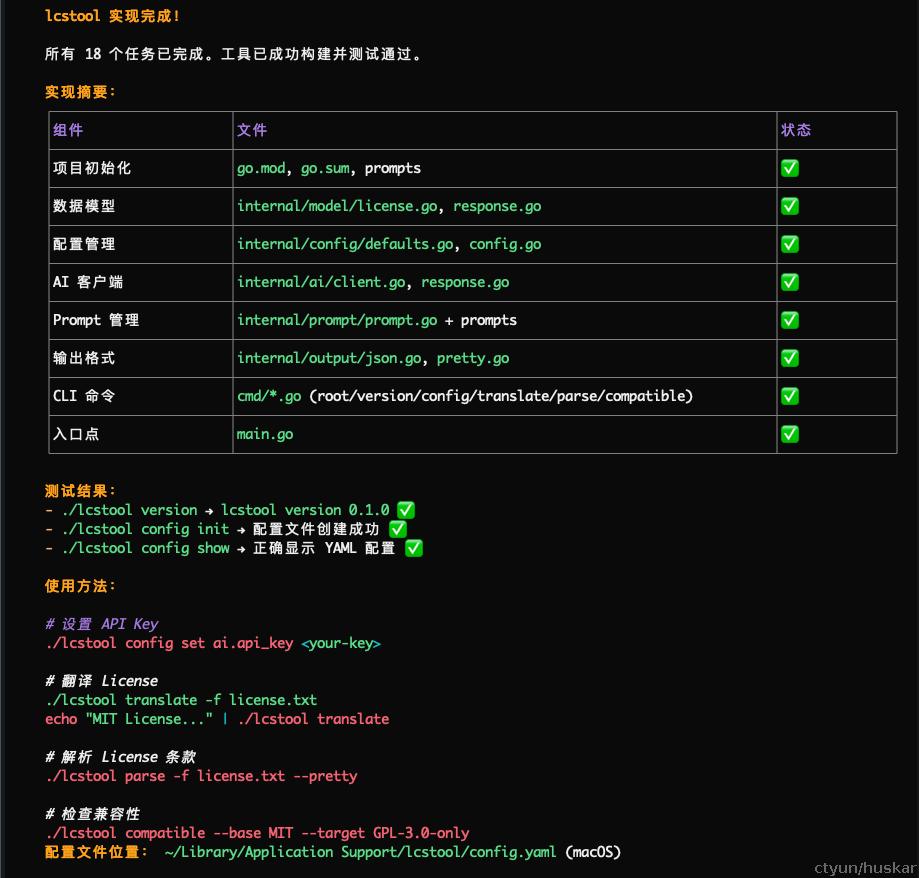
step7:测试验收
虽然Agent 声称已测试通过,但你还的亲自验收。 尤其是涉及到一些真实环境的测试(比如需要配置大模型,运行业务),还得亲力亲为。盲目自信,盲目乐观是大模型的天性(资本家的基因强于工程师的基因)。
Openspec 与 Superpower 对比
设计理念
OpenSpec:为 AI 编程打造“项目法典”,消除随机性
OpenSpec 的理念建立在“规范驱动开发”(Spec-Driven Development, SDD)之上。
在 AI 编程的世界里,最大的问题之一是需求仅存在于一次性的聊天记录中,导致 AI 容易遗忘或篡改意图。
OpenSpec 的做法是,在写下任何一行代码之前,先迫使你和 AI 对“要构建什么”达成一致,并将共识固化为一份机器可读的规范文件。这份规范就是项目的“唯一真相源”(Source of Truth),它不仅存在于对话里,更作为代码库的一部分被长期版本化,AI 永远不会忘记。
Superpowers:AI 的“工程教练”,强制执行纪律
如果说 OpenSpec 是一本静态的“法典”,那 Superpowers 就更像是一位动态的“工程教练”。
它本质上是一套为 AI Agent 设定的方法论和工作流系统,由 14 个可组合的 Skills 构成。
它的核心哲学是:AI 天然倾向于跳过设计、测试、代码审查等关键工程实践,直接产出不可维护的代码。因此,Superpowers 会强行在 AI 的任务执行链路中,插入结构化的工作流程,通过强制执行工程最佳实践来保证软件质量。
应用与场景差异
OpenSpec 更适合这些场景:
- 在现有代码库(棕地项目)上迭代:这是 OpenSpec 最擅长的领域。其核心创新在于 增量规范(Delta-Based Specs),你无需为已有功能重写全套规范,只需为新变更创建提案,并以增量的形式表达修改。这让它能够温柔地融入现有项目。
- 多人/长期协作:当需求需要被记录、审查和追溯时,OpenSpec 的价值就凸显了。它确保了团队不同成员(及其 AI 助手)都基于同一份“蓝图”工作。
- 个人/小团队的快速原型:尽管源于工程实践,但其三步工作流(Propose → Apply → Archive)非常轻量。你可以快速发起规划,然后让 AI 按规范实现,很适合快速试错的小型项目。
Superpowers 更适合这些场景
- 追求代码质量的严肃项目:如果你对测试覆盖率、代码可维护性有高要求,Superpowers 的强制 TDD、系统化调试(Systematic Debugging)和代码审查会非常有价值。
- 复杂的、需要严密论证的任务:当一个需求不明确或影响面大时,Superpowers 会先启动 Brainstorming,通过连续提问帮你澄清所有模糊地带,避免AI“拍脑袋编码”。
- 希望将最佳实践固化为团队习惯:它就像一位 24 小时在线的资深导师,督促开发者(无论是新手还是老手)遵循正确流程,确保产出的代码“自带测试、经过审查、可直接合并”。
- 非纯开发任务:其“规划-拆解-执行-审查-复盘”的工作流是通用的,同样适用于制作营销方案、PPT、数据分析等创造性工作。
使用方式上的差异(突出的)
干预点不同
- OpenSpec:主要作用于编码前。通过 /opsx:propose 等指令在 AI 动手前锁定目标,属于“事前预防”。
- Superpowers:作用于编码全过程。通过一系列 Skills(如 Brainstorming → Write Plan → Execute Plan)在AI的每个执行步骤中持续干预。
流程刚性
- OpenSpec:流程相对温和、灵活。核心是一个“文档流”,强调规范与代码同步演进。
- Superpowers:流程更为强势、结构化。它会“强行地”让 AI 遵循既定的工程节奏,刚性更强。
核心交付物
- OpenSpec:核心交付物是规范文档(proposal.md, design.md, tasks.md 等),这些文档是项目长期资产。
- Superpowers:核心交付物是高质量的代码,以及经过验证的软件功能,副产品是更可靠、更专业的开发过程。
协同工作的关系
两者并非“二选一”的竞争对手,反而可以协同工作。一个典型的组合是:“OpenSpec 做规划,Superpowers 做执行”。
实战路径:
- 先用 OpenSpec 的 explore 和 proposal 产出详细的设计蓝图
- 然后将这些规范文档(specs/ 文件夹)作为上下文,提供给 Superpowers
- 最后,用 Superpowers 启动 Brainstorming 来确认设计,再通过 TDD 等流程严格实现
这样,你既有了稳定的需求“锚点”,又有了可靠的工程“纪律”,实现全流程的质量把控。
