


万众期待的DeepSeek-V4终于来了!拥有百万字超长上下文,在 Agent 能力、世界知识和推理性能上均实现国内与开源领域的领先。
魔乐社区同步上线 DeepSeek开源权重 + 国产算力适配版,助你 Day0 开启“国产SOTA模型 × 国产算力” 双Buff加持的体验。同时,魔乐社区的DeepSeek专区已更新,将陆续上线DeepSeek-V4技术干货和更多国产算力适配模型,欢迎开发者关注体验!
🔗 开源权重:
https://modelers.cn/user/deepseek-ai?model_name=DeepSeek-V4
🔗 量化权重(NPU适配):
https://modelers.cn/models/Eco-Tech/DeepSeek-V4-Flash-w8a8-mtp
🔗 FlagOS多芯适配版(昇腾、沐曦、海光等):
https://modelers.cn/user/FlagRelease?model_name=deepseek-v4
🔗 DeepSeek专区:
https://modelers.cn/topics/deepseek
模型亮点
双版本,Pro性能比肩顶级闭源模型
DeepSeek V4 此次开源两个版本的混合专家架构(MoE)语言模型:DeepSeek-V4-Pro和DeepSeek-V4-Flash,二者均支持百万Token 的上下文长度。

DeepSeek-V4-Pro:
-
Agent 能力大幅提高:在 Agentic Coding 评测中,V4-Pro 已达到当前开源模型最佳水平,并在其他 Agent 相关评测中同样表现优异。
-
世界知识丰富:在世界知识测评中,V4-Pro大幅领先其他开源模型,仅稍逊于顶尖闭源模型 Gemini-Pro-3.1。
-
世界顶级推理性能:在数学、STEM、竞赛型代码的测评中,DeepSeek-V4-Pro 超越当前所有已公开评测的开源模型,取得了比肩世界顶级闭源模型的优异成绩。
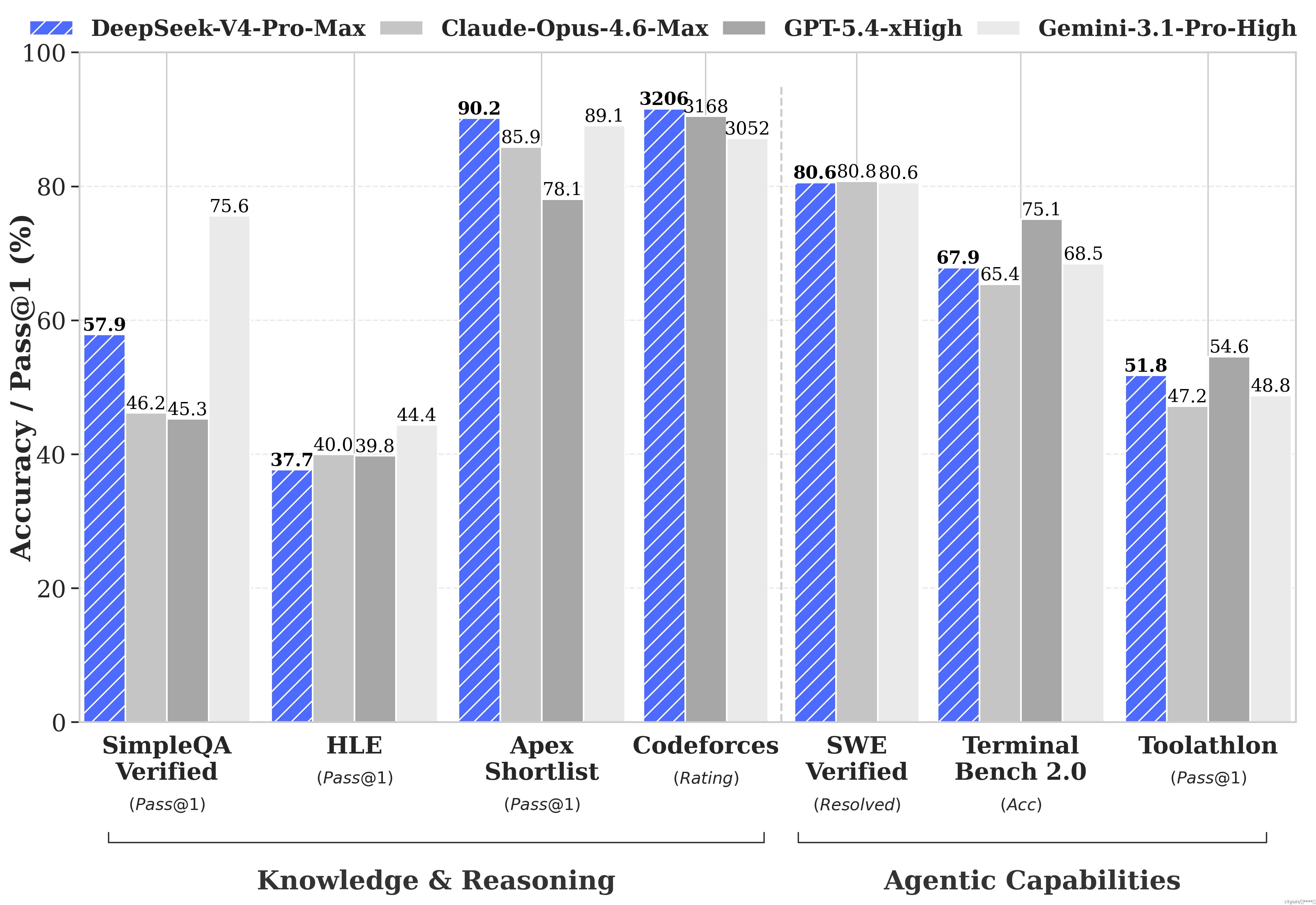
DeepSeek-V4 针对 Claude Code、OpenClaw、OpenCode、CodeBuddy等主流的Agent产品进行了适配和优化,在代码任务、文档生成任务等方面表现均有提升。
DeepSeek-V4-Flash:更快捷高效的经济之选
-
相比 DeepSeek-V4-Pro,DeepSeek-V4-Flash 在世界知识储备方面稍逊一筹,但展现出了接近的推理能力。而由于模型参数和激活更小,相较之下 V4-Flash 能够提供更加快捷、经济的 API 服务。
-
在 Agent 测评中,DeepSeek-V4-Flash 在简单任务上与 DeepSeek-V4-Pro 旗鼓相当,但在高难度任务上仍有差距。
结构创新带来超高上下文效率
DeepSeek-V4 开创了一种全新的注意力机制,在 token 维度进行压缩,结合 DSA 稀疏注意力(DeepSeek Sparse Attention),实现了全球领先的长上下文能力,并且相比于传统方法大幅降低了对计算和显存的需求。而且,1M(一百万)上下文将是 DeepSeek 所有官方服务的标配。
欢迎体验
在魔乐社区,你可以轻松开启DeepSeek-V4的探索之旅:
1. 极速下载
通过社区专属高速通道,快速获取模型权重和适配版本,即刻上手体验,进行部署和微调开发。
2. 在线创建 AI 应用
进入“体验空间”,使用魔乐社区的普惠国产算力和易用工具链,无需复杂部署即可在线推理、创建专属 AI 应用,快速验证想法。
3. 交流共创共成长
前往社区“博客”板块,分享实测效果、微调方案与应用案例,与开发者共同挖掘DeepSeek-V4的无限潜力。
