


大体上,我们一般从3 个维度来了解(理解)工程代码。
-
其一,宏观概览——通过外部介绍性文档了解项目全貌 阅读工程文档、技术白皮书、业务介绍等材料,把握项目的业务需求、核心价值、技术原理、技术选型与整体技术栈,以及系统框架与高层架构。这一层定位在“顶层、粗粒度”,目标是建立对项目的整体认知和上下文背景。
-
其二:虚实映射——通过项目内部文档理解设计与实现映射 借助项目Wiki、需求规格说明书、概要设计、详细设计等文档,将功能需求与具体的技术实现方案关联起来。这一层是连接“做什么”与“怎么做”的核心纽带,通常从系统架构、模块划分、接口关系等角度切入,理解系统的设计逻辑与实现路径。
-
其三:微观深入——通过代码及配套说明掌握实现细节 直接阅读源代码、代码注释,结合接口文档、数据字典、数据库结构、数据模型等技术资料,深入理解具体的实现方式。这一层聚焦在“底层、细粒度”的细节,如代码结构、数据结构、核心算法与业务逻辑等,帮助彻底弄懂系统的实际构造。
通常,我们通过宏观概览,快速了解一个项目的核心功能和技术架构,解决“是什么”的问题,用于初评估、定位、选型。 当我们接手一个项目后,仅仅了解宏观信息是不够的,因此我们迫切的需要掌握该项目的设计与实现,知道项目原生是怎么设计的、怎么实现的;然后才能依据新的需求或问题,找到切入点;进一步了解和掌握实现细节,最后在动手新增、优化、修复、重构。
本篇文章的核心目标,就是探讨如何利用AI工具,来帮助我们快速构建项目中 “设计 - 实现” 的理解桥梁。毕竟,不是所有项目都具备完善的研发流程和研发文档。
AI Wiki 工具简介
要了解项目的设计与实现,除了完备的研发文档,我们日常接触和使用最多的就是项目Wiki。不幸的是,也不是所有项目都有齐备的Wiki和知识库。 得益于AI的发展与普及,现在有很多AI工具提供了快速构建项目Wiki的能力。比如:
| 工具名称 | 核心产品定位 | 技术/交互特点 | 最佳应用场景 | 商业/开源属性 |
|---|---|---|---|---|
| DeepWiki | 对话式的活代码顾问 | 语义问答(RAG)与 Deep Research 深度多轮调研模式,自动生成丰富的 Mermaid 架构图。 | 想通过深度提问搞懂“代码为什么这么写”的开发者。 | 部分开源(deepwiki-open),公开库免费。 |
| Zread (智谱) | 结构化中文项目全景图 | 极为出色的中文理解,提供项目难度评级、阅读时长估计,支持 CLI 本地生成和 MCP 协议。 | 新人加入团队或接手新项目时,快速建立项目全貌认知。 | 闭源 SaaS,公开库免费,私有库需登录。 |
| Code Wiki (Google) | 音视频联动的代码知识库 | 结合了 Google 的代码理解能力,其最大特色是能生成音频/视频格式的项目导读(类似 NotebookLM 播客)。 | 适合通过听觉/视觉展示快速了解一个开源项目的架构和定位。 | 谷歌生态产品,部分功能依附于其云端生态。 |
| NotebookLM (Google) | 通用项目文档知识库 | 虽然它针对的是通用文档(PDF, Markdown, Web),但它在处理大型项目工程文档、PRD、API 文档组合时极其强悍。 | 团队非代码资料、全套产品设计与技术文档的混合分析与跨文档问答。 | 免费 SaaS 平台。 |
| Bloop (AI) | 语义级本地代码搜索引擎 | 专注于极其精准的代码结构跳转和语义搜索(用 Rust 编写),能精准检索方法调用链、引用关系。 | 资深架构师/重度开发者跨巨型复杂本地代码库进行底层排查。 | 闭源商业版,有免费试用额度。 |
| Cursor / Windsurf | 嵌入式 IDE 项目上下文 AI | 通过本地对项目建立高维向量索引(如 @Codebase 触发),实现文档生成与代码编写的无缝闭环。 | 开发者在写代码的同时,对当前项目文件和外部第三方文档进行实时分析。 | 闭源 IDE 编辑器,免费/订阅制。 |
其中,DeepWiki 算得上标杆。它提供了一个共享式的平台服务,对开源的项目(尤其是github)提供了基于深度学习算法的代码知识库;直接检索你感兴趣的仓库,即可查看。
DeepWiki 不支持私有仓库。
最近智普退出了 Zread,功能与DeepWiki 相似,但中文表达更地道(毕竟是中国血脉),而且还支持私有仓库和私有化部署,值得一试。不过,因为上线不就,已经解析的仓库比不上DeepWiki,可能需要提交仓库临时解析(排队,按天)。
最近关注 openwarp,一个智能shell终端,体验一下:
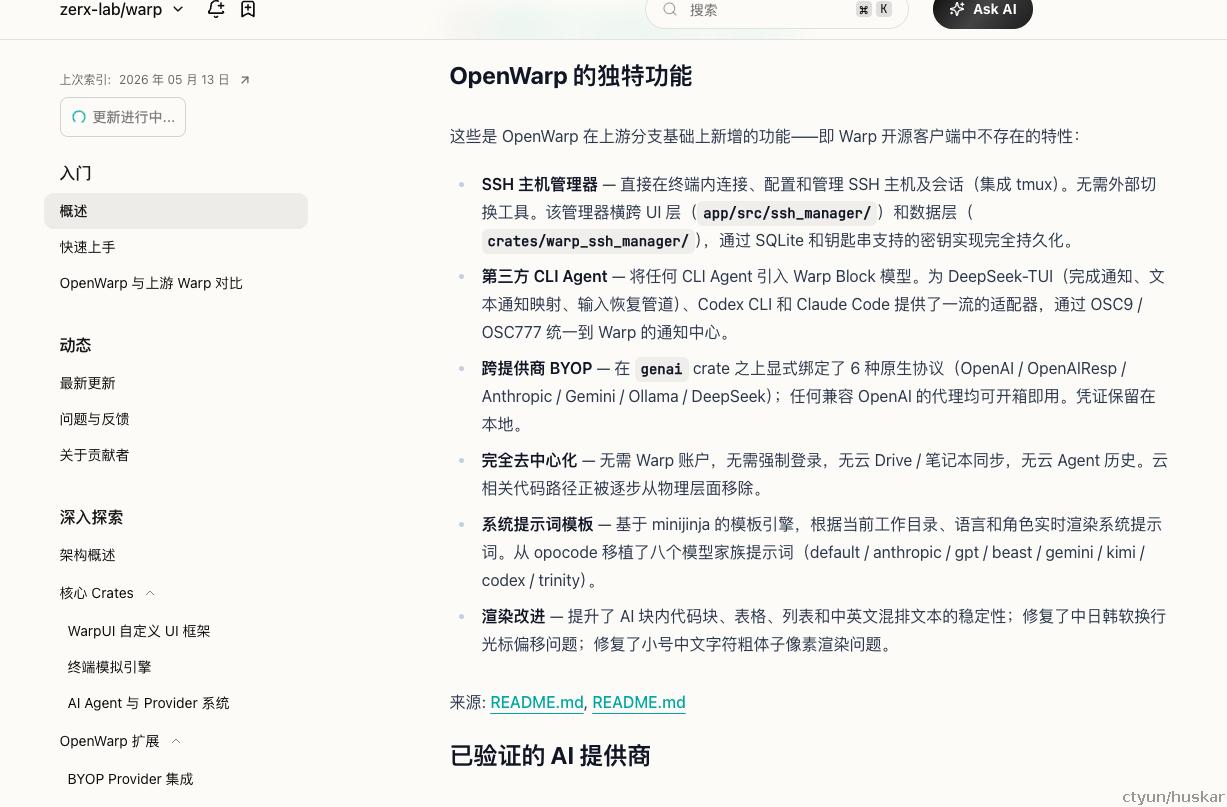
大体脉络还是ok的,细节稍差。
当然,上述工具除了自动生成Wiki,各自都还有些其他特性,比如DeepWiki的深度研究,Zread 私有化部署,CodeWiki的音频播客等等,这里就不再赘述。感兴趣的童鞋自行了解了。
Understand-Anything: 本地项目知识库
前面提到的AI Wiki工具和平台, 大多基于SasS模型,依赖外部服务,某些情况下可能受到局限。 本节我们介绍另外一个工具 Understand-Anything, 是per project 级别的知识库(依赖AI模型)。
Understand-Anything 是什么?
Understand Anything 是一个 Claude Code Plugin,通过多智能体(multi-agent)架构分析你的项目,构建包含文件、函数、类以及依赖关系的知识图谱,并提供一个可视化交互界面,帮助你理解整个系统。不再”盲读代码”,而是从全局视角理解系统结构。 其核心思想是“本地解析,本地问答”。它会把整个代码仓库解析成结构化数据,然后在你提问时,从这些结构中检索最相关的上下文,交给本地运行的大模型生成答案。
关键特性:
- 本地运行,代码不出本机 —— 适合企业内部项目或敏感代码库。
- 多语言支持 —— 通过 tree‑sitter 支持 Python、Java、Go、TS/JS、Rust、C/C++ 等多种主流语言。
- 以代码结构为索引 —— 不是简单地把文件当成文本丢给模型,而是先提取函数、类、接口、调用关系等,再基于这些结构检索,回答更精准。
- 对话式交互 —— 可以连续追问,逐步深入,就像在聊天框里探索项目。
Understand-Anything 的安装部署
Understand-Anything 本是Claude Code 的插件,在Claude 中用内置/plugin 安装即可。
其他平台(codex,opencode,openclaw,gemini-cli,hermes等),采用脚本安装:
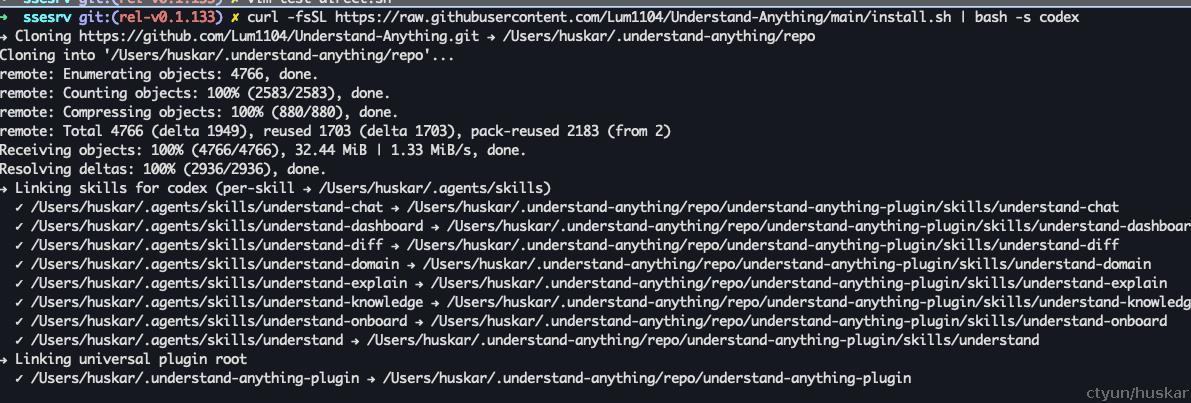
安装的本质是,创建了一系列Code Agent 使用的skill。
特别的,Cursor中安装采用离线方式。 先克隆此仓库后,然后Cursor 会自动通过 .cursor-plugin/plugin.json文件发现插件。无需手动安装 — 只需克隆并在 Cursor 中打开即可。 若自动发现未生效,可手动安装:打开 Cursor Settings → Plugins,在搜索框中粘贴仓库地址并添加。
Understand-Anything 的使用
分析你的代码库
/understand
多智能体(multi-agent)架构会:扫描你的项目,提取函数 / 类 / 依赖,构建知识图谱保存至 .understand-anything/knowledge-graph.json .
本地化输出,使用 --language 参数生成中文内容:
--language 参数会影响:- 知识图谱中的节点摘要和描述
- Dashboard UI 的标签、按钮和提示
- 导览路线的解释说明
/understand 分7个阶段:
Phase 0 — Pre-flight(预检与决策)
- 检查代码仓库根目录是否存在,是否可读。
- 对比当前仓库的 文件指纹(哈希或时间戳) 与上次索引的缓存记录,判断哪些文件发生了变更。
- 决定本次执行模式:
- 全量分析:首次运行或缓存无效时触发;
- 增量更新:只处理新增、修改或删除的文件,大幅减少重复工作。
Phase 0.5 — Ignore Configuration(忽略规则设置与验证)
- 读取并解析代码仓库中的 .understandignore 文件(语法类似 .gitignore)。
- 对忽略规则进行合法性校验(防止错误的正则或路径导致重要文件被排除)。需要人工确认并回复。
- 根据忽略规则生成文件过滤清单,后续阶段将跳过所有匹配的目录或文件(如 node_modules、vendor、build、测试数据等)。
Phase 1 — File Discovery & Categorization(文件发现与分类)
- 遍历整个代码仓库目录(遵循忽略规则),收集所有需要分析的文件路径。
- 根据文件扩展名、路径约定及 shebang/首行特征,识别每个文件的语言类型(Python、Java、Go、TypeScript 等)。
- 过滤掉无法识别、二进制或明显非代码的文件;将文件按语言分组,为后续语言特定解析做准备。
Phase 2 — Code Parsing(代码结构化解析)
- 使用多语言前端解析器(如 tree-sitter 或 ast-grep)对每个源码文件进行语法分析,构建 AST(抽象语法树)。
- 从 AST 中提取出顶层定义:
- 函数 / 方法签名、类、接口、结构体、枚举等;
- 变量的定义位置、导出/可见性修饰符;
- 文档注释(docstring / Javadoc / JSDoc 等)的原始文本。
- 对解析失败的文件记录错误,但不中断整个流程。
Phase 3 — Symbol Table & Reference Resolution(符号表构建与引用解析)
- 将所有提取出的定义组织成全局符号表,并为每个符号分配唯一 ID。
- 通过分析语法树中的名称引用、导入语句、继承/实现关系,建立符号之间的关联边:
- 调用关系:函数 A 调用了函数 B;
- 继承关系:子类实现父类接口;
- 引用关系:变量引用某个类型定义等。
- 进行简单的名字解析和作用域分析,将引用链接到可能的定义(考虑重载、跨模块导入)。
Phase 4 — Graph Construction & Semantic Index(图谱构建与语义索引)
- 将符号和关系边整理成一张代码知识图谱(通常存为图结构或邻接表),并持久化到本地索引数据库。
- 同时构建倒排索引或稠密检索索引:
- 将代码片段、函数名称、注释等文本转化为向量或关键词索引,供自然语言提问时快速检索。
- 为大型仓库可能还会计算 PageRank 或节点中心性,以便后续优先展示核心模块。
Phase 5 — Context Generation & Embedding(上下文生成与向量化)
- 对每个关键符号(如公开函数、类、接口)生成结构化摘要文本,融合代码签名、注释、所在文件路径等信息。
- 将摘要文本通过嵌入模型(可选本地小模型)向量化,存入向量数据库。
- 如果需要,会为整个项目生成宏观摘要(项目入口文件、主要模块职责等),便于快速回答“项目是做什么的”这类宏观问题。
Phase 6 — Ready State & Question Interface(就绪与问答接口)
- 所有索引和缓存构建完毕,Understand-Anything 进入“可提问”状态。
- 当用户用自然语言提问时:
- 检索阶段:从符号表、图结构、向量索引中召回最相关的代码片段和设计说明;
- 上下文组装:将检索到的结构化信息片段拼接成提示词上下文;
- LLM 推理:将上下文发送给本地大模型,生成自然语言答案。
- 同时,系统会根据缓存的元数据,在后续 /understand 增量运行时直接进入 Phase 0 的增量路径,跳过重复计算。
打开数据看板
/understand-dashboard
打开交互式网页数据看板,您的代码库将以图表形式呈现 — 按架构层级进行颜色编码,支持搜索和点击。选择任意节点即可查看其代码、关系以及简明易懂的解释。
注意,如果项目复杂度高,数据看板显示不是特别友好。加载速度慢,而且拖动和缩放容易飘,稍微慢一点。
高级用法
询问任意代码库的问题
/understand-chat How does the payment flow work?
分析当前修改的影响
/understand-diff
深入理解某个文件
/understand-explain src/auth/login.ts
为新团队成员生成指南
/understand-onboard
提取业务领域知识(领域、流程、步骤)
/understand-domain
分析 Karpathy 模式的 LLM Wiki 知识库
/understand-knowledge ~/path/to/wiki
直接重跑即可 —— 默认增量更新,只分析变更的文件
/understand
安装 post-commit 钩子,每次提交自动增量更新
/understand --auto-update
大型 monorepo?把分析范围限定到某个子目录
/understand src/frontend