


0.引言
不知道是否有很多读者跟我一样,对序列化和反序列化这一对名词始终是一知半解,存在着一种会用但不懂的奇怪状态,本文就来详细的,从java源码的层面来解释一下序列化与反序列化究竟是什么,有什么作用,是怎么实现的
1.序列化的作用
大家都知道,java是强制性的面向对象语言,万物皆对象。但是在实际使用中,我们始终还是要把这些对象转化为适合我们存储、阅读、编辑的数据。
比如:网页开发中需要读取出入参,在源码中往往就是对象;程序输出/读取某些数据.......
这些都是非常实际的应用场景,但是java不可能直接传输一个对象类过去,那么我们就需要将这些对象,或者数java的数据,转化为“字节序列”这个非常常用且方便的形式。这就是序列化的核心:把java对象转为字节序列
反序列化定义则与之相反,一定程度上这也是java适用范围如此广的原因之一,毕竟序列化提供的字节序列可以很方便的在其他平台上流转
2.序列化的基本方法
还是用我最喜欢的user来举例
@Data
//将实体类交给spring管理,自动扫描
@Component
//加载配置内容,设定配置前缀,注意:prefix参数不支持小驼峰原则,必须全部小写
@ConfigurationProperties(prefix = "user")
public class User implements Serializable{
@Value("132456")
private Integer uid;
@Value("wy")
private String uname;
@Value("asd")
private String password;
@Value("Beijing, Sichuan, Nanchang")
private List<String> addrs;
public User() {
}
public User(Integer uid, String uname, String password, ArrayList<String> addrs) {
this.uid = uid;
this.uname = uname;
this.password = password;
this.addrs = addrs;
}
public static void serialize( User user ) throws IOException {
ObjectOutputStream objectOutputStream =
new ObjectOutputStream(Files.newOutputStream(new File("user.txt").toPath()));
objectOutputStream.writeObject( user );
objectOutputStream.close();
System.out.println("序列化成功!已经生成user.txt文件");
System.out.println("==============================================");
}
public static void deserialize() throws IOException, ClassNotFoundException {
ObjectInputStream objectInputStream =
new ObjectInputStream(Files.newInputStream(new File("user.txt").toPath()));
User user = (User) objectInputStream.readObject();
objectInputStream.close();
System.out.println("反序列化结果为:");
System.out.println( user );
}
}假如我们要把User序列化后的字节序列,存储到一个txt中,应该怎么办呢?首先我们要将需要序列化的类加上 implements Serializable,这个java内置的接口
之后需要写利用输出输入流写一对序列化/反序列化方法,这里上面的代码都有了,逻辑非常简单,我们直接new一个user对象去运行,结果如下:
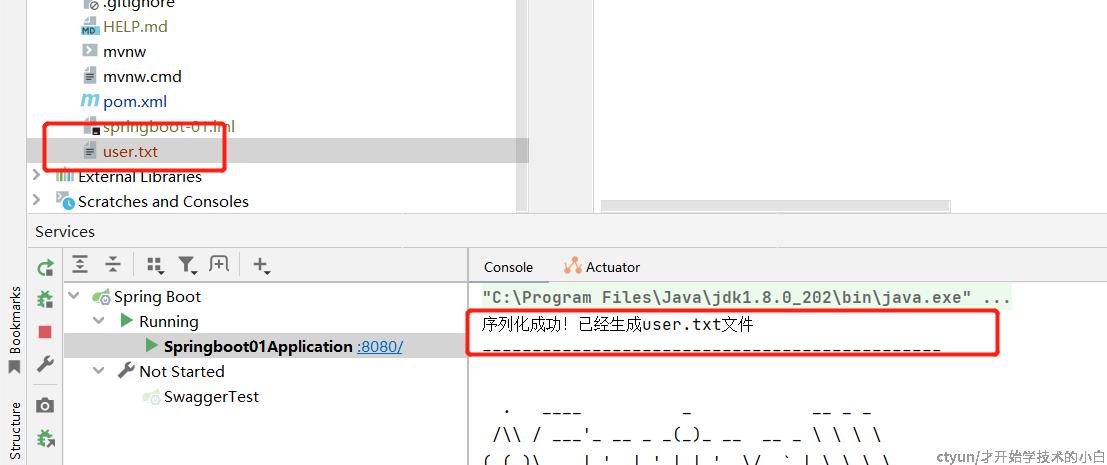
同样的,如果执行反序列化,也会将之前写入的结果输出:

注意:实际过程中可能会发现输出的txt文件是乱码,这个是字节码的编码问题,并不影响反序列化
3.Serializable接口
可以看到,刚刚我们非常简单的一个实现过程,第一步就是定义User类的时候实现Serializable接口,这个接口究竟有何奥秘?直接点进去看,发现他居然是空的:

这么神奇,但是不加这个空接口运行时会报错(NotSerializableException异常),这究竟是为什么呢?我们就先把这个接口取消,然后跟着报错来看看是哪里出了问题,这里哪序列化过程来举例:
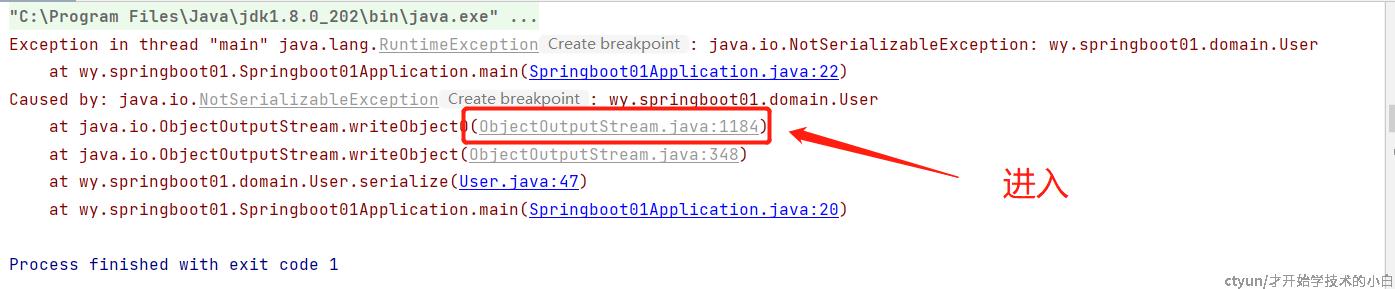
结果发现下面这段代码,我恍然大悟:
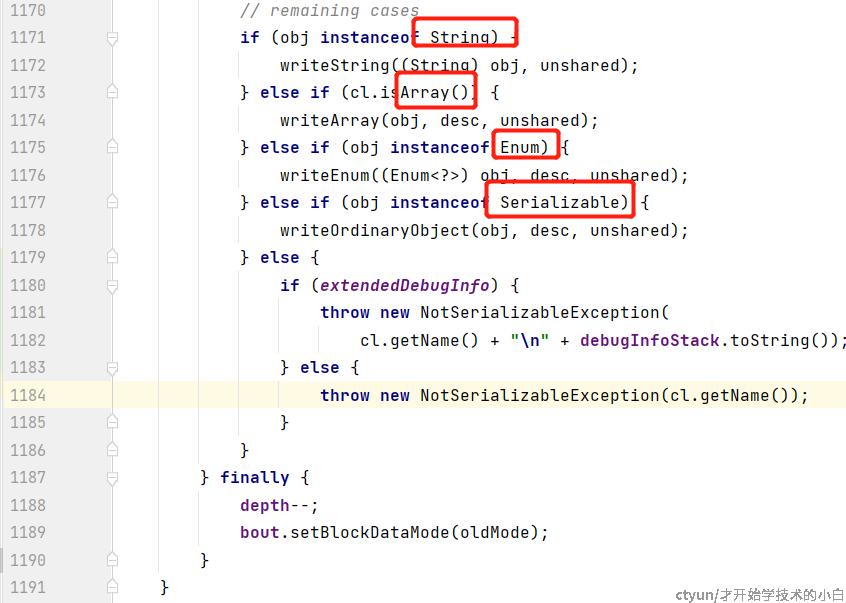
原来在输入输出流的内部,有这么一串if的判断:
如果一个对象既不是字符串、数组、枚举,而且也没有实现Serializable接口的话,在序列化时就会抛出NotSerializableException异常!!!
换而言之,Serializable接口的作用就是一个tag标记,实现了他的接口在输入输出流中就可以被序列化,但序列化这个动作的具体执行跟这个接口没有任何关系
4.serialVersionUID
有的时候我们会看到一些开源的项目,实现了Serializable接口的类,会显式的定义一个字段:serialVersionUID
这是个什么东西?其实非常好理解,他就是一个序列化过程中的身份证,我们举例来说明
还是用user类,假设我们需要从txt中反序列化一个user类,我们刚刚已经实现了,调用相关方法即可
但是在调用这个方法之前,我先给user类再加一个属性,随便加,比如说加上: private Integer userID
再去执行反序列化方法,会发生什么?当然是会报错,InvalidClassException
表面上看好像是因为动了user类之后,这个类和txt中信息不匹配了,但实际上如果我们再仔细阅读下错误信息,会发现其中有这么一句话:
local class imcompatible: stream classdesc serialVersionUID=7845186160046978462, local classdesc serialVersionUID=8847633160264555640
很明显,这就是说的serialVersionUID不匹配,原来在序列化过程中,serialVersionUID是标识符且是唯一的标识符,如果serialVersionUID不匹配则无法进行反序列化;其次如果我们自己不定义serialVersionUID,编译器会自动声明一个,但他并不出现在序列化后的json中(实际上这也是txt乱码的原因之一)。
这就是为什么我们有的时候建议手动定义serialVersionUID,就是为了防止在类修改了已经有的文件反序列化不成功的情况
5.相关注解与修饰符
最常用的序列化注解为 transient,被他修饰的字段不会被序列化(会是null),需要注意的是static修饰的字段也是如此,比如;
private static String name;
private transient String id;这两个字段都不会被序列化,当然通常我们会使用更加灵活的注解@Expose,它拥有两个属性,可以非常灵活的定义该字段是否需要序列化/反序列化
//@Expose()参与序列化和反序列化
//@Expose(serialize = false)不参与序列化,只参与反序列化
// @Expose(deserialize = false)只参与序列化,不参与反序列化
@Expose(serialize = false,deserialize = false)//序列化和反序列化都不参与
private int age;@Expose是gson下的注解,需要引入gson依赖,这里我们使用的是谷歌标准的gson,在pom中加入
<dependency>
<groupId>com.google.code.gson</groupId>
<artifactId>gson</artifactId>
</dependency>有的时候我们会遇到这么一种情况,传入的json可能是从其他平台过来的,我们需要对他做反序列化形成一个对象在java程序中使用,但是通常不同平台的命名规范不一样,如果为了接收这个数据专门改一下命名,似乎不是很合理,怎么办呢?比如传入的为userName,但我们的对象为uname
可以用@SerializedName注解来解决这个问题:
@SerializedName("userName")
private String uname;这样再使用谷歌的Gson解析的时候,userName对应的value就会赋值给uname,反之亦然,解决了java对象里属性名跟json里字段名不匹配的情况
