


容器是一种轻量级的操作系统层面的虚拟化技术。重点是 “操作系统层面” ,即容器本质上是利用操作系统提供的功能来实现虚拟化。
容器技术的代表之作 Docker ,则是一个基于 Linux 操作系统,使用 Go 语言编写,调用了 Linux Kernel 功能的虚拟化工具。
为了更好地理解容器的本质,我们来看看容器具体使用了哪些 Linux Kernel 技术。
1. Namespace
NameSpace 即命名空间是 Linux Kernel 一个强大的特性,可用于进程间资源隔离。
由于容器之间共享 OS ,对于操作系统而言,容器的实质就是进程,多个容器运行,对应操作系统也就是运行着多个进程。
当进程运行在自己单独的命名空间时,命名空间的资源隔离可以保证进程之间互不影响,大家都以为自己身处在独立的一个操作系统里。这种进程就可以称为容器。
回到资源隔离上,从 Kernel: 5.6 版本开始,已经提供了 8 种 NameSpace ,这 8 种 NameSpace 可以对应地隔离不同的资源( Docker 主要使用了前 6 种)。
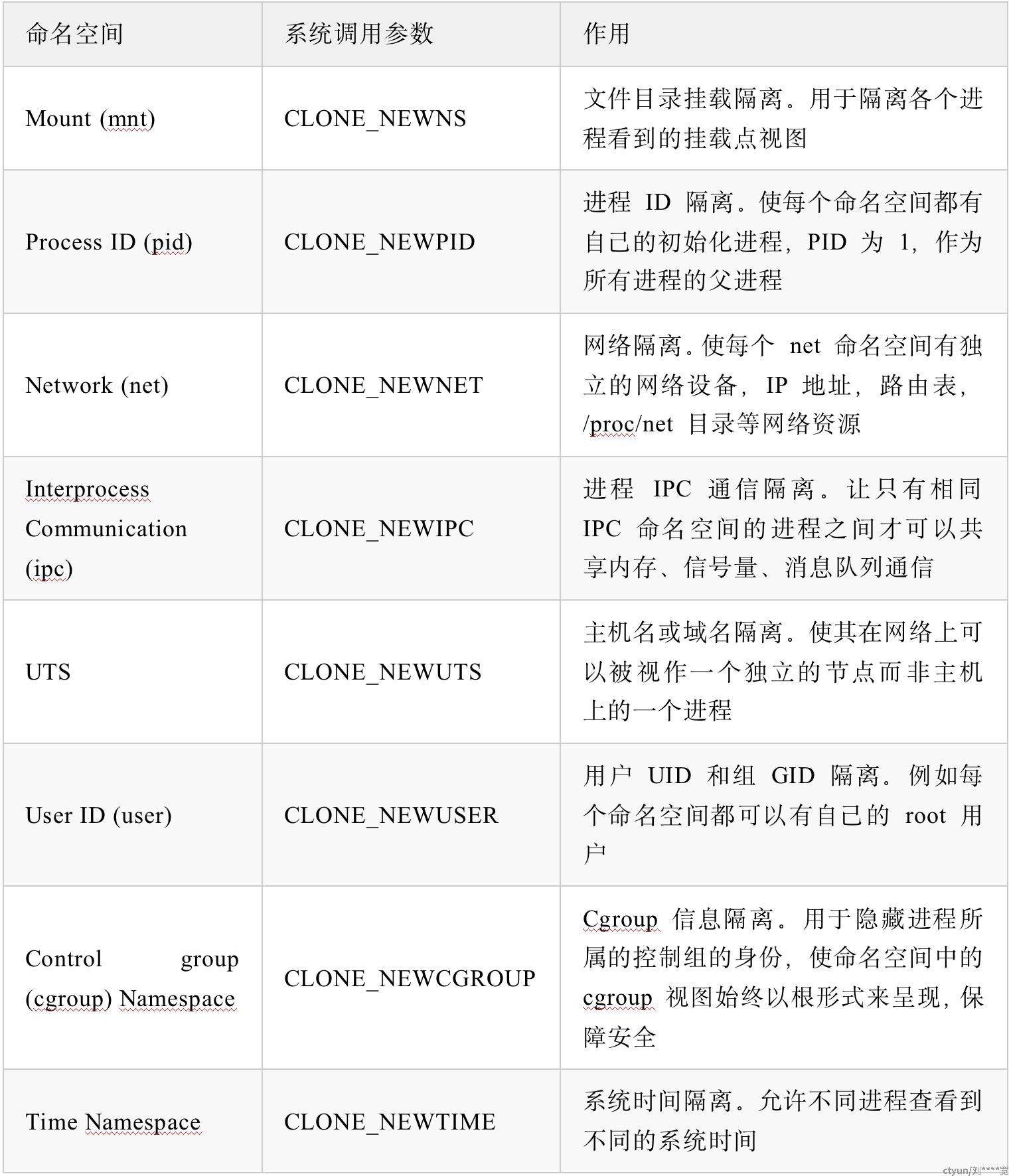
NameSpace 的具体描述可以查看 Linux man 手册中的 NAMESPACES[1] 章节,手册中还描述了几个 NameSpace API ,主要是和进程相关的系统调用函数。
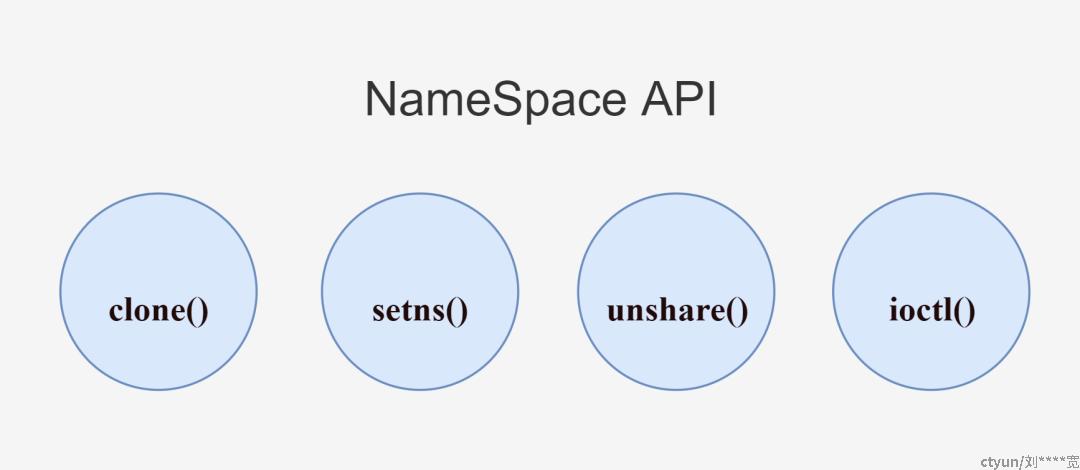
clone()
int clone(int (*fn)(void *), void *stack, int flags, void *arg, ...
/* pid_t *parent_tid, void *tls, pid_t *child_tid */ );
clone() 用于创建新进程,通过传入一个或多个系统调用参数( flags 参数)可以创建出不同类型的 NameSpace ,并且子进程也将会成为这些 NameSpace 的成员。
setns()
int setns(int fd, int nstype);
setns() 用于将进程加入到一个现有的 Namespace 中。其中 fd 为文件描述符,引用 /proc/[pid]/ns/ 目录里对应的文件,nstype 代表 NameSpace 类型。
unshare()
int unshare(int flags);
unshare() 用于将进程移出原本的 NameSpace ,并加入到新创建的 NameSpace 中。同样是通过传入一个或多个系统调用参数( flags 参数)来创建新的 NameSpace 。
ioctl()
int ioctl(int fd, unsigned long request, ...);
ioctl() 用于发现有关 NameSpace 的信息。
上面的这些系统调用函数,我们可以直接用 C 语言调用,创建出各种类型的 NameSpace ,这是最直观的做法。而对于 Go 语言,其内部已经帮我们封装好了这些函数操作,可以更方便地直接使用,降低心智负担。
2. Cgroups
借助 NameSpace 技术可以帮进程隔离出自己单独的空间,成功实现出最简容器。但是怎样限制这些空间的物理资源开销(CPU、内存、存储、I/O 等)就需要利用 Cgroups 技术了。
限制容器的资源使用,是一个非常重要的功能,如果一个容器可以毫无节制的使用服务器资源,那便又回到了传统模式下将应用直接运行在物理服务器上的弊端。这是容器化技术不能接受的。
Cgroups 的全称是 Control groups 即控制组,最早是由 Google 的工程师(主要是 Paul Menage 和 Rohit Seth)在 2006 年发起,一开始叫做进程容器(process containers)。在 2007 年时,因为在 Linux Kernel 中,容器(container)这个名词有许多不同的意义,为避免混乱,被重命名为 cgroup ,并且被合并到 2.6.24 版本的内核中去。Android 也是凭借这个技术,为每个 APP 分配不同的 cgroup ,将每个 APP 进行隔离,而不会影响到其他的 APP 环境。
Cgroups 是对进程分组管理的一种机制,提供了对一组进程及它们的子进程的资源限制、控制和统计的能力,并为每种可以控制的资源定义了一个 subsystem (子系统)的方式进行统一接口管理,因此 subsystem 也被称为 resource controllers (资源控制器)。
几个主要的 subsystem 如下( Cgroups V1 ):
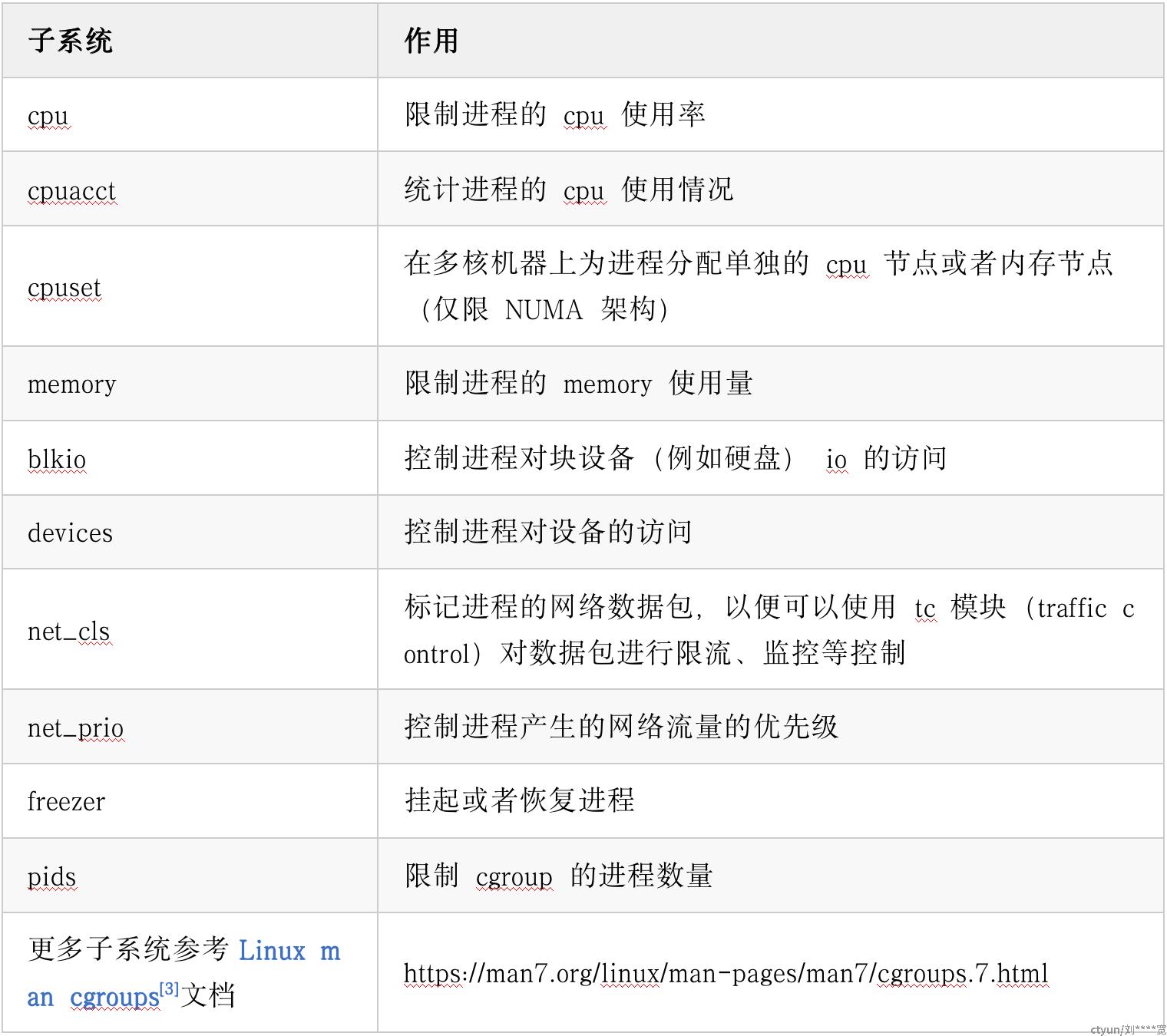
借助 Cgroups 机制,可以将一组进程(task group)和一组 subsystem 关联起来,达到控制进程对应关联的资源的能力。如图:
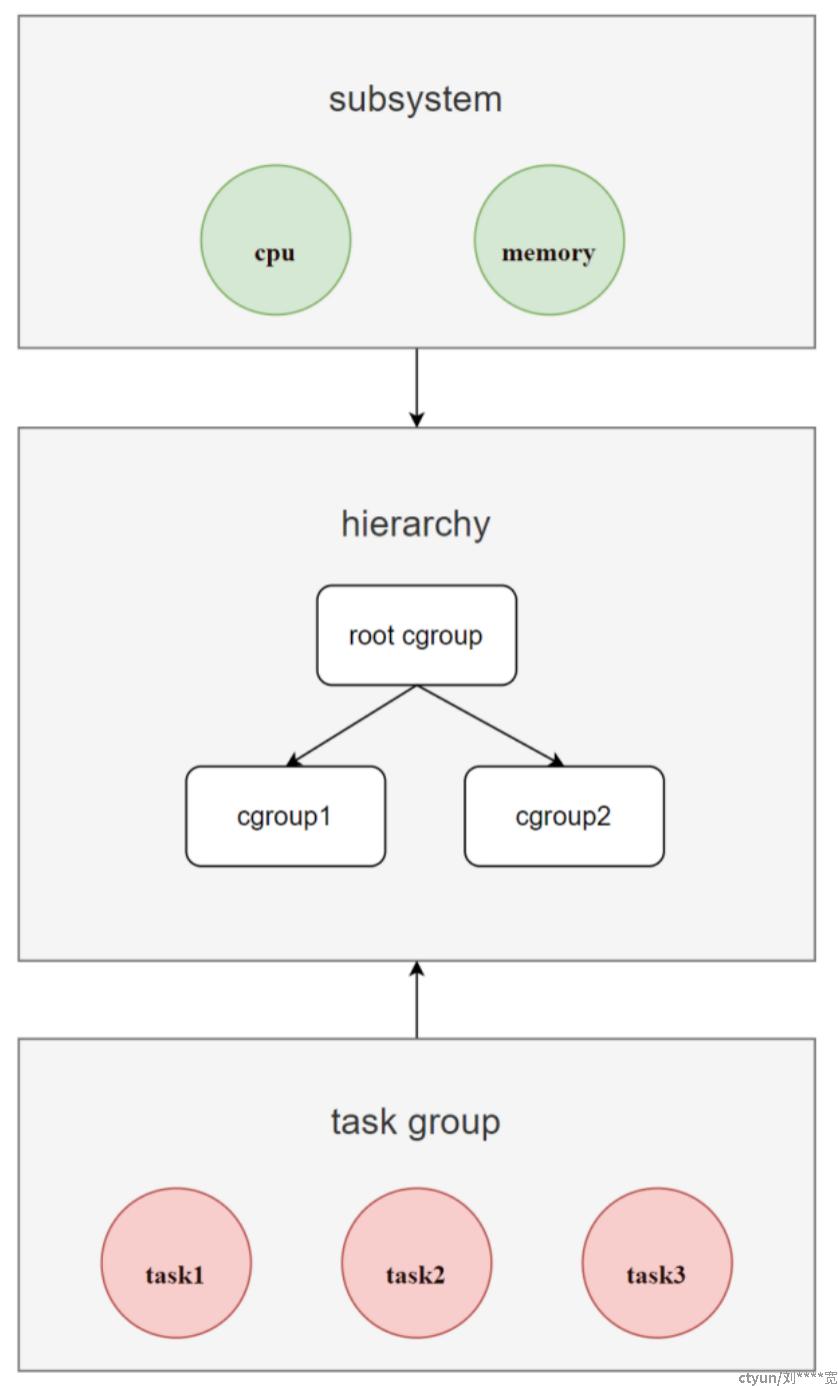
Cgroups 的层级结构称为 hierarchy (即 cgroup 树),是一棵树,由 cgroup 节点组成。
系统可以有多个 hierarchy ,当创建新的 hierarchy 时,系统所有的进程都会加入到这个 hierarchy 默认创建的 root cgroup 根节点中,在树中,子节点可以继承父节点的属性。
对于同一个 hierarchy,进程只能存在于其中一个 cgroup 节点中。如果把一个进程添加到同一个 hierarchy 中的另一个 cgroup 节点,则会从第一个 cgroup 节点中移除。
hierarchy 可以附加一个或多个 subsystem 来拥有对应资源(如 cpu 和 memory )的管理权,其中每一个 cgroup 节点都可以设置不同的资源限制权重,而进程( task )则绑定在 cgroup 节点中,并且其子进程也会默认绑定到父进程所在的 cgroup 节点中。
基于 Cgroups 的这些运作原理,可以得出:如果想限制某些进程的内存资源,就可以先创建一个 hierarchy ,并为其挂载 memory subsystem ,然后在这个 hierarchy 中创建一个 cgroup 节点,在这个节点中,将需要控制的进程 pid 和控制属性写入即可。
3. UnionFS
除了利用 NameSpace 和 Cgroups 来实现 容器(container) ,在 Docker 中,还使用到了一个 Linux Kernel 技术:UnionFS 来实现 镜像(images) 功能。
UnionFS 全称 Union File System (联合文件系统),在 2004 年由纽约州立大学石溪分校开发,是为 Linux、FreeBSD 和 NetBSD 操作系统设计的一种分层、轻量级并且高性能的文件系统,可以把多个目录内容联合挂载到同一个目录下 ,而目录的物理位置是分开的,并且对文件系统的修改是类似于 git 的 commit 一样 作为一次提交来一层层的叠加的。
在 Docker 中,镜像相当于是容器的模板,一个镜像可以衍生出多个容器。镜像利用 UnionFS 技术来实现,就可以利用其分层的特性来进行镜像的继承,基于基础镜像,制作出各种具体的应用镜像,不同容器就可以直接共享基础的文件系统层 ,同时再加上自己独有的改动层,大大提高了存储的效率。
以该 Dockerfile 为例:
FROM ubuntu:18.04
LABEL org.opencontainers.image.authors="org@example.com"
COPY . /app
RUN make /app
RUN rm -r $HOME/.cache
CMD python /app/app.py
镜像的每一层都可以代表 Dockerfile 中的一条指令,并且除了最后一层之外的每一层都是只读的。
在该 Dockerfile 中包含了多个命令,如果命令修改了文件系统就会创建一个层(利用 UnionFS 的原理)。
首先 FROM 语句从 ubuntu:18.04 镜像创建一个层 【1】,而 LABEL 命令仅修改镜像的元数据,不会生成新镜像层,接着 COPY 命令会把当前目录中的文件添加到镜像中的 /app 目录下,在层【1】的基础上生成了层【2】。第一个 RUN 命令使用 make 构建应用程序,并将结果写入新层【3】。第二个RUN 命令删除缓存目录,并将结果写入新层【4】。最后,CMD 指令指定在容器内运行什么命令,只修改了镜像的元数据,也不会产生镜像层。这【4】个层(layer)相互堆叠在一起就是一个镜像。当创建一个新容器时,会在 镜像层(image layers) 上面再添加一个新的可写层,称为容器层(container layer) 。对正在运行的容器所做的所有更改,例如写入新文件、修改现有文件和删除文件,都会写入到这个可写容器层。
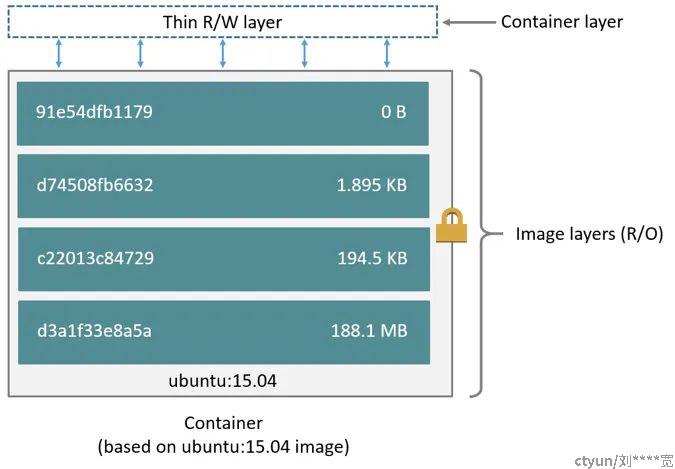
对于相同的镜像层,每一个容器都会有自己的可写容器层,并且所有的变化都存储在这个容器层中,所以多个容器可以共享对同一个底层镜像的访问,并且拥有自己的数据状态。而当容器被删除时,其可写容器层也会被删除,如果用户需要持久化容器里的数据,就需要使用 Volume 挂载到宿主机目录。
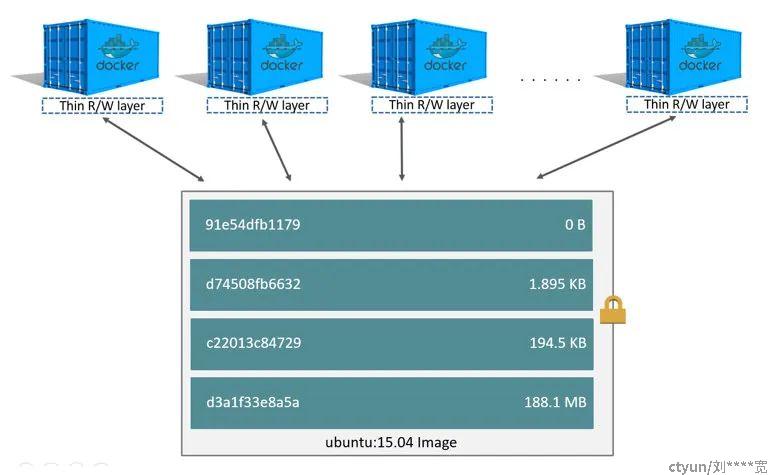
看完 Docker 镜像的运作原理,让我们回到其实现技术 UnionFS 本身。目前 Docker 支持的 UnionFS 有以下几种类型:
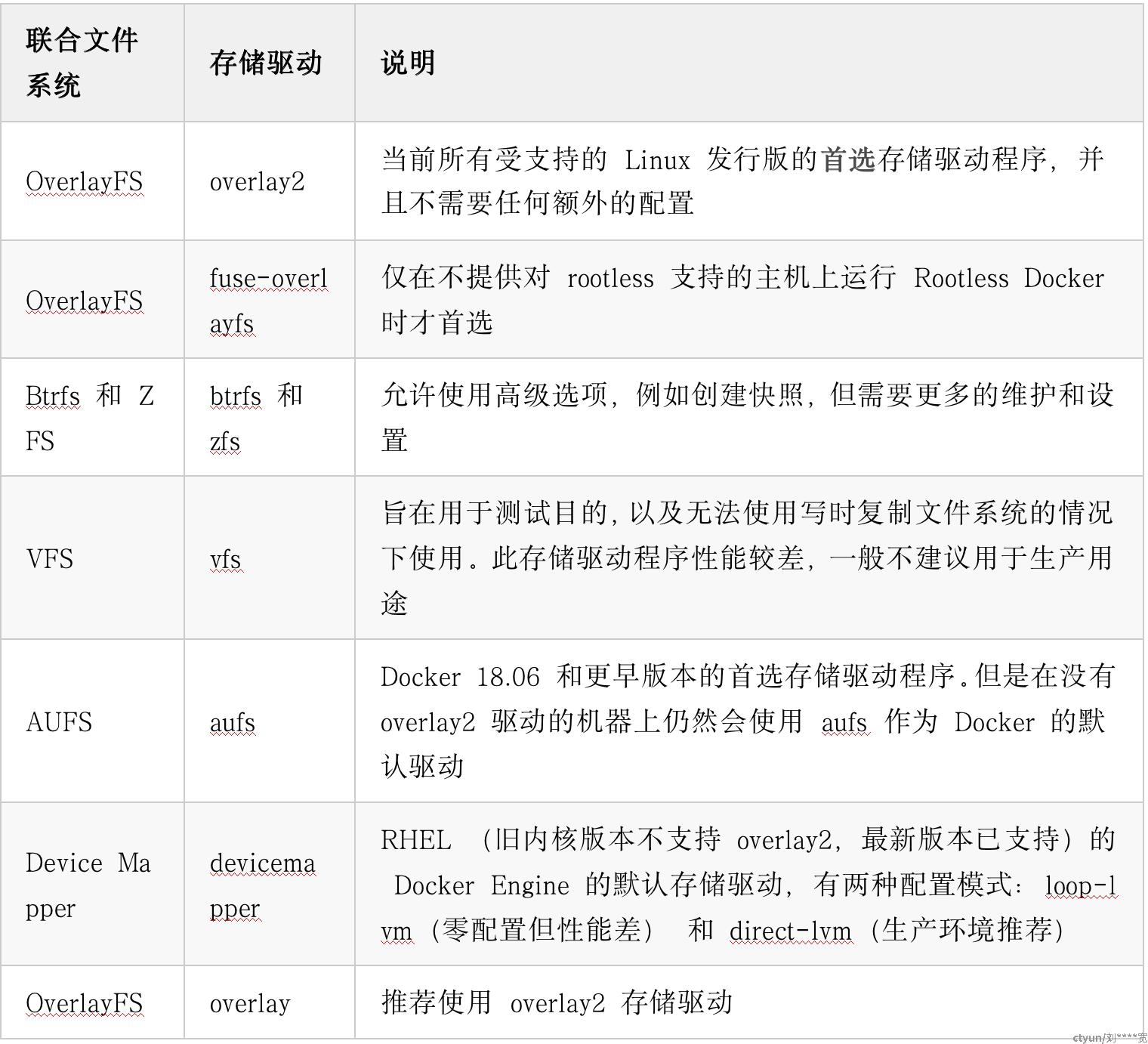
在尽可能的情况下,推荐使用 OverlayFS 的 overlay2 存储驱动,这也是当前 Docker 默认的存储驱动(以前是 AUFS 的 aufs )。
可查看 Docker 使用了哪种存储驱动:
[root@host ~]# docker -v
Docker version 20.10.15, build fd82621
[root@host ~]# docker info | grep Storage
Storage Driver: overlay2
[root@host ~]#
OverlayFS 其实是一个类似于 AUFS 的、面向 Linux 的现代联合文件系统,在 2014 年被合并到 Linux Kernel (version 3.18)中,相比 AUFS 其速度更快且实现更简单。overlay2(Linux Kernel version 4.0 或以上)则是其推荐的驱动程序。
overlay2 由四个结构组成,其中:
- lowerdir :表示较为底层的目录,对应 Docker 中的只读镜像层
- upperdir :表示较为上层的目录,对应 Docker 中的可写容器层
- workdir :表示工作层(中间层)的目录,在使用过程中对用户不可见
- merged :所有目录合并后的联合挂载点,给用户暴露的统一目录视图,对应 Docker 中用户实际看到的容器内的目录视图
这是在 Docker 文档中关于 overlay 的架构图,但是对于 overlay2 也同样可以适用:
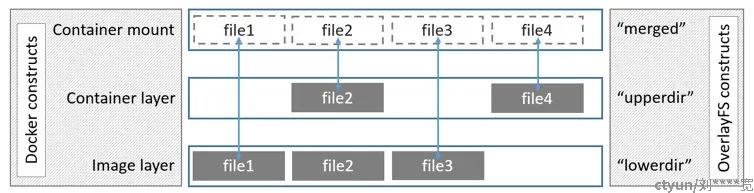
其中 lowerdir 所对应的镜像层( Image layer ),实际上是可以有很多层的,图中只画了一层。
细心的小伙伴可能会发现,图中并没有出现 workdir ,它究竟是如何工作的呢?
我们可以从读写的视角来理解,对于读的情况:
- 文件在 upperdir ,直接读取
- 文件不在 upperdir ,从 lowerdir 读取,会产生非常小的性能开销
- 文件同时存在 upperdir 和 lowerdir 中,从 upperdir 读取(upperdir 中的文件隐藏了 lowerdir 中的同名文件)
对于写的情况:
- 创建一个新文件,文件在 upperdir 和 lowerdir 中都不存在,则直接在 upperdir 创建
- 修改文件,如果该文件在 upperdir 中存在,则直接修改
- 修改文件,如果该文件在 upperdir 中不存在,将执行 copy_up 操作,把文件从 lowerdir 复制到 upperdir ,后续对该文件的写入操作将对已经复制到 upperdir 的副本文件进行操作。这就是写时复制(copy-on-write)
- 删除文件,如果文件只在 upperdir 存在,则直接删除
- 删除文件,如果文件只在 lowerdir 存在,会在 upperdir 中创建一个同名的空白文件(whiteout file),lowerdir 中的文件不会被删除,因为他们是只读的,但 whiteout file 会阻止它们继续显示
- 删除文件,如果文件在 upperdir 和 lowerdir 中都存在,则先将 upperdir 中的文件删除,再创建一个同名的空白文件(whiteout file)
- 删除目录和删除文件是一致的,会在 upperdir 中创建一个同名的不透明的目录(opaque directory),和 whiteout file 原理一样,opaque directory 会阻止用户继续访问,即便 lowerdir 内的目录仍然存在
说了半天,好像还是没有讲到 workdir 的作用,这得理解一下,毕竟人家在使用过程中对用户是不可见的。
但其实 workdir 的作用不可忽视。想象一下,在删除文件(或目录)的场景下(文件或目录在 upperdir 和 lowerdir 中都存在),对于 lowerdir 而言,倒没什么,毕竟只读,不需要理会,但是对于 upperdir 来讲就不同了。在 upperdir 中,我们要先删除对应的文件,然后才可以创建同名的 whiteout file ,如何保证这两步必须都执行,这就涉及到了原子性操作了。
workdir 是用来进行一些中间操作的,其中就包括了原子性保证。在上面的问题中,完全可以先在 workdir 创建一个同名的 whiteout file ,然后再在 upperdir 上执行两步操作,成功之后,再删除掉 workdir 中的 whiteout file 即可。
而当修改文件时,workdir 也在充当着中间层的作用,当对 upperdir 里面的副本进行修改时,会先放到 workdir ,然后再从 workdir 移到 upperdir 里面去。
