


prometheus与thanos的大规模监控集群存在性能瓶颈,主要体现在两个方面:一是读写不分离,采集和查询都在prometheus端,线上复杂的查询业务可能打挂prometheus导致数据中断;二是集群不易拆分,单台prometheus采集数据量过大时不容易进行业务数据拆分。
VictoriaMetrics集群版具备分布式的特性,读写分离,容易横向扩展,更适合大规模监控场景。结合当前实际的监控需求,对VM进行高可用性改造,下面将详细介绍改造方案。
监控集群的高可用场景
目前监控集群高可用性主要有以下述求:
1. 采集高可用:目前的对于同一原始数据采用两个prometheus实例进行采集。
2. 存储高可用:同一原始数据需要存储在两个物理机上。
VictoriaMetrics原生可以支持采集和存储的高可用性:
1. vmagent多副本采集。vmagent集群,使用一致性哈希,可配置N个实例对同一目标进行数据采集。
2. vminsert多副本写入。vminsert集群,可配置将同一数据分别写入M个vmstorage。
然而,原生的高可用方案将会带来一个问题:由于采集端重复采集了N个数据,而写入端又将每个数据写入M个vmstorage中,这样每个数据将会产生N*M个副本,浪费存储空间,降低查询效率。下面的改造方法可以实现在保证采集和存储高可用的前提下,又能节省存储空间,提升查询效率。
VictoriaMetrics的改造难点
解决监控集群的高可用场景,即vmagent集群采用多副本采集方式,vminsert可以将来自vmagent的多副本数据写入不同的vmstorage中,需要解决以下两个问题:
1. vmagent开启多副本采集,不同vmagent采集的同一时间序列数据可被识别。
2. vminsert可识别来自不同vmagent的同一时间序列数据,并保证将其写入不同的storage中。
以上问题的难点在于:
1. vminsert是无状态的,如何在保持无状态的部署方式时,又能识别数据的来源。
2. 解决问题1后,如何保证当前数据写入的vmstorage与其他vmagent发过来的数据写入的不同。
3. 当vmstorage不可用时,需要对数据重新路由,重路由如何保证问题1和问题2.
4. 需要保证数据均匀的存储在每个vmstorage节点中,不能破坏vminsert原生的哈希算法。
VictoriaMetrics改造方案
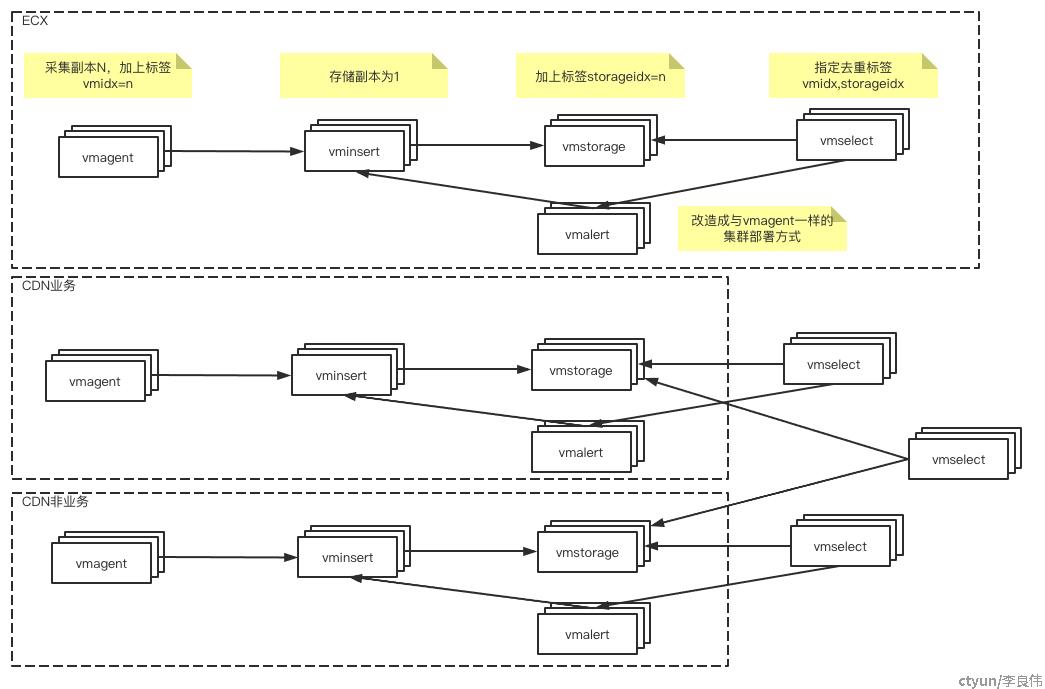
-
设置采集副本为
N。 -
通过一致性哈希计算,在发送到vminsert前,为时间序列数据添加
采集分配的序列号标签。
vminsert
-
修改一致性哈希计算逻辑,先用除
采集分配的序列号之外的标签的哈希值计算使用的storage序列号。 -
根据1求的序列号加上
采集分配的序列号
