


一、后端存储引擎在ceph中的作用
先附上一张ceph IO的流程图:
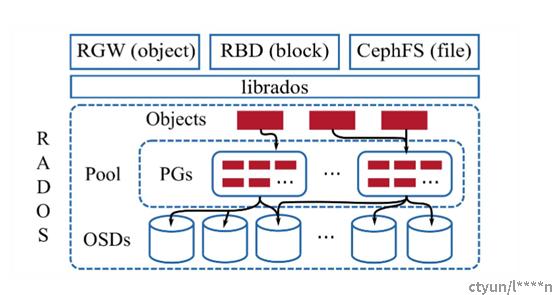
可以看到,IO流程是对象/块/文件请求经过librados,一路走到OSDs。而OSD集群接收到对应的IO请求之后,回根据后端存储类型,执行对应后端存储引擎的IO操作,比如选择了文件系统作为后端存储引擎的话,则会将IO请求转换成文件的读写,最终写入到磁盘/块设备上。
由此可见,后端存储引擎所做的工作就是,OSD将IO请求最终落入到实际磁盘/块设备的流程控制。
二、常用的ceph后端存储引擎
目前ceph常用的后端存储引擎有两个:filestore和bluestore
1、filestore:
filestore的模式下,数据从OSD到DISK的流程如下:

可以看到,在filestore的模式下,数据会经过FS,也就是FileSystem文件系统,最终到达disk。而目前filestore中,常用的文件系统有XFS, EXT4, BTRFS等,关于这几个文件系统的详细介绍,可参考https://zhuanlan.zhihu.com/p/571235218。
filestore的核心是object,改object是作为OSD进程与文件系统的桥梁,负责实际读写数据的交互逻辑。
上面说的是一个整体的数据流程,filestore具体对数据的操作流程可以由下图来描述:
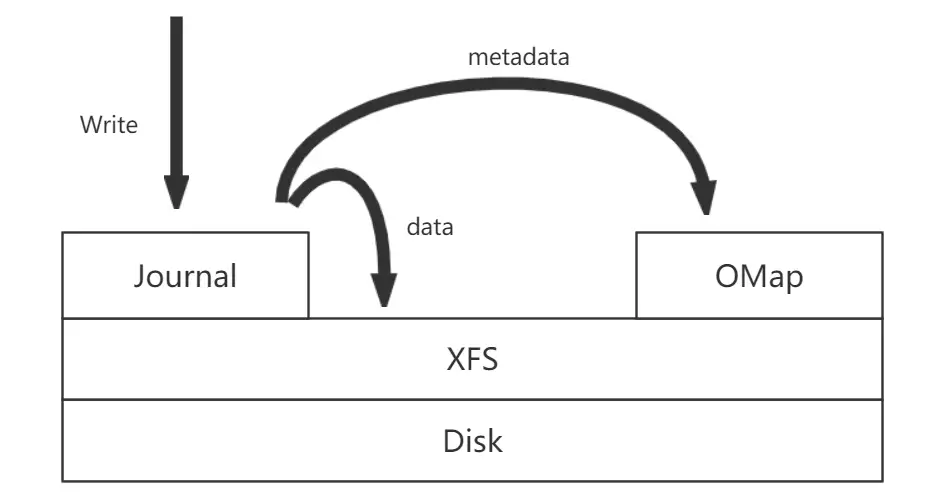
数据都会先写入到journal 也就是日志区。这个操作是同步的,写入到journal成功后会直接返回结果。然后再异步写入到文件。
filestore的这种设计会带来写放大的问题(写放大即是实际写入的数据比要写入的数据更多,从而导致内存空间的浪费等问题)。再加上文件系统本身带来的一些后端引擎性能限制,因此后续架构演化出了bluestore模式。
2、bluestore:
bluestore的流程如下:

bluestore不再使用XFS等本地文件系统,直接实现了一个用户态的文件系统来直接操作块设备(BlockDevice),将对象数据存储在该设备中。提升了ceph集群整体的性能。
bluestore由三个部分构成:
RocksDB、BlueFS以及BlockDevice。
RocksDB: 是一个基于leveldb优化的kv存储系统。
BlueFS: 小型的文件系统(是一个用户态的逻辑,不是在VFS下面的通用文件系统),文件和目录的元数据都缓存再内存中,而数据和日志文件都直接保存在BlockDevice中。
BlockStore: 底层块设备,主要实现了异步写操作。
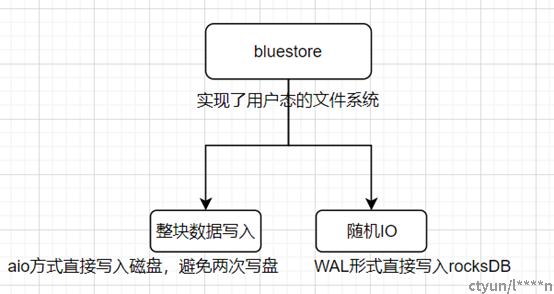
bluestore通过实现这个用户态的文件系统BlueFS,通过aio方式将数据直接写入磁盘,将整块数据写入,避免了filestore里的写放大问题。
