


一直以来,网络协议栈都和内核密切相关,内核作为操作系统的控制者,也是负责网络资源分配的最佳管理者。但随着linux系统的不断壮大,内核协议栈的功能、性能、稳定性都得到了高度认可。但是现在互联网业务蒸蒸日上,本该性能瓶颈的网络传输,被聪明的开发者通过集群、分布式等方式不断优化,将网络业务的力量不断提高。随之而来,linux作为一个调度者,不适宜对外提供业务服务,也不适合占用过多系统资源,无论多么巧妙的开发技巧,都需要面对单点性能瓶颈的问题。而用户态协议栈,可以让linux内核更专注系统的控制调度;将复杂的协议栈处理放到用户态,使用更多的系统资源,提供给开发者更多的自由环境,做更酷的事情。
1 背景介绍
互联网的发展,使得用户对网络应用的性能需求越来越高。人们不断挖掘CPU处理能力加强,添加核的数量,但这并没有使得网络设备的吞吐率线性增加,其中一个原因是内核协议栈成为了限制网络性能提升的瓶颈,缺点如下。
- 互斥上锁引起的开销
互斥上锁是多核平台性能的第一杀手。现在的服务器端应用为了尽可能的实现高并发,通常都是采用多线程的方式监听客户端对服务端口发起的连接请求。首先,这会造成多个线程之间对accept队列的互斥访问。其次,线程间对文件描述符空间的互斥访问也会造成性能下降。
- 报文造成的处理效率低下
内核中协议栈处理数据报文都是逐个处理的, 缺少批量处理的能力。
- 频繁的系统调用引起的负担
频繁的短连接会引起大量的用户态/内核态模式切换,频繁的上下文切换会造成更多的Cache Miss
用户态协议栈-即是将原本由内核完成了协议栈功能上移至用户态实现

图1 内核协议栈与用户态协议栈架构对比图
通过利用已有的高性能Packet IO库 (以DPDK为例)旁路内核,用户态协议栈可以直接收发网络报文,而没有报文处理时用户态/内核态的模式切换。除此之外,由于完全在用户态实现,所以具有更好的可扩展性还是可移植性。
2 态协议栈选型和优化
目前用的比较多的用户态协议栈有VPP、F-Stack、mTCP和SeaStar,通过分析各有优缺点,下表中列出了这四种协议的优缺点等信息。
表1 协议栈对比分析
|
用户态协议栈 |
开发机构 |
license |
编程语言 |
拷贝次数 |
优点 |
缺点 |
|
VPP |
Cisco |
Apache License 2.0 |
C |
2 |
1.BSD风格 socket API+epoll API 2.协议栈功能比较完整 L2:ARP\Vlan等 L3:ICMP\IPV4\IPV6等 L4:TCP\UDP 3.模块化、易扩展,调用程序不感知CPU、DPDK相关资源管理 4.管理工具比较全面 5.源码开放、社区较活跃(fork:456;star:768) |
1.集中转发,存在理论性能瓶颈点 2.VPP与APP间单方向存在2次数据拷贝 3.TCP的flow数上去后,flow之间的调度管理效率低 |
|
F-Stack |
腾讯 |
freeBSD |
C |
1 |
1.BSD风格 socket API+epoll API 2.完整的协议栈功能 3.源码开放、社区活跃(fork:789;star:3.2K) 4.管理工具比较全面 |
1.基于freeBSD(unix)协议栈,函数调用栈深且复杂 2.只支持多进程模式,不支持多线程模式 |
|
mTCP |
韩国某高校科研项目 |
freeBSD |
C |
1 |
1.BSD风格 socket API + epoll API 2.协议栈薄,效率相对较高 3.源码开放、社区次活跃(fork:408;star:1.8K) 4.协议栈功能不完整 L2:ARP L3:ICMP\IPV4 L4:TCP 5.支持多线程模型 6.有部分管理工具如类ifconfig |
1.非run to complete模式;协议栈、socket分布两条线程数据处理存在上下文切换(SPDK可优化) 2.稳定性不高,内部大量锁操作 3.随着连接数增加,内存消耗较大 4.缺乏公网运行案例项目 |
|
SeaStar |
scylladb |
Apache License, Version 2.0 |
C++ (c++ 11/14 feature) |
1 |
1.C++11及以上新特性:Shared-nothing、future-promise-continue高并发架构 2.协议栈功能基本完整 L2:ARP L3:ICMP\IPV4 L4:TCP\UDP 3.支持多线程模型 4. 源码开放, 社区最活跃(fork:1.3K;star:6.7K) |
1.新架构对已有APP及编程难度都较大 2.管理工具缺乏 3.缺乏公网运行案例项目 |
用户态协议栈目前已有一些成熟的应用,我们在自研ESAR的时候,无需从头开始全新设计,可基于开源主流的用户态TCP/IP协议栈进行二测开发。当前使用量比较大用户态协议栈主要包括:VPP、f-stack、mTCP、seastar。由上表可知:这几种开源协议栈除了f-stack都比较适合SPDK的业务模型,根据各自的优缺点我们选择了契合度最高、开发难度相对较小mTCP进行二次开发。从而诞生了我们自研用户态TCP/IP协议栈ESAR。
3 用户态协议栈设计与实现
因为mTCP由于线程模型的一些原因,将会引起一系列的问题,导致性能无法实现线性提升,严重时还会影响APP的整体性能。原因如下:
- mTCP Thread会和APP争抢CPU资源,影响 APP Polling处理效率。
- APP的性能无法随着使用CPU数量的增加实现线性增长。
- 为了实现共享资源访问,需要引入锁,这样会大大降低APP的整体性能。
所以需要对mTCP做去线程化,实现APP的线性可扩展和性能的线性增加。下面是优化前后的对比图
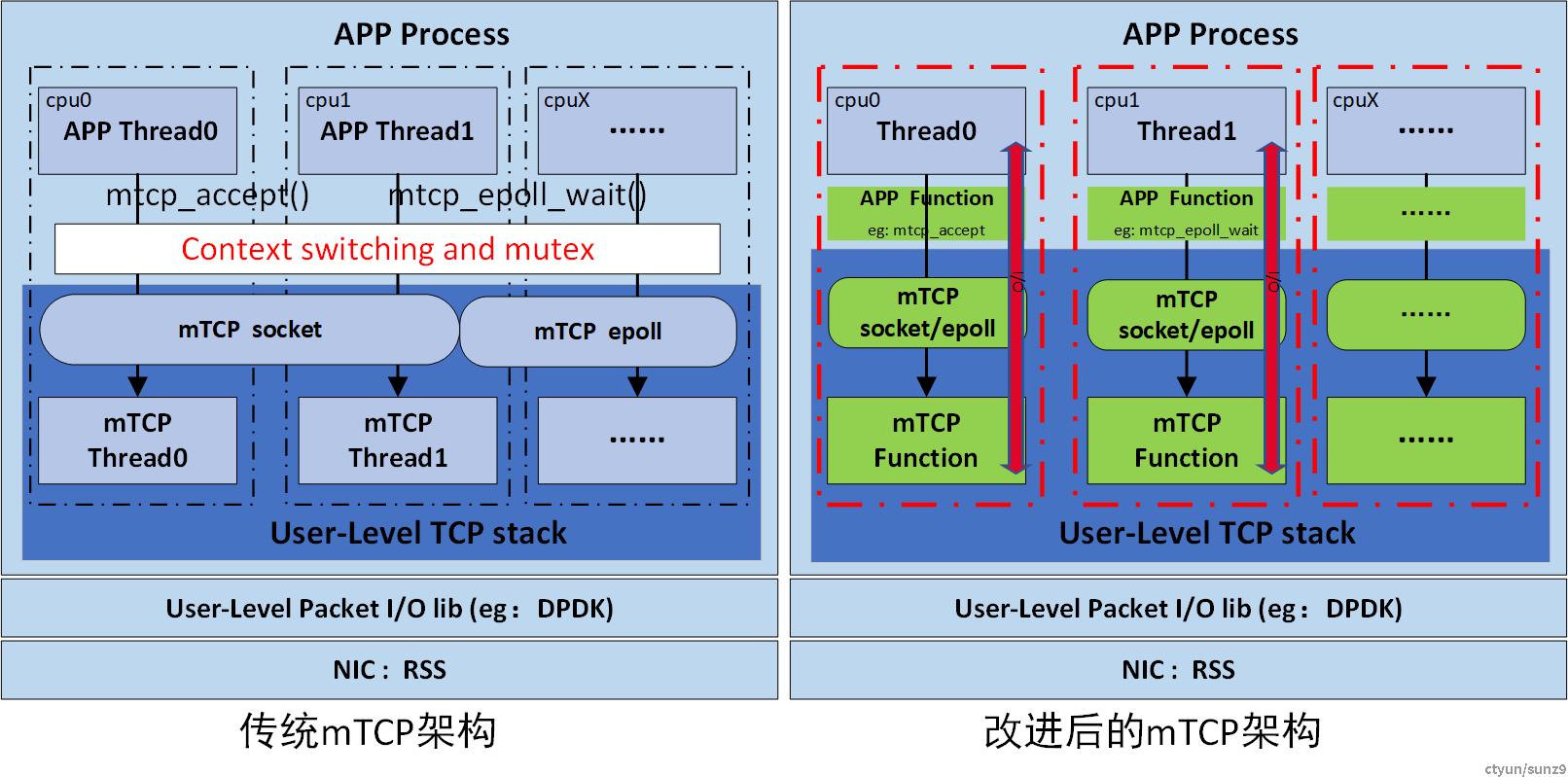
图2 优化前\后mTCP架构图
4. ESAR 之mTCP内部实现
ESAR的内部实现实际上是以lib库及头文件形式对外提供服务,内部没有线程独立运行了,这一点是ESAR相比于开源mTCP优化之后的最大不同。由下图可知,ESAR的生命周期依赖于外部APP线程的生命周期,同时在每个外部线程内创建了一份协议栈的资源,这样核间就无竞争及干扰,可以实现免锁及横向线性扩展。

图3 ESAR协议栈内部结构模型剖析图
ESAR是基于TCP RFC793规范实现,提供了大多数基础的TCP功能,以及常见的socket套接字配置。从上图3模型看,ESAR 实现了以下的相关功能:
-
- 类socket套接字的抽象,对每条TCP流都进行socket的抽象;
- 支持了类epoll的多路IO复用及批事件处理方法;
- 协议栈的消息队列通知机制;
- 配置CPU绑定多线程模型;
- 基本的TCP功能;
从模型上看ESAR其内存管理目前暂时还未实现0拷贝,后期有规划实现0拷贝;同时其线程调度也比较传统,但其高性能的数据传输其实主要依赖于用户态多核架构设计带来性能提升, 主要呈现如下所示:
-
- CPU设置了亲和性,降低了cache miss, 提高了资源利用率;
- 每个线程状态独立,大大降低因线程间信息同步而使用锁带来的性能损失;
- 利用网卡的RSS进行流分类(五元组),确保了每个线程只是处理属于自己的流;
- 用户态应用,降低了传统的socket 系统调用跨态的额外开销;
5. ESAR 的内存管理
当前ESAR的内存管理相比于开源mTCP是经过了重新设计,当前架构是基于未来0拷贝的应用同时兼容当前拷贝而设计。以下从发送、接收两个方面来介绍ESAR协议栈的内存管理。
5.1 发送方向
ESAR下行数据BUF的管理采用了sgl链式结构管理,payload与网络头hdr分开管理,如下图4所示,这样设计payload既可以使用APP中data存放内存,也可以协议栈内部新开辟内存,用于拷贝APP的data;此外hdr 与payload 分开便于网络头的动态构建无需考虑预留空间大小的问题。

图4 ESAR下行网络IO报文数据BUFF的管理模型
ESAR在发送数据包的过程中,上层传递下来的数据或许会超过协议栈每次允许的最大传输分片,那么这时候,协议栈就需要对数据进行分片以满足底层传输需求。如下图所示,为了避免对数据buff的拷贝,在内存管理上我们引入了引用计数的技术,这里主要是Ctbuf的管理,当然这个Ctbuf既可以是APP层面传下来的数据buf,也可以是协议栈内部开辟buf存放上层数据的空间。总之引用计数是设计在ctbuf里面的, 对于未来0拷贝,APP内部传输数据需要使用ctbuf管理的内存。
如图5所示假设APP需要传输1024*1024B的数据,由于MSS限制,这1MB的数据需要切片成1024*1024/MSS个分片,如下图中Seg1至SegN,
同时1MB的Ctbuf每切片一次其引用计数加1;当这些Seg数据片收到了对端的确认报文后对应Ctbuf的引用计数减1, 只有引用计数为0时,对应Ctbuf才能够释放。
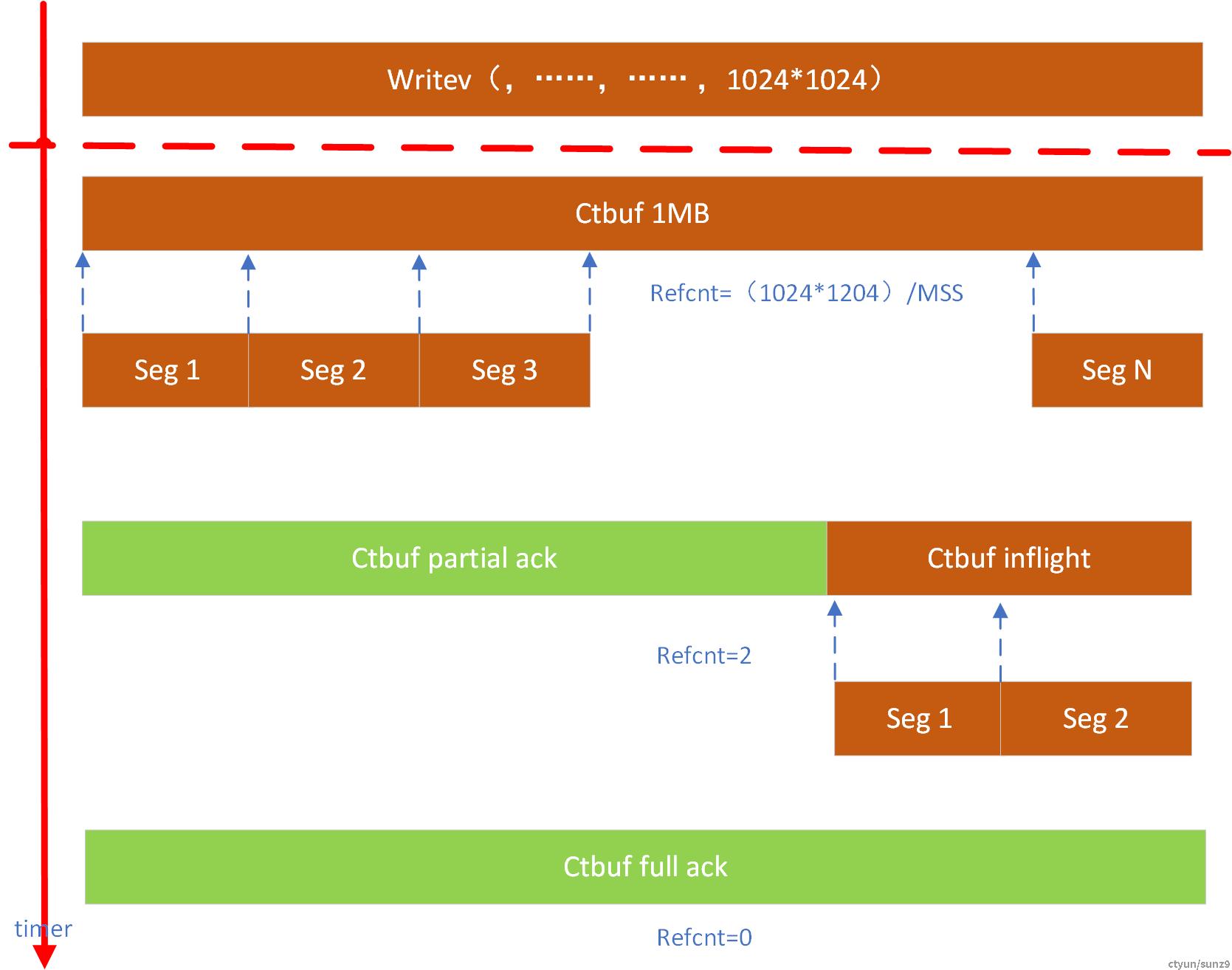
图5 ESAR 下行网络包分片管理逻辑图
5.2 接收方向
对于接收方向,网卡的BD环需要提前挂载BUF,为接收数据做好准备;相比于TX方向,接收方向的数据hdr+payload存放在同一个buf内部。网卡DMA数据时直接将数据写入这些BUF内部,交由DPDK驱动及ESAR协议栈处理,这个过程中数据BUF都是地址传递没有拷贝。协议栈处理完即将交付APP时,有两种操作方式其一是把数据拷贝到APP的存储空间,其二是将协议栈的数据地址直接交由APP处理。 是否需要拷贝,这里主要依赖于APP的业务场景及内存使用。

图6 ESAR上行内存管理逻辑
6. 使用场景
6.1 用户态协议栈在机头部分的应用
这是用户态协议栈第一个应用场景,其中智能网卡的SPDK侧会使用到用户态协议栈来提升网络处理能力。在智能网卡侧CPU性能较弱的场景下,较大幅度提升IOPS。

图7 用户态协议栈应用在机头示意图
6.2 用户态协议栈应用于机头和存储集群
此场景不仅在智能网卡内部使用用户态协议栈来加速网络处理能力,还在存储集群内部的数据链路中也使用了用户态协议栈,加速了数据包在服务器之间的流转速率,提升了整体架构的IO处理能力。

图8 用户态协议栈应用在机头和存储集群内部示意图
6.3 用户态协议栈在机头、GateWay和存储集群全部应用
此场景目前是线上的一个应用场景,其中GateWay用来做智能网卡侧的IO数据转发和加速处理。

图9 用户态协议栈应用在机头、Gateway和存储集群内部示意图
