


人脸检测模型:Sample and Computation Redistribution for Effificient Face Detection(SCRFD)
虽然人脸检测已有显著进展,但实现低成本、高精度的检测仍是一大挑战。SCRFD发现训练数据采样和计算分布策略是关键所在,所以介绍了两种方法:样本再分配(SR)和计算再分配(CR)。SR根据需求增加训练样本,CR通过精确搜索在模型各部分间重新分配计算资源。SCRFD在widerface上的实验显示,该方法在效率和精度上达到了最佳平衡。特别是,SCRFD-34g在性能上超越了顶级对手TinaFace 3.86%,在GPU上处理速度是TinaFace的三倍以上。因此本文章对SCRFD模型进行全面的测评,通过迭代优化SCRFD-10g模型,对比SCRFD-10g在各项任务中与大模型SCRFD-34g的差距,以便后续通过蒸馏学习技术对SCRFD-10g模型进行优化。
一、评测SCRFD在widerface数据下Easy/Medium/Hard条件下的人脸检测准确率;
1.数据集介绍:
Widerface Easy/Medium/Hard的定义:
Widerface 参照 KITTI 和 MALF 数据集原则,基于 EdgeBox 检测率设定了三个难度级别:‘简单'、‘中等' 和 ‘困难'(如图 3(a) 所示)。这三个级别的平均召回率分别为92%,76%和34%,每张图片大约有8,000个候选区域。
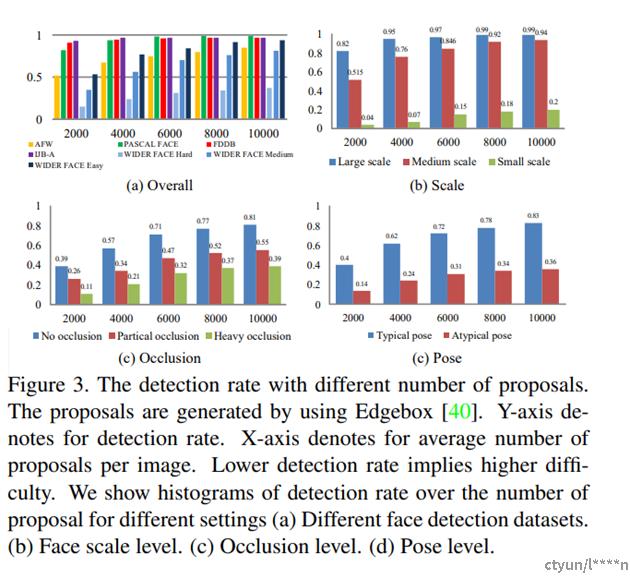
在论文《WIDER FACE: A Face Detection Benchmark》中,WIDER FACE的多维标签属性通过通用对象提议方法(generic object proposal approaches)进行评估。通过比较提议生成数量与相应的人脸检出率,对WIDER FACE的难度和潜在检测性能进行初步分析。特别地,使用效率和准确度俱佳的EdgeBox方法生成提议。图3展示了不同数量的提议生成对各场景人脸检出率的影响,检出率越低意味着难度越大。图3(a)显示,EdgeBox在WIDER FACE上的检出率较低,说明WIDER FACE人脸检测难度超过其他数据集。基于EdgeBox的检出率,WIDER FACE被分为三个难度级别:Easy、Medium、Hard,难度逐级提高。此外,论文中还强调WIDER FACE包含的事件也分为三类:简单(41-60类)、中等(21-40类)和困难(1-20类)。
2. SCRFD在Widerface上的定量评价:
我们对SCRFD-10g人脸检测小模型进行迭代优化,其精度可达到:
|
|
EASY |
Medium |
Hard |
|
SCRFD-10g-640 |
0.958455 |
0.948152 |
0.839529 |
论文公开的scrfd-10g,其精度为:
|
|
EASY |
Medium |
Hard |
|
SCRFD-10g-model |
0.951453 |
0.938704 |
0.830510 |
网上公开的scrfd-34g,精度为:
|
|
EASY |
Medium |
Hard |
|
SCRFD-34g-model |
0.960578 |
0.949162 |
0.853228 |
从定量评价上,可以看出目前迭代优化的SCRFD-10g-640有一定的优势,但与大模型SCRFD-34g存在一定的差距。
3. SCRFD在Widerface上的定性评价:
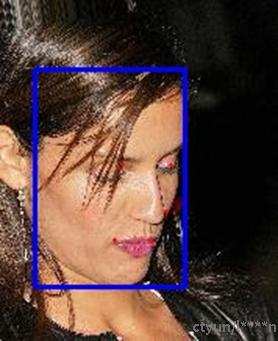
由于目前公开的WIDER FACE数据集按事件而非难度级别(Easy、Medium、Hard)分类,且数据标签中未提及此类指标。因此,我们依据论文描述:“WIDER FACE事件分为简单(41-60类)、中等(21-40类)和困难(1-20类)”进行定性视觉评估。由于图像众多,这里只展示部分示例。图中,蓝色框表示bbox,红色框标识人脸的五个关键点。
- Easy类:
游泳:



汽车:



目前展示了这三个场景,可以看出在人脸尺寸较大,人脸没有遮挡,且与背景差异性较大的情况下,人脸检测率很高。
- Medium 类
在展示的中等难度场景中,即便人脸特征不如简单场景那样明显(如侧脸、丰富表情、戴帽子或墨镜),只要人脸尺寸足够大,仍能准确检测。然而,面对表情复杂(例如拔河)、光照影响显著、或人脸清晰度较低的情况时,检测效果会受限。
- Hard 类:
在Hard类场景中,尽管图片中人脸数量增多且尺寸较小,迭代后的SCRFD-10g模型依然能够有效检测出这些人脸。即使面对照片模糊、人脸严重虚化或被拳头遮挡的情况,该模型也能准确地标出人脸的bbox框。然而,关键点(kps)的准确度在这些复杂场景下可能会降低。
4. SCRFD对Widerface不同尺寸的真实框(gt框)精度评估
将测试图片转换为输入网络大小[640,640]后,测试模型ground_truth人脸框在小于32,32-64,64-128和大于128这四种情况在Easy, Medium, Hard下的检测精度。
不同尺寸人脸测试结果
用我们迭代优化的scrfd10g对不同人脸尺寸数据集进行测试,并且分easy,medium和hard这三种情况进行讨论。
|
模型-人脸尺寸大小 |
Easy |
Medium |
Hard |
|
Scrfd10g_32 |
0.923774 |
0.928430 |
0.811809 |
|
Scrfd10g_32-64 |
0.948256 |
0.943090 |
0.854678 |
|
Scrfd10g_64-128 |
0.961580 |
0.947727 |
0.861867 |
|
Scrfd10g_128 |
0.971628 |
0.962651 |
0.893349 |
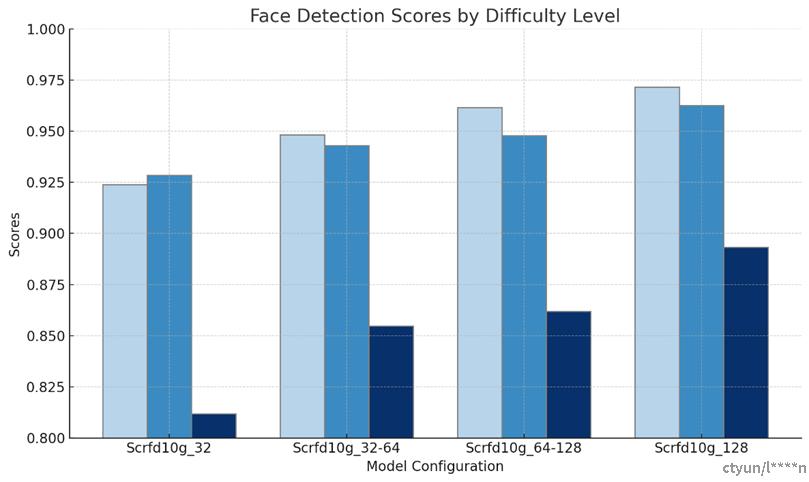
根据图表和表格,可以总结出,随着人脸尺寸的增加,例如大于128×128像素时,人脸检测的精度显著提高,这表明更大的尺寸有助于提高检测的准确性。相对地,当人脸尺寸较小,如小于32×32像素时,检测精度明显降低。此外,当人脸尺寸较小的话(<32*32),在“Easy”和“Medium”难度级别下的精度分数相差不大,说明在这两个级别下,模型的性能较为接近。但是,在“Hard”难度级别下,所有尺寸的精度都有所下降,尤其是在小尺寸人脸检测中,精度下降更为显著。说明在复杂条件下,尤其是面对小尺寸人脸时,人脸检测算法的难度更大。
二、评测不同光照、分辨率情况下的人脸检测;
参考UFDD涉及关键的退化或条件,包括:雨、雪、雾霾、镜头障碍、模糊、照明变化和干扰物;UFDD数据集共有8类数据集,分别是distractor,focus,haze,illumination,lens,motion,rain,snow。
1. SCRFD在UFDD数据集上的定量评价:
计算得到的APS为:
|
|
SCRFD-10g-640 |
SCRFD-10g |
|
APS |
0.751548 |
0.72825 |
可以看出目前迭代的SCRFD-10g-640在UFDD数据集测试精度优于公开模型SCRFD-10g。
分数据集人脸检测精度测试:
|
数据集 |
Rain (628) |
Lens (95) |
Focus (205) |
Illumination(612) |
Motion (312) |
Snow (680) |
Haze (442) |
Distractor(3450) |
|
SCRFD-10g-560 |
0.771322 |
0.703527 |
0.895009 |
0.804205 |
0.884043 |
0.739425 |
0.721766 |
nan |
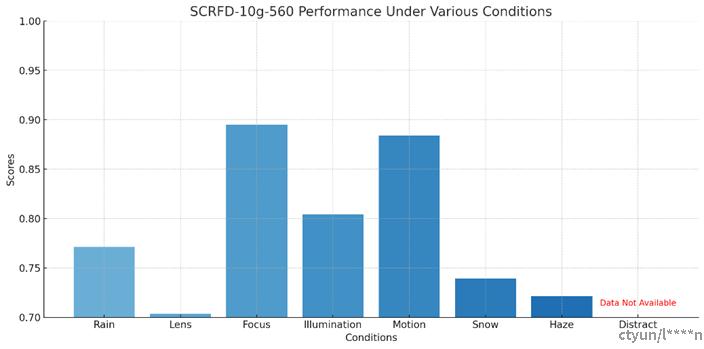
从定量结果分析来看,Rain、Focus、Illumination和Motion这四个数据集的平均精确度得分(APS)高于整体平均水平。而Lens、Snow和Haze这三个数据集的APS则低于平均水平,其中Lens(水汽遮挡)的精度最低,这一点与后续的定性评估结果是一致的。值得注意的是,虽然Haze和Snow在定性评估中显示出较好的质量(在这些条件下仍能够进行有效人脸检测),但在实际的精度计算中表现不佳。同理,尽管Illumination在后续的视觉评估中表现欠佳,但在定量评价指标上的精度却相当高,位列第二。
2. SCRFD在UFDD数据集上的定性评价:
- 负样本图像均检测不出人脸(Distractor):



说明该模型对负样本图像具有一定判别能力。
- 人脸虚焦数据集(focus):


可以看出,目前模型在人脸虚焦的情况下也可以较好地检测出人脸和人脸的关键点坐标,这和定量评价情况是相同的。
- 薄雾条件下(haze):


薄雾情况下,人脸检测的精度也较好,bbox对人脸都进行了标注,且kps目测对齐度也很高,但是在定量评价,人间检测精度表现很低。
- 光照情况(illumination):



光照条件对人脸检测精度有显著影响,通常情况下检测效果较差。但在定量评估中,由于测试集中光照条件下的样本较多(共612张)但强光下的人脸样本较少,整体检测精度相对较高。
- 水汽遮挡(lens):
(1)人脸清晰度较高的情况:


在水汽遮挡不严重的情况下,我们可以肉眼看到人脸的大部分轮廓,模型检测精度还是可以的。
(2)人脸清晰度低的情况:



在水汽遮挡严重,我们肉眼观察人脸轮廓较为困难,模型会出现检测不出人脸,误检和少检人脸的情况。同样,在定量评价指标中,lens条件下的人脸检测精度最低。
- Motion数据集(人脸虚化的情况):



对于人脸虚化的数据集,目前迭代的模型基本上可以正确地检测人脸,与定量评价情况相同。
- 下雨中的人脸数据集(rain):



可以看出,对于下雨的人脸数据集,目前迭代的模型基本上可以正确对人脸进行标注,但用手遮挡大部分面部或侧着角度过大的人脸,都无法检测出。
- 下雪中的人脸数据集(snow):


可以看出,下雪数据集的人脸检测程度与下雨数据集相似,但在定量评价指标中,下雪情况下人脸检测精度要低于下雨条件下的人脸检测。
总结,目前对于UFDD数据集,迭代的模型在光照,水汽遮挡严重,人脸遮挡较多的情况,检测存在一定的难度,后续可以在这三个方面进行模型的增强训练。
三、人脸检测关键点的评测;
1.数据集的介绍:
(1)300-W数据集,包含68个人脸检测关键点,关键点是如图所示:

这种人脸观测点虽然比较详细,但是与SCRFD人脸检测测出的关键点不同,我们没法计算定量指标。
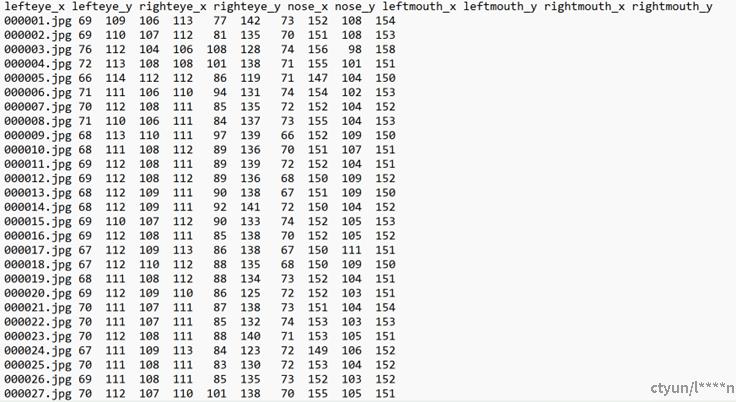
(2)CelebA数据集:在文献中发现了一个由香港中文大学提供的大规模名人脸部特征数据集——Large-scale CelebFaces Attributes (CelebA) Dataset。这个数据集广泛应用于人脸相关的计算机视觉任务,适用于人脸属性识别、人脸检测及关键点(landmark)标记等。包含10,177位名人的202,599张人脸图片,每张图均有详细标记,涵盖人脸bbox、5个关键点坐标和40种属性。每张图仅包含一张人脸。本研究仅关注KPS精度测试,因此只下载了landmark部分数据。鉴于数据集体量庞大,分为15个压缩包,本次实验只将其中一个压缩包内的137张图片及其对应标签上传至服务器进行初步测试。标签格式如下:
但需要质疑的是,它提供的所有参考坐标都是整数,但其实真实的坐标肯定是浮点数,我觉得这会对最后测出的精度有一定的影响。例如,在将第一幅图的KPS坐标导入后,与模型推理得出的结果相比,我发现右眼的点坐标参考标签精度并不高(如左图所示,蓝色点未准确对准右眼)。


KPS标签 推理出的KPS
2. 人脸关键点精度计算:
模型的关键点检测精度为:
|
|
SCRFD-10g-640 |
SCRFD-10g |
|
KPS 平均l1 loss |
1.2343 |
1.3824 |
虽然存在前述标准参考标签坐标精度不足的问题,但通过比较两个模型的KPS loss,可以看出SCRFD-10g-560在测试精度上具有明显优势。
3. 人脸关键点定性测试:
由于CelebA数据集比较简单,图像尺寸不大,且只包含一个人脸,当人脸姿势(pose)是正视的情况下,检测的精度较高。



但如果人脸是侧着的,闭眼或者有帽子遮挡的,检测出的kps存在一定的偏差。


四、评测不同遮挡情况下的人脸检测;
(参考MAFA,Detecting Masked Faces in the Wild with LLE CNNs,)
1. 数据集的介绍:
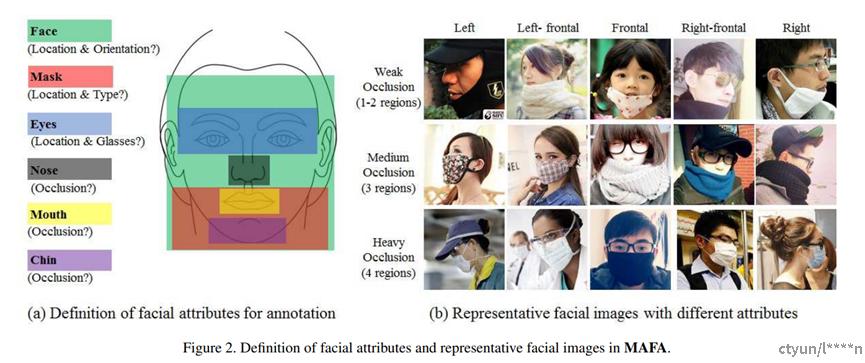
遮挡人脸检测数据集MAFA,出自论文CVPR2017_LLE-CNNs。该数据集有30811张图像,35806个遮挡人脸,图像中的人脸有各种朝向和遮挡程度,且每张图像中最少有一个人脸被遮挡。每个遮挡人脸还包含6个属性:locations of faces(就是bbox)、eyes、masks、face orientation、occlusion degree、mask type,都做了人工标定,并9个人做交叉校验;在高度遮挡的人脸中,大部分人脸属性都会被遮挡区域淹没,且遮挡区域形式各异,类内差异性极大。
其中,遮挡程度Occlusion degree将人脸划分为4个主要区域:eyes、nose、mouth、chin,基于这4个区域被遮挡的情况,划分为3个级别的遮挡:
- Weak Occlusion:1-2个区域被遮挡;
- Medium Occlusion:3个区域被遮挡;
- Heavy Occlusion:4个区域被遮挡;
Mask type:分为4种遮挡类型:
- Simple Mask:人为地纯色遮挡 ---- man-made objects with pure color,翻译成:人为的,略微有点不恰当,可以理解成:人为有意地遮挡;
- Complex Mask:人为地复杂纹理或logo的遮挡;
- Human Body: 被手、头发等人体部件的遮挡;
- Hybrid Mask:1 ~ 3中同时存在的2个以上情况的遮挡;或1 ~ 3中存在1个情况的遮挡 + 眼睛被眼镜遮挡;
2. SCRFD在MAFA数据集上的定量评价:
MAFA数据集包含的信息很多,这里我们只对bbox检测精度进行计算,结果如下:
|
模型 |
人脸检测精度 |
|
Scrfd-34g(公开) |
0.8885174 |
|
Scrfd-10g-640 |
0.8775076 |
|
Scrfd-10g(公开) |
0.8755488 |
根据表格的数据,对于口罩遮挡的人脸,人脸检测精度确实较低。即便是大型模型如 Scrfd-34g,在口罩遮挡场景下的人脸检测精度也未能达到 0.9 的阈值。此外,训练得到的 Scrfd-10g-640 模型与网络上公开的 Scrfd-10g 模型在检测口罩遮挡人脸方面表现出了相似的精度,分别为 0.8775076 和 0.8755488。这表明在口罩遮挡的复杂场景中,即使模型的规模有所不同,人脸检测精度仍然受到一定的限制,而模型规模的增加并没有显著提高检测精度。这可能意味着对于复杂场景的人脸检测任务,需要更专门的训练数据或算法优化来提高模型的表现。
3. SCRFD在MAFA数据集上的定性评价:
- 当人脸姿势是正视的情况:




人脸检测的精度是很好的,bbox标注正确,kps眼睛,鼻子基本标注正确,只是嘴部可能标注的不对,因为口罩遮挡,确实不好判断嘴部的位置。
- 当人脸姿势是正视侧着的情况:




这种情况,也是可以准确检测出人脸,但是可以明显看到眼睛的kps基本是正确的(除了最后一张图,整个kps都是错误的),鼻子和嘴巴的kps精度都很低。
五、不同score threshold对人脸检测精度的影响:
Score threshold [置信度门限]:表示进行预测时被保留的预测框应该达到的置信度门限值,我们设置了不同的score threshold,在相同的数据集(widerface上进行测试),发现当阈值>0.5以后,模型人脸检测的精度很低,没有参考价值,所以我们把score threshold的上限设为0.5。我们通过thresholds = torch.linspace(0.01, 0.5, 10),对阈值进行循环,测试不同score threshold下,scrfd-10g-640epoch的人脸检测精度情况:
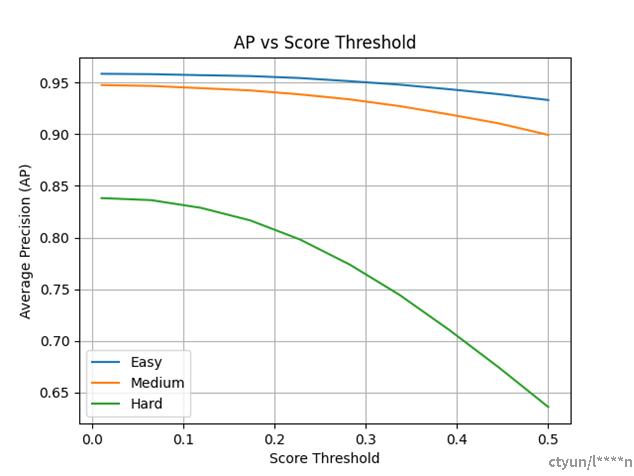
这张图显示了不同难度级别(简单、中等、困难)的平均精度(AP)与分数阈值之间的关系。从图中可以看出:
对于简单样本(蓝色线),AP在分数阈值从0到0.5的范围内保持相对稳定,表明即使改变阈值,对简单样本的检测准确性也几乎不受影响。
中等样本(橙色线):中等难度的AP略低于简单难度,但随着分数阈值的增加,AP略有下降。这表明对于中等难度样本,提高分数阈值可能会轻微影响检测的准确性。
困难样本(绿色线):对于困难样本,AP从0.8左右开始,随着分数阈值的增加显著下降,到0.5的分数阈值时降至约0.7。这表明高难度样本的检测受分数阈值影响较大,当阈值提高时,可能会有更多的真正例被误判为负例,导致准确性下降。
总的来说,这个图表表明对于简单样本,模型在不同的分数阈值下都能保持较高的检测准确性,而对于困难样本,准确性则显著依赖于分数阈值的选择。这通常是因为困难样本可能更难以区分,因此模型对它们的预测信心(即分数)较低。当增加判定为正例的分数阈值时,模型越来越难以将这些困难样本正确分类。
六、低质量下的SCRFD人脸检测的评测
以下所有测试都是在wider face数据集上进行测试:
1. 把图像缩小到1/4再还原
这种方法涉及以下两个步骤:
(1)缩小图像:将图像的尺寸缩小到原始尺寸的1/4。在这个过程中,图像中的很多细节信息会丢失,因为每个新的像素点是原始图像中多个像素点的平均值或其他形式的聚合结果。
(2)放大图像:再将这个缩小后的图像放大回原来的尺寸。这个步骤中使用的是插值方法,如最近邻插值、双线性插值或双三次插值等,来估算缺失的像素值。
本脚本使用的插值方法是“Lanczos”重采样(也称为Lanczos插值)。Lanczos插值使用了称为“sinc”函数的数学窗口函数,适用于图像缩小和放大的场景,相比于简单的插值方法,可以较好地保持图像的细节和清晰度。
降低图像质量具体表现为:
(1)模糊:由于细节丢失,图像可能看起来比原始图像更模糊。
(2)锐度下降:图像的锐度会降低,特别是在图像的边缘和纹理部分。
 (原图)
(原图)  (降质后)
(降质后)
人脸检测测试结果:
- SCRFD-10g-640:
|
|
Easy |
Medium |
Hard |
|
原数据 |
0.958623 |
0.94768 |
0.838108 |
|
降质后数据 |
0.952264 |
0.927946 |
0.705353 |
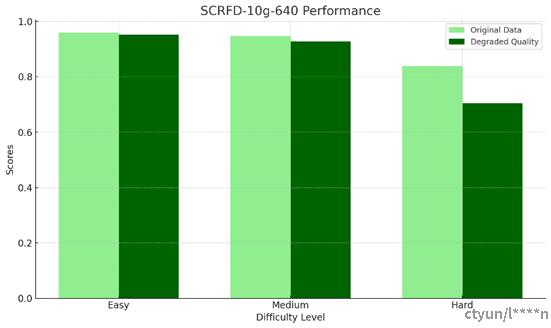
在“Easy”难度级别下,测试图像降质后数据的检测精度略有下降,但仍然保持在较高水平。
在“Medium”难度级别下,降质后数据的检测精度进一步下降,且下降幅度比“Easy”难度时大。
在“Hard”难度级别下,降质后数据的检测精度下降明显。
总体来说,图像质量的降低对人脸检测精度有明显的负面影响,尤其是在“Hard”难度级别下,这可能是因为在更困难的情况下,检测算法需要更多的细节来准确识别人脸特征。我们对公开标准的scrfd34g和scrfd10g进行测试
- SCRFD-34g:
|
|
Easy |
Medium |
Hard |
|
原数据 |
0.960578 |
0.949162 |
0.853228 |
|
降质后数据 |
0.953176 |
0.930969 |
0.730162 |
- SCRFD-10g:
|
|
Easy |
Medium |
Hard |
|
原数据 |
0.951453 |
0.938704 |
0.830510 |
|
降质后数据 |
0.943699 |
0.920050 |
0.715928 |
情况与上述SCRFD-10g-640测试分析的情况相同。
2. 把图像存储为低质量jpeg再读取
这种方法的具体步骤如下:
压缩:在保存JPEG图像时,可以选择一个质量参数,该参数通常在0(最低质量,最大压缩)到100(最佳质量,最小压缩)之间。较低的质量参数意味着图像数据更加紧凑,但也会丢失更多的信息,参数值越低,图像质量越差。本脚本设置参数quality=25。
色彩和细节损失:JPEG压缩过程中,会丢弃一些视觉上不太显著的细节和颜色信息。这包括对颜色空间的降采样和离散余弦变换(DCT)的使用,后者将图像分割成小块,并且只保留这些块中的关键信息。
阻塞效应:在较低的质量设置下,JPEG图像可能会出现明显的“块状”效应,这是由于压缩算法在每个8x8像素的块中分析和存储数据造成的。
重新读取:当低质量JPEG图像被读取和显示时,由于原始图像数据已经丢失,这些损失是不可逆的,导致图像质量降低,表现为模糊、细节缺失和/或块状效应。
降低图像质量具体表现为:
 (原图)
(原图)  (降质后)
(降质后)
人脸检测测试结果:
- SCRFD-10g-640:
|
|
Easy |
Medium |
Hard |
|
原数据 |
0.958623 |
0.94768 |
0.838108 |
|
缩小1/4降质后数据 |
0.952264 |
0.927946 |
0.705353 |
|
存储jpeg再读取 |
0.952036 |
0.938465 |
0.814392 |
- SCRFD-34g:
|
|
Easy |
Medium |
Hard |
|
原数据 |
0.960578 |
0.949162 |
0.853228 |
|
缩小1/4降质后数据 |
0.953176 |
0.930969 |
0.730162 |
|
存储jpeg再读取 |
0.955110 |
0.940626 |
0.829570 |
3. SCRFD-10g:
|
|
Easy |
Medium |
Hard |
|
原数据 |
0.951453 |
0.938704 |
0.830510 |
|
缩小1/4后降质后数据 |
0.943699 |
0.920050 |
0.715928 |
|
存储jpeg再读取 |
0.946670 |
0.931920 |
0.810017 |
分析这些数据可以发现,图像质量的降低确实影响了人脸检测的精度,特别是在Hard难度等级上。低质量JPEG图像相对于缩小再放大的图像,其精度下降较小,这可能是因为低质量JPEG存储方法主要丢失的是高频细节,而对于人脸检测的关键特征可能还能保留。而图像缩小再放大的处理,则会导致更多的细节丢失,影响模型捕捉到的人脸特征,尤其是在图像中的人脸较小或较不清晰时。
3. 将测试图像进行高斯模糊处理
高斯模糊降低图像质量的主要表现在于图像的锐利度和细节丢失。img.filter(ImageFilter.GaussianBlur(blur_radius))将高斯模糊滤波器应用于图像,其中blur_radius指定了模糊的半径。这个值越大,模糊效果越明显,图像越模糊,本脚本将模糊半径设置为2。
降低图像质量具体表现为:


原图 降质后
人脸检测测试结果:
- SCRFD-10g-640:
|
|
Easy |
Medium |
Hard |
|
原数据 |
0.958623 |
0.94768 |
0.838108 |
|
缩小1/4降质后数据 |
0.952264 |
0.927946 |
0.705353 |
|
存储jpeg再读取 |
0.952036 |
0.938465 |
0.814392 |
|
高斯模糊 |
0.951724 |
0.926233 |
0.699495 |
2. SCRFD-34g:
|
|
Easy |
Medium |
Hard |
|
原数据 |
0.960578 |
0.949162 |
0.853228 |
|
缩小1/4降质后数据 |
0.953176 |
0.930969 |
0.730162 |
|
存储jpeg再读取 |
0.955110 |
0.940626 |
0.829570 |
|
高斯模糊 |
0.953497 |
0.930730 |
0.725107 |
3. SCRFD-10g:
|
|
Easy |
Medium |
Hard |
|
原数据 |
0.951453 |
0.938704 |
0.830510 |
|
缩小1/4后降质后数据 |
0.943699 |
0.920050 |
0.715928 |
|
存储jpeg再读取 |
0.946670 |
0.931920 |
0.810017 |
|
高斯模糊 |
0.944237 |
0.919327 |
0.702192 |
4. 将测试图像进行motion模糊处理
在脚本中定义了motion_blur_and_save_image函数,用于模拟motion模糊效果。因为,Pillow库没有内置的motion模糊滤波器,所以设定函数在图像上应用一系列的水平位移,然后将这些位移后的图像进行混合以模拟motion模糊的效果。具体操作步骤如下:
- 打开原始图像;
- 创建空白图像;
- 应用位移和混合:在循环中,ImageChops.offset(img, i, 0)对原始图像应用了水平位移。i是位移的像素数,向左位移为负值,向右位移为正值。使用Image.blend(blurred_img, shifted_img, alpha)将每个位移后的图像(shifted_img)与之前的混合图像(blurred_img)按一定的比例(alpha)混合。alpha是混合因子,由位移范围决定,确保每个位移图像在最终混合结果中的权重相等。
- 保存处理后的图像。
通过这种方法,每个水平位移都模拟了图像在短时间内移动的效果。位移的范围越大,模拟的motion速度越快,模糊效果越强。最终的图像是所有位移图像的平均,从而产生了motion模糊的视觉效果。
降低图像质量具体表现为:

原图 降质后的图像
人脸检测测试结果:
SCRFD-10g-640:
|
|
Easy |
Medium |
Hard |
|
原数据 |
0.958623 |
0.94768 |
0.838108 |
|
缩小1/4降质后数据 |
0.952264 |
0.927946 |
0.705353 |
|
存储jpeg再读取 |
0.952036 |
0.938465 |
0.814392 |
|
高斯模糊 |
0.951724 |
0.926233 |
0.699495 |
|
motion模糊 |
0.938683 |
0.900861 |
0.639724 |
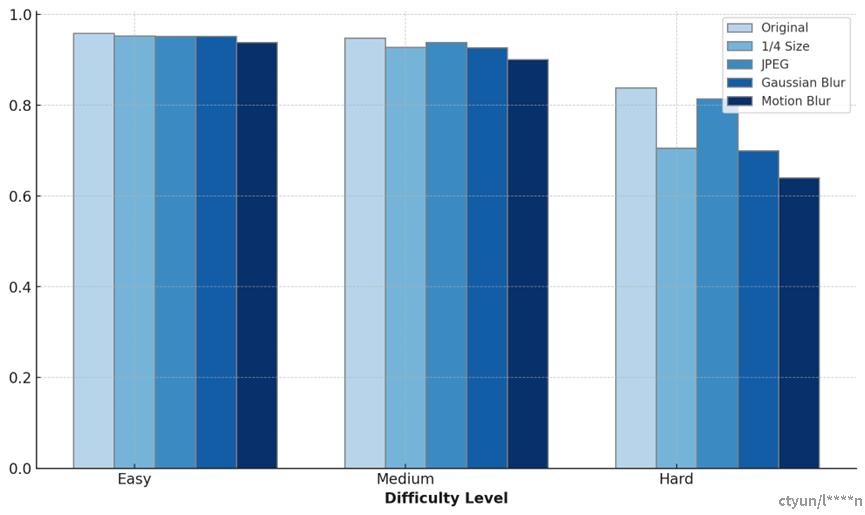
原始图像在所有难度级别下都有较高的精度,而其他处理方法则导致了不同程度的精度下降,尤其是在“Hard”难度级别下,这种下降更为明显。motion模糊处理对精度的影响是最显著的,这可能是因为motion模糊导致了图像中重要特征的严重损失。
SCRFD-34g:
|
|
Easy |
Medium |
Hard |
|
原数据 |
0.960578 |
0.949162 |
0.853228 |
|
缩小1/4降质后数据 |
0.953176 |
0.930969 |
0.730162 |
|
存储jpeg再读取 |
0.955110 |
0.940626 |
0.829570 |
|
高斯模糊 |
0.953497 |
0.930730 |
0.725107 |
|
motion模糊 |
0.941295 |
0.905375 |
0.645401 |
SCRFD-10g:
|
|
Easy |
Medium |
Hard |
|
原数据 |
0.951453 |
0.938704 |
0.830510 |
|
缩小1/4后降质后数据 |
0.943699 |
0.920050 |
0.715928 |
|
存储jpeg再读取 |
0.946670 |
0.931920 |
0.810017 |
|
高斯模糊 |
0.944237 |
0.919327 |
0.702192 |
|
motion模糊 |
0.928067 |
0.887462 |
0.629725 |
七、总结
通过上述六个方面的分析和测评,当前迭代的SCRFD-10g模型在多方面表现良好,但仍逊于SCRFD-34g。后续,我们计划采用模型蒸馏技术,利用大模型辅助小模型提升精度,使SCRFD-10g在保持速度优势的同时,接近SCRFD-34g的性能。此外,考虑将人脸检测小模型与生成大模型技术结合,探索二者的融合可能,通过大模型进行条件图像生成或数据增强,以优化人脸检测模型并提高其精度。
