


悬垂引用
熟悉C的童鞋对下面的例子应该再熟悉不过了:
int* foo() {
int a; // 变量a的作用域开始
a = 100;
return &a; // 变量a作用域结束
}
这段代码通常,作为C学习过程中,关于局部变量的的作用域的一个经典示范案例,广泛被应用于教学说明中。
但对于调用者而言,这便是一个经典的悬垂引用:
一个变量的引用还处于生存期内,但引用指向的实体对象已经消亡。
int* foo() {
int a; // 变量a的作用域开始
a = 100;
return &a; // 变量a作用域结束
}
void test_foo() {
int *ptr = foo();
if (NULL != ptr) {
printf("data=%d\n", *ptr);
}
}
悬垂引用可能会导致非法访问,读取到脏数据,数据踩踏等风险极高的内存安全问题!不幸的是,在C/C++中,悬垂引用在不经意间就会被引入:
(1)返回具备变量引用。
(2)数据记录不同步(结构体中含有指针,在某个流程中已经释放了指针所指的内存,但结构体成员的值没有更新)。
(3)分支流程协同不够细致,在某个异常分支对内存进行释放,而后的流程中未进行相关识别,继续使用。
void process1(data_t* pt)
{
if( condition1)
processx(pt);
else if (err-condition)
destory(pt); // 可能在某个极端场景中,这里就销毁了pt,使的pt变为悬垂引用
}
void main_process()
{
pt = genpt();
process1(pt);
// some other process with pt
process_x(pt);
}(4)异步或并发场景中,因未妥善处理资源竞态而导致悬垂引用。
gtask = NULL;
Producer(ntask)
{
if (gtask != NULL)
destroy(gtask); // 只保留一个task
gtask = ntask;
}
Consumer()
{
task = gtask;
gtask = NULL; // 取走task
if (task != NULL)
process(task);
}上述示例代码中,当Consumer和Producer同时运行时,就可能存在一种状态:producer判断gtask 非空,所有执行了destroy(gtask)以更新gtask;而同时,Consumer成功获取到gtask的引用;当Consumer执行调度时,就会触发悬垂引用问题。
为了避免悬垂引用,在编程过程中,有一些最佳编程实践和一些辅助工具能够帮助我们去尽量规避这类问题;但缺陷源于机制,漏洞总出现在我们意想不到的的地方!以老范的话说,“防不胜防啊”!
借用检查
Rust以内存安全为安身立命之根本,自然不会放任这样的内存安全问题于不顾。Rust引入“借用检测”机制,来避免悬垂引用。见下面的示例:
fn livetime() {
let r;
{
let x = 5;
r = &x;
}
println!("r: {}", r);
}在函数的内部块中,定义了变量x,并且被r所借用,该代码在编译时会报错:
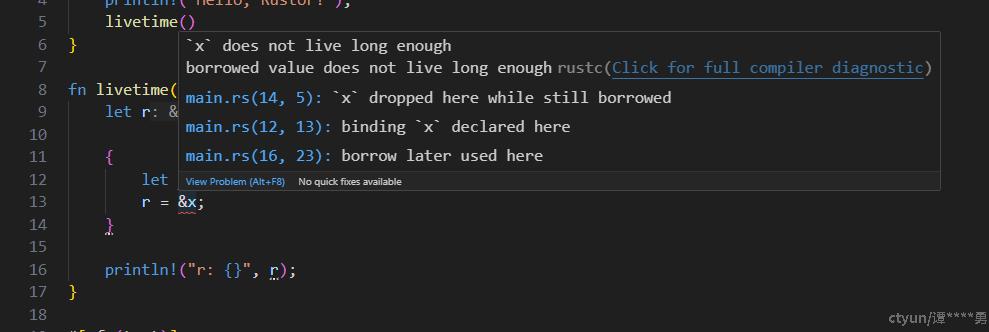
见上截图,错误显示x 生存的时间不够长,x在14行被drop,但其借用在16行还在使用!
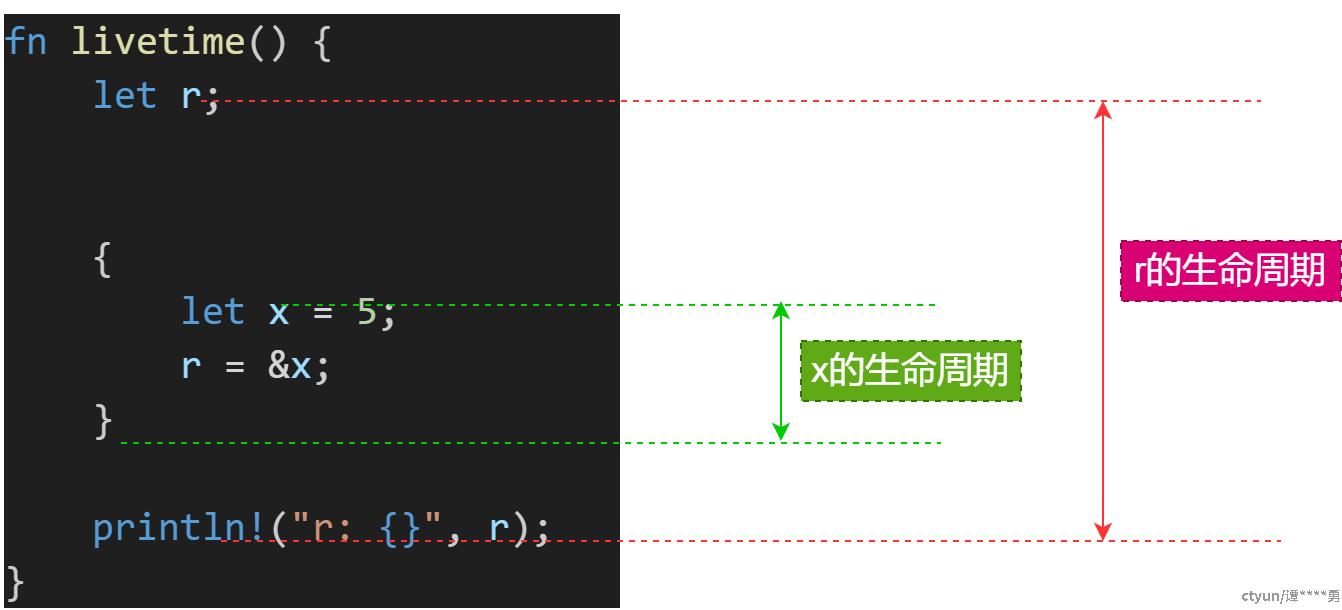
如上图,Rust为每个变量记录其生存范围(生存期/生命周期);当存在借用时,要求借用变量的生命周期必须要在实例变量的生命周期覆盖范围内,确保不会出现悬垂引用!
函数返回引用的生命周期
在一个函数体内部,或者一个语句块内部,因为存在逻辑先后,通常识别每个变量的生命周期是相对容易。但函数调用过程中,由于内部隐藏了处理细节,那么生命周期的识别可能就会变得复杂。
见下面的例子:
fn main() {
let string1 = String::from("abcd");
let string2 = "xyz";
let result = longest(string1.as_str(), string2);
println!("The longest string is {}", result);
}
fn longest(x: &str, y: &str) -> &str {
if x.len() > y.len() {
x
} else {
y
}
}示例中,提供一个函数longest,比较两个字符串(引用),返回较长的一个。
此函数实现很标准优美,就连多余的 return 和分号都没有,并且逻辑清晰,命名合理;当我们还沉浸在这段 longest 优美实现时,现实却毫不留情地给了一记“大鼻兜”:
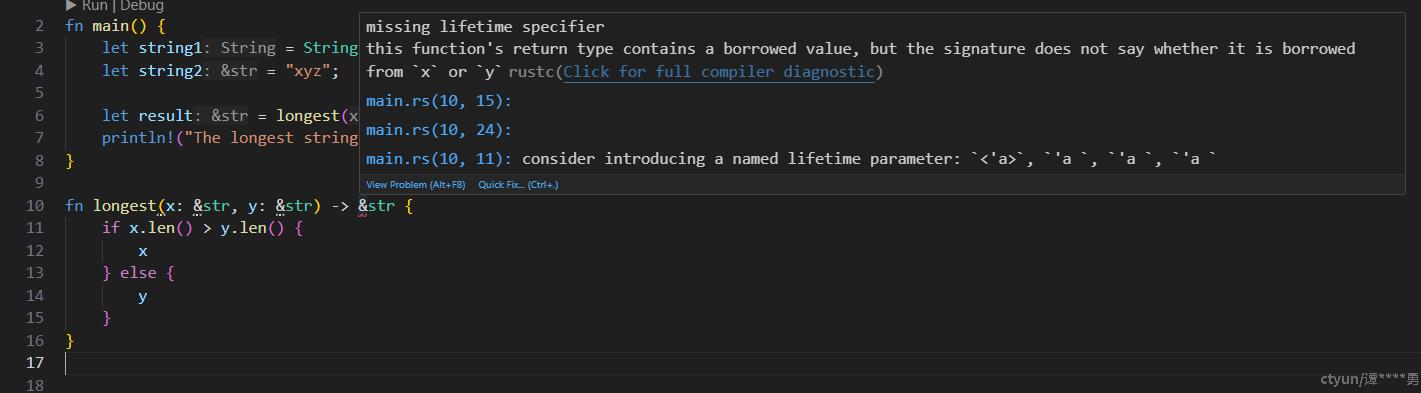
如上截图:代码编译报错了!错误提示:缺少生命周期标注;函数返回一个借用,但从函数签名上,看不出这个借用是来自x或者y......
what are you talking a about?
懵逼完了后,冷静分析一下:这个错误是说,函数返回一个借用,但不清楚这个借用来自x或者是y(屁话,谁不会用百度翻译似的)。为啥需要知道借用来自x和y呢?
结合前一章借用检查的逻辑原理,应该可以推断出来:Rust希望可以明确返回的引用来自于哪个实例变量,从而可以对借用实施借用检查,进而避免悬垂引用的问题!
不过说来尴尬,就这个函数而言,我们也不知道返回值到底引用哪个,因为一个分支返回 x,另一个分支返回 y...这可咋办?先来分析下。
我们在定义该函数时,首先无法知道传递给函数的具体值,因此到底是 if 还是 else 被执行,无从得知。其次,传入引用的具体生命周期也无法知道,因此也不能像之前的例子那样通过分析生命周期来确定引用是否有效。同时,编译器的借用检查也无法推导出返回值的生命周期,因为它不知道 x 和 y 的生命周期跟返回值的生命周期之间的关系是怎样的(说实话,人都搞不清,何况编译器这个大聪明)!
事实上:
Rust需要明确每一个引用和其关联的实体变量的生命周期,以便实施借用检测,来杜绝悬垂引用。Rust编译器会自动推导(后面会讲解)每个借用的生命周期,并自动实施借用检查。
当存在多个借用时,Rust编译器有时会无法自动推导函数返回引用的生命周期,此时就需要我们手动标注的方式,告诉Rust编译器,这个返回引用应该和谁去比较生存长度,从而实施借用检查。
这样就能够理解上面程序的报错:这个函数缺乏一个生命周期标注,来说明返回的引用的生命周期与和x,y的生命周期之间的关系(编译器不知道该和谁去比较,因此干脆报错)!
接下来我们再来了解一下关于生命周期的标注。
生命周期标注
我们先把上面的函数修改正确(通过idel 的quick fix)
fn main() {
let string1 = String::from("abcd");
let string2 = "xyz";
let result = longest(string1.as_str(), string2);
println!("The longest string is {}", result);
}
fn longest<'a>(x: &'a str, y: &'a str) -> &'a str {
if x.len() > y.len() {
x
} else {
y
}
}见上面的程序,在longest的函数中添加签名标记:'a,而‘a就是生命周期标注。
生命周期的语法也颇为与众不同,以 ' 开头,名称往往是一个单独的小写字母,大多数人都用 'a 来作为生命周期的名称。 如果是引用类型的参数,那么生命周期会位于引用符号 & 之后,并用一个空格来将生命周期和引用参数分隔开。
longest生命周期标注的含义:函数签名包括一个生命周期设定‘a’,其中入参x,y都满足‘a’的要求(即,x,y都至少和‘a’活得一样久;反过来说,就是‘a’就是x,y生命周期中较短的一个);同时函数返回的借用,也满足‘a’(即,返回的借用生存期不能长于x,y的任意一个)。
由此可见:生命周期标注,用于告诉Rust编译器,如何确定输入的引用和返回的引用之间生命周期关系,指导编译器进行借用检查。
换句话说:在通过函数签名指定生命周期参数时,我们并没有改变传入引用或者返回引用的真实生命周期,而是告诉编译器当不满足此约束条件时,就拒绝编译通过。
注意:生命周期标注并不会改变任何引用的实际作用域 !!!
注意:生命周期标注并不会改变任何引用的实际作用域 !!!
注意:生命周期标注并不会改变任何引用的实际作用域 !!!
回头再看longest的例子,main函数中result 借用是如何与string1、string2进行生命周期关联的:
fn main() {
let string1 = String::from("abcd");
let string2 = "xyz";
let result = longest(string1.as_str(), string2);
// result 是string1 或者string2 的借用,通过longest函数的生命周期标注,
// 可以明确result的生命周期要求result 必须在string1 和string2生命周期
// 的覆盖范围内。 基于此,借用检查器就可以通过对 string1,string2, reuslt
// 的生存期进行比对,而决策出result借用是否存在悬垂引用的风险
println!("The longest string is {}", result);
}
fn longest<'a>(x: &'a str, y: &'a str) -> &'a str {
if x.len() > y.len() {
x
} else {
y
}
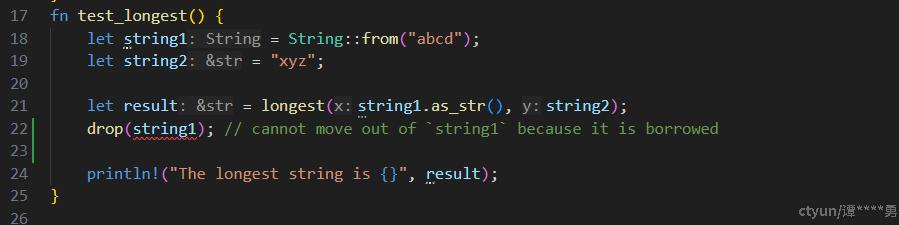
}对比而言,如果我们尝试在result生命周期结束前,drop string1 或者string2,rust借用检测就会报告异常:
生命周期自动推导(消除标记)
在Rust设计实现中,为了方便使用,有一套生命周期自动推导的机制,以简化编码过程(否则每一个有借用入参和返回的函数,都需要进行生命周期标注,是一个挺烦人事情;事实上,早期的Rust编程也是确实需要这么干)。
见下面的示例:
fn first_word(s: &str) -> &str {
let bytes = s.as_bytes();
for (i, &item) in bytes.iter().enumerate() {
if item == b' ' {
return &s[0..i];
}
}
&s[..]
}frist_word 接收一个str引用,同时返回一个引用。但这个函数并不需要进行生命周期标注就可以正常编译。
原因是,这个函数可以自动识别出返回的引用和入参引用应该是具备相同的生命周期。哲学道理如下:
(1)一个函数,如果返回引用,那么只有两种情况:其一,是入参带入的引用,被处理后返回;其二,从函数内部新建了一个引用返回。其中,第二种情况,是典型的悬垂引用,在函数内部就会被借用检测出来。因此,正常而言,返回的引用都是入参传入的引用或者经过相关变化得来的。
(2)如果入参只有一个,那么返回的引用必然就是这入参相关的,那么返回引用的生命周期自然就是入参引用的生命周期!
上面的例子比较通俗的解释了Rust是如何做自动推导的。为了方便表述,Rust中,函数或方法中参数的生命周期被称为“输入生命周期”,而反回值的生命周期被称为“输出生命周期”。
针对函数或者方法,Rust在生命周期自动推导过程中,遵循三条规则():
(1)每一个引用参数都会获得独自的生命周期
例如一个引用参数的函数就有一个生命周期标注: fn foo<'a>(x: &'a i32),两个引用参数的有两个生命周期标注:fn foo<'a, 'b>(x: &'a i32, y: &'b i32), 依此类推。
(2)若只有一个输入生命周期(函数参数中只有一个引用类型),那么该生命周期会被赋给所有的输出生命周期,也就是所有返回值的生命周期都等于该输入生命周期
例如函数 fn foo(x: &i32) -> &i32,x 参数的生命周期会被自动赋给返回值 &i32,因此该函数等同于 fn foo<'a>(x: &'a i32) -> &'a i32
(3)若存在多个输入生命周期,且其中一个是 &self 或 &mut self,则 &self 的生命周期被赋给所有的输出生命周期
拥有 &self 形式的参数,说明该函数是一个 方法,该规则让方法的使用便利度大幅提升。
注意:对于第(3)条,这里是一个默认行为,而不是一个固定或强制行为。意思是,对于一个方法,其含有&self的同时,也可能存在其他引用传入;此时,Rust的借用检查器会默认将所有返回的引用的生命周期与self相比。但确实存在,返回的引用可能是其它传入引用相关的,这反而会导致问题!而解决之道也很简单:用手动标注生命周期的方式,指明输出生命周期正确的依赖!
结合前面的例子,我们再来梳理一遍生命周期的消除,看看站在Rust编译器的角度,是如何实现自动推导的:
案例1:frist_word
函数签名:
fn first_word(s: &str) -> &str {}
step1: 按照自动推导三法则,第一条,对所有输入生命周期进行标注
fn first_word<'a>(s: &'a str) -> &str {}
step2: 尝试用自动推导三法则第二条,推导输出生命周期:由于入参只有一个,所以对所有返回应用相同的生命周期
fn first_word<'a>(s: &'a str) -> &'a str { }
step3:检查所有返回值,是否所有引用类型的返回值,都已经标注了生命周期:满足要求,自动推导成功!
案例2:longest
函数签名:
fn longest(x: &str, y: &str) -> &str {}
step1: 按照自动推导三法则,第一条,对所有输入生命周期进行标注
fn longest<'a, 'b>(x: &'a str, y: &'b str) -> &str {}
step2: 按照自动推导三法则第二条进行自动推导:不满足输入条件
fn longest<'a, 'b>(x: &'a str, y: &'b str) -> &str {}
step3:检查所有输出生命周期是否已经标注了生命周期:不满足
fn longest<'a, 'b>(x: &'a str, y: &'b str) -> &str {}
step4: 按照自动推导三法则第三条进行自动推导:不满足输入条件
fn longest<'a, 'b>(x: &'a str, y: &'b str) -> &str {}
step5:检查所有输出生命周期是否已经标注了生命周期:不满足。
由于已经试用了所有自动推导法则,但任然有输出生命周期未完成标注,因此Rust编译通报错误,需要人为标注生命周期!其它场景的生命周期标注
经过前面几章节的讲解,各位看官大大想必应该对Rust的生命周期、生命周期标注已经有了一些了解。Rust中,除了函数存在生命周期标注,在一些复合数据结构(如结构体)和一些复合数据结构的方法中,同样存在生命周期和生命周期标注;只是它们的作用和原理,与函数基本一致,我就不展开细讲了。主要是考虑到怕看官大大们心生厌烦,嫌弃小编罗里吧嗦.....
那么,就点到为止......
结构体中的生命周期标注
当在结构体中使用引用时,就必须要确保引用在结构体实例的生命周期内保持有效,否则也会导致悬垂访问。
struct StringParser<'a> {
raw_data: &'a str,
}
fn main() {
let raw= String::from("something for parsing....");
let parser = StringParser{
part: &raw,
};
}如上面例子,parse引用了raw 字符串,所以借用检查器,需要确保raw的生命周期一定不能短于parser的生命周期!
方法中的生命周期
struct StringParser<'a> {
raw_data: &'a str,
}
impl<'a> StringParser<'a> {
fn parse(&self) -> String {
let nstr = String:new();
nstr.pust_str("somesthing");
nstr
}
}
其中有几点需要注意的:
(1) impl 中必须使用结构体的完整名称,包括 <'a>,因为生命周期标注也是结构体类型的一部分!
(2) 方法签名中,往往不需要标注生命周期,得益于生命周期消除的第一和第三规则。
静态生命周期标注
在 Rust 中有一个非常特殊的生命周期,那就是 'static,拥有该生命周期的引用可以和整个程序活得一样久。
在之前我们学过字符串字面量,提到过它是被硬编码进 Rust 的二进制文件中,因此这些字符串变量全部具有 'static 的生命周期:
let s: &'static str = "请叫我齐天大圣,主打一个寿与天齐";生命周期通常用于标注全局静态的引用,或者用于解决一些不确定、难以表述的生命周期标注!但,请注意,对一个变量标注了static生命周期,并没有实际改变其生命周期,只是“欺骗”了Rust编译器,让它不要再纠结于该引用的生存期;这样的做法是不推荐的,属于典型的自己挖坑埋自己的“高智商犯罪”(瞒过了所有侦查),望君谨慎!
写(无)在(馆)最(紧)后(要)的话
截至本篇完,Rust几个顶层设计原理、机制相关的内容(除了宏,不太适合初学者深究)差不多捋了一遍,小编觉得理解这些内容对了解和掌握Rust应该有所裨益!
后续,我们讲开始一些实战,也会适时的总结与Rust爱好者分享、探讨,欢迎大家关注、留言、讨论......
