


1.简介
RedisCluster集群是 Redis 提供的一种高可用性解决方案,它通过将数据分片和复制到多个节点来提供高可用性和可扩展性。
高可用性:Redis 集群通过数据分片和复制到多个节点来实现高可用性,即使部分节点发生故障,整个集群仍然可以继续提供服务。
可扩展性:Redis 集群支持横向扩展,可以动态地增加或减少节点,以满足不断增长的需求。
分布式存储:Redis 集群将数据分散存储在多个节点上,每个节点仅负责部分数据,这样可以充分利用集群的整体性能。
2.RedisCluster原理:
- 数据分片:Redis 集群使用哈希槽(hash slots)来分片数据。哈希槽是一个 0 到 16383 的整数集合,每个键都被映射到一个哈希槽中。集群中的每个节点负责管理其中一部分哈希槽,每个槽上存储着一部分数据。
- 节点复制:在 Redis 集群中,每个主节点都会有至少一个从节点进行数据复制。主节点负责处理客户端的读写请求,而从节点则负责复制主节点的数据,并在主节点下线时提供服务。这样即使主节点故障,从节点仍然可以接管服务并继续提供服务。
- 故障检测与自动恢复:Redis 集群通过心跳机制来监测节点的健康状态。如果发现某个主节点不可用,集群会将该节点的槽重新分配到其他节点,并将从节点升级为主节点以继续提供服务。
- 客户端路由:客户端通过集群的路由功能来连接集群。当客户端向集群发送请求时,集群会根据请求的键来计算哈希槽,并将请求路由到负责该槽的节点上。这样可以确保每个键都会被发送到正确的节点上。
3.模拟故障场景
3.1RedisCluster的故障切换原理
CLUSTER FAILOVER处理流程
-
通知master停止处理来自客户端的请求
-
master响应当前最大的replication offset
-
客户端等待复制复制同步完成直到replication offset
-
提升epoch并获取半数leader的选举认可
-
更新configuration并解除客户端的阻塞请求,返回重定向到新的master
该操作用于正常的主从切换,但是如果master节点宕机了无法响应failover请求,那么failover将会失败,为了处理master宕机的情况,可以添加FORCE 选项。
CLUSTER FAILOVER FORCE: 添加FORCE选项时,failover流程直接从上述的第4步开始,也即跳过了和旧master通信协商复制数据的过程,当master宕机时,force选项可以快速进行人工主从切换。但是该过程仍然需要获得半数master的统=同意才能当选为新主。当出现半数master节点异常时,该流程无法进行主从切换。
CLUSTER FAILOVER TAKEOVER: 为了处理半数master节点异常的场景,可以添加****TAKEOVER 选项。通过TAKEOVER 选项,可以无需获得半数master的认同,而是直接更新状态为master并向所有可达的节点发送最新配置epoch。
3.2故障场景模拟
通过故障演练,发现如下场景下RedisCluster无法自动恢复
| (1) redis节点挂掉情况,无法自动拉起 |
| (2) 同时kill 半数以上master节点 |
| (3) 停止redis从节点,停止redis对应主节点,再启动redis从节点 |
| (4) 同时停止三个master主节点,此时启动两个master主节点 |
| (5) 相同槽段master和slave都挂掉 |
4.辅助高可用机制
* Access介入 一般都是集群失效状态(无法完成自动切换的场景)
* 场景一 主节点未宕机 判断master节点数超过一半 CLUSTER FAILOVER 等待数据同步并且投票
* 场景二 主节点未宕机 判断master节点数少于过一半 CLUSTER FAILOVER TAKEOVER 无需投票
* 场景三 主节点已宕机 判断master节点数超过一半 CLUSTER FAILOVER FORCE 不用等待数据同步
* 场景四 主节点已宕机 判断master节点数少于过一半 CLUSTER FAILOVER TAKEOVER
*
* 优先级 cluster failver > cluster failover force > cluster failover takeover
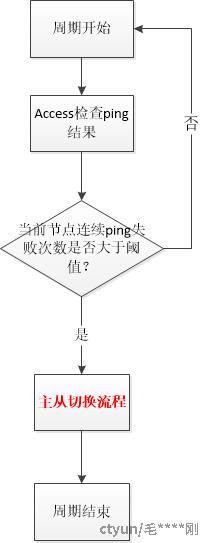
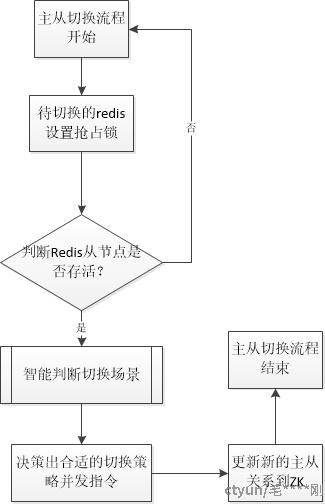
通过Access辅助高可用切换机制,可保证RedisCluster在一些异常发生无法恢复的场景下,通过自定义策略辅助介入,完全高可用切换恢复业务,无需人工参与,大大降低了故障的影响时间。
