


快速概览下 业界几个比较知名的 Rust 来搞 数据库/云数仓的项目。
Datafusion
依托Apache Arrow,目前可以认为是一个单机版的SQL 引擎。
fork 969,star 5.3k , 活跃度很好 。
生态很好,貌似是Apache Arrow 原班/核心成员深度参与其中。
文档很完善,对用户/开发者比较友好、面向 Developer 而非 最终 产品。
比较好的架构分层、扩展点设计,利于二次开发/改造。
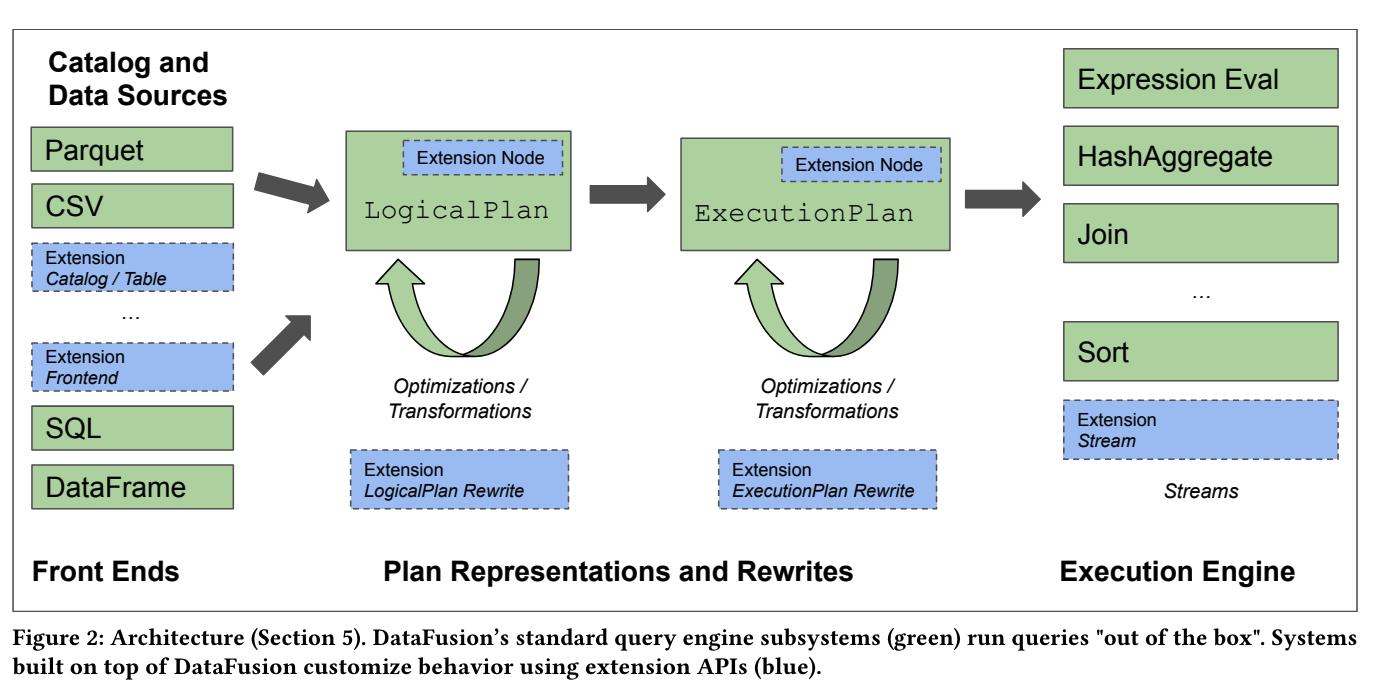
性能相比DuckDB、CK 等会差一些,但由于计算核心还是基于Arrow,差距主要是在Planner 优化这一趴,也在在快速迭代追赶中。
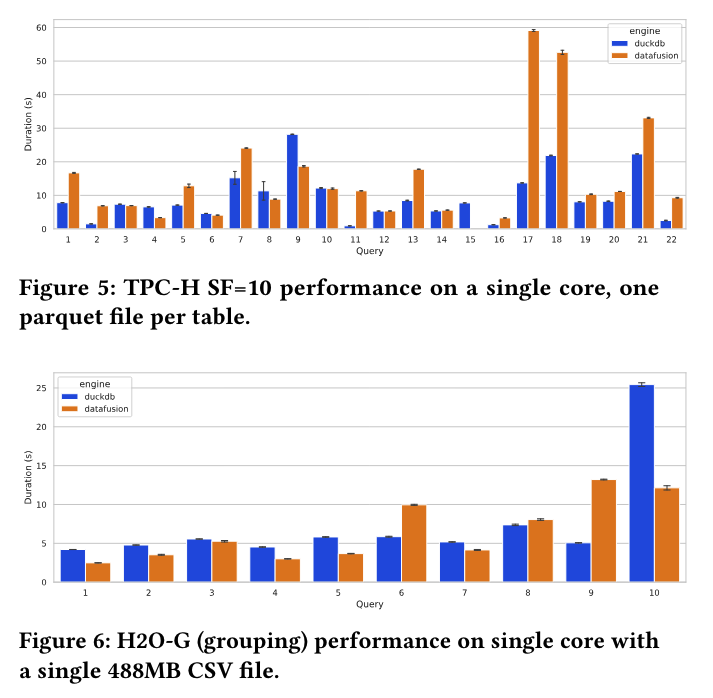
整体来看还是一个很有潜力、可供参考/学习或供改造的项目,而非一个直接面向产品化的项目。
demo 样例:
let ctx = SessionContext::new();
ctx.register_csv("example", "tests/data/example.csv", CsvReadOptions::new()).await?;
// create a plan
let df = ctx.sql("SELECT a, MIN(b) FROM example WHERE a <= b GROUP BY a LIMIT 100").await?;
// execute the plan
let results: Vec<RecordBatch> = df.collect().await?;
// format the results
let pretty_results = arrow::util::pretty::pretty_format_batches(&results)?
.to_string();
let expected = vec![
"+---+----------------+",
"| a | MIN(example.b) |",
"+---+----------------+",
"| 1 | 2 |",
"+---+----------------+"
];
assert_eq!(pretty_results.trim().lines().collect::<Vec<_>>(), expected);
Ballista
看名字就知道了,是基DataFusion 做的分布式版本
180 fork、1.3k star,活跃度不太好
有简单的分布式能力支持、功能也比较有限, 一些几年前的规划都没落地,更新不频繁,计划不明朗。
分布式样例demo:
RUST_LOG=info ./target/release/ballista-scheduler
RUST_LOG=info ./target/release/ballista-executor -c 2 -p 50051
RUST_LOG=info ./target/release/ballista-executor -c 2 -p 50052
use ballista::prelude::*;
use datafusion::prelude::CsvReadOptions;
/// This example demonstrates executing a simple query against an Arrow data source (CSV) and
/// fetching results, using SQL
#[tokio::main]
async fn main() -> Result<()> {
let config = BallistaConfig::builder()
.set("ballista.shuffle.partitions", "4")
.build()?;
let ctx = BallistaContext::remote("localhost", 50050, &config).await?;
// register csv file with the execution context
ctx.register_csv(
"test",
"testdata/aggregate_test_100.csv",
CsvReadOptions::new(),
)
.await?;
// execute the query
let df = ctx
.sql(
"SELECT c1, MIN(c12), MAX(c12) \
FROM test \
WHERE c11 > 0.1 AND c11 < 0.9 \
GROUP BY c1",
)
.await?;
// print the results
df.show().await?;
Ok(())
}
Polars
可以认为就是一个DataFrme/Pandas 的高性能平替。
import polars as pl
from datetime import datetime
df = pl.DataFrame(
{
"integer": [1, 2, 3],
"date": [
datetime(2025, 1, 1),
datetime(2025, 1, 2),
datetime(2025, 1, 3),
],
"float": [4.0, 5.0, 6.0],
"string": ["a", "b", "c"],
}
)
print(df)
感受:
- 生态做的很好,数据可视化、机器学习、矢量数据库等都有对接/支持
- 易用性、易部署,可以快速抓住原有的DataFrame/Pandas 用户,切入点找的很准
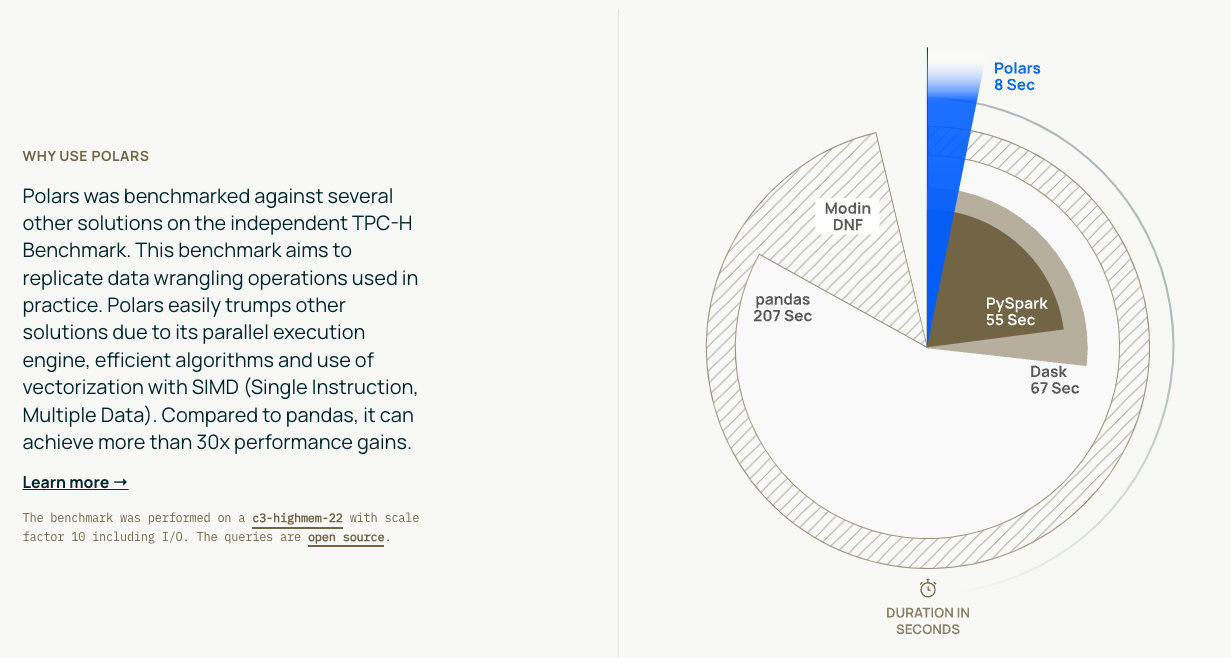
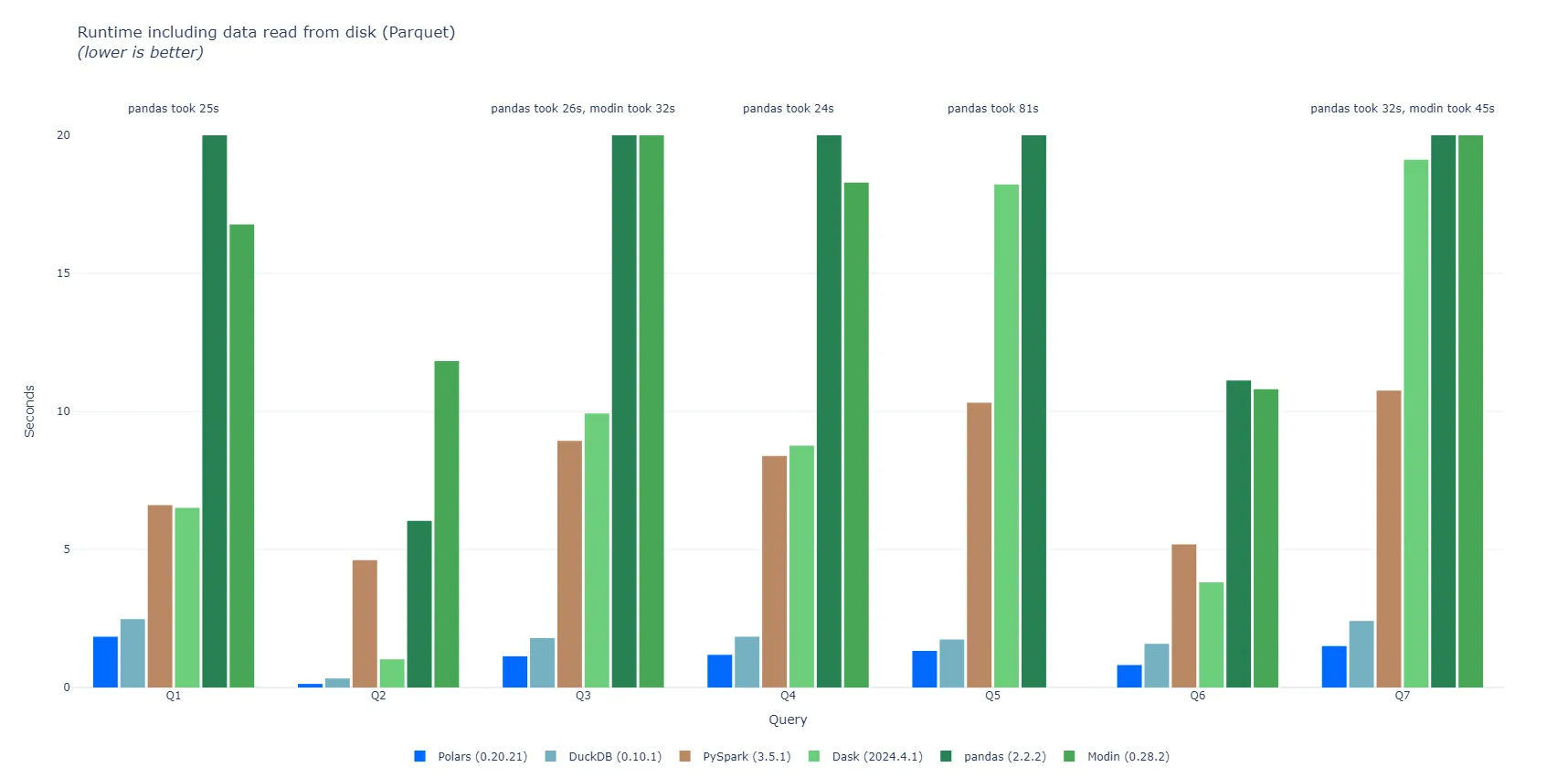
- 性能表现优秀、这方面应该是目前所有类DF 产品中的最强的
- 最近搞了一轮融资,貌似也要开始做OLAP
Databend
fork 704, star 7.3, 社区活跃度很好
目前能跑通基本的TPCH, 离跑通TPCDS 应该还有一大段距离。
源码开放,但有商业化运作、有企业版,且即便开源部分、一部分核心代码仍有版权限制。
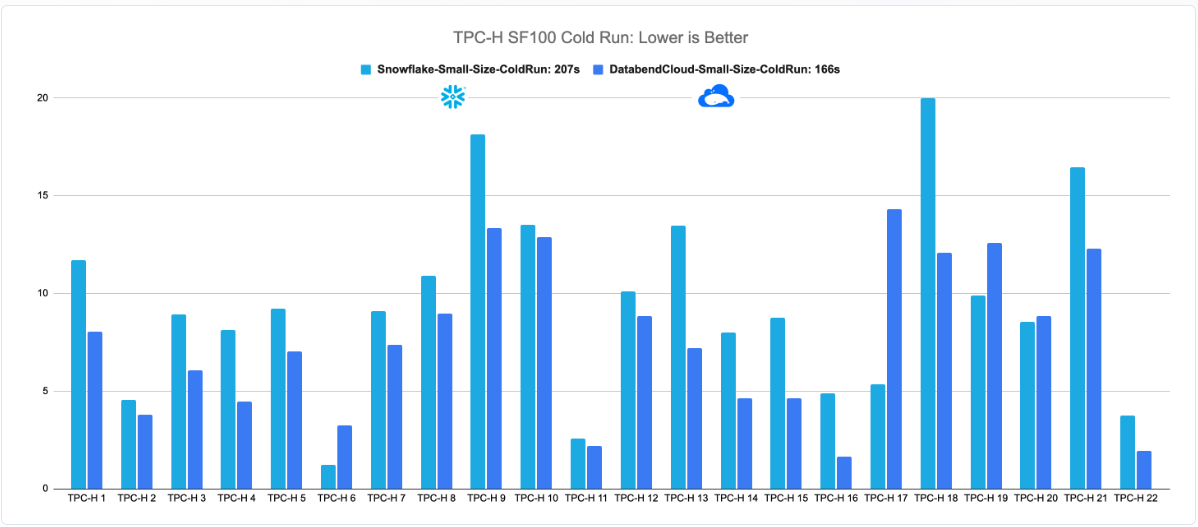
性能做的很快、打榜很给力
Geeker 玩法,貌似有洁癖,整个生态链/依赖库都涉及 Rust重写/改造,cli 都是rust 重新写的、确实让人眼前一亮。
底层存储抽象层 也已单独立项、但进展不是太快。
专有的SQL 客户端、bendsql, 易用性更好、体验更优化
一些功能上比较有新意,内置js/webAssemble 来作为udf 支持:
CREATE FUNCTION gcd_js (INT, INT) RETURNS BIGINT LANGUAGE javascript HANDLER = 'gcd_js' AS $$
export function gcd_js(a, b) {
while (b != 0) {
let t = b;
b = a % b;
a = t;
}
return a;
}
$$
SELECT
number,
gcd_js((number * 3), (number * 6))
FROM
numbers(5)
WHERE
(number > 0)
ORDER BY 1;
py udf 外部支持的方式也比较特殊,由一个独立服务的形式来提供:
@udf(
input_types=["INT", "INT"],
result_type="INT",
skip_null=True,
)
def gcd(x: int, y: int) -> int:
while y != 0:
(x, y) = (y, x % y)
return x
if __name__ == '__main__':
# create an external server listening at '0.0.0.0:8815'
server = UDFServer("0.0.0.0:8815")
# add defined functions
server.add_function(gcd)
# start the external server
server.serve()
周边系统几乎都有Rust 重写,包括存储独立立项的 OpenDAL 项目,对整个Rust 生态有很好的促进作用。
生态支持上还不错,基本的导入/导出/湖仓&catalog 等该有的也有了,
但功能的多样性/丰富性、生态支持、文档丰富程度上, 相比 sr/doris 等还有明显的大段距离。
比较彻底的云原生思路,走在业界各种概念/噱头的最前沿,各种 AI 能力支持也都有一定的涉及。
海外公有云生态做的很不错,体验比较赞,发展势头还是很不错的。
总结
通常来讲,数据库/MPP 几乎都是 C++ 为主,而大数据生态则是Hadoop/Java,Rust 凭借自己的新生代的 语言/能力优势, 在当前处于变革时代的数据库/云数仓领域 目前有很不错的进展、产出了几个明星项目,但相对占据目前主导地位的C++/Java 领域,生态还不够成熟、切入需要比较大的投入成本,Rust 社区本身也还不够成熟,但整体前景还算比较乐观、增量还是不错的, 以开源的形态 来切入、比如Polars、Databend,借助全世界的Geeker 的热情贡献、也是一种很好的商业化推进思路。
