


1. 纠删码的原理和作用
纠删码(Erasure Coding,EC)是一种编码容错技术,最早是在通信行业解决部分数据在传输中的损耗问题。其基本原理就是把传输的信号分段,加入一定的校验再让各段间发生相互关联,即使在传输过程中丢失部分信号,接收端仍然能通过算法将完整的信息计算出来。
纠删码技术中的主要参数为K、M,其中K代表原始数据盘个数或恢复数据需要的磁盘个数,M代表校验盘个数或允许出故障的盘个数。使用编码算法,可以通过K个原始数据生成K+M个新数据,因此可以通过任何K个新数据都能还原出原始的K个数据,即允许M个数据盘出故障,数据仍然不会丢失。纠删码中的写放大为(K+M)/K。比如 K=3 M=2 K+M=5,代表总共会产生5个块,此时写放大为5/3。
目前使用最广范的纠删码是Reed-Solomon纠删码,它的原理如下:
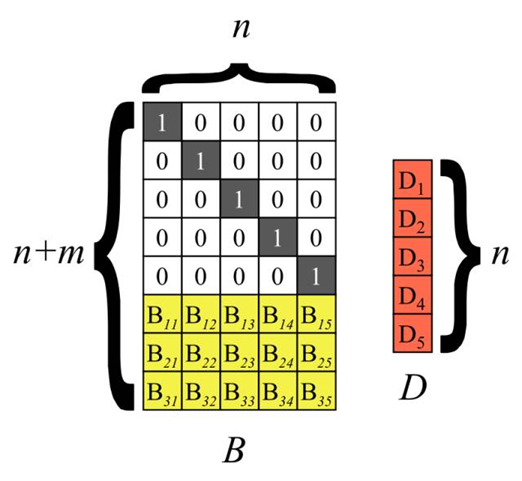
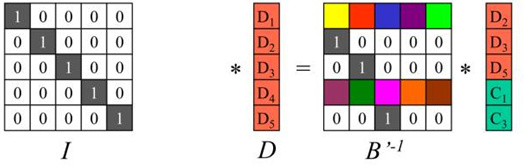
以冗余级别为5+3的纠删码为例说明。将n个源数据块D1~Dn按列排成向量D,再构造一个(n+m)*n矩阵B,B称为分布矩阵。对矩阵B有一个要求:它的任意n个行向量都是相互独立的,即这n个行向量组成的n*n矩阵可逆。矩阵B的前n行是单位矩阵I,后m行一般为特殊矩阵。
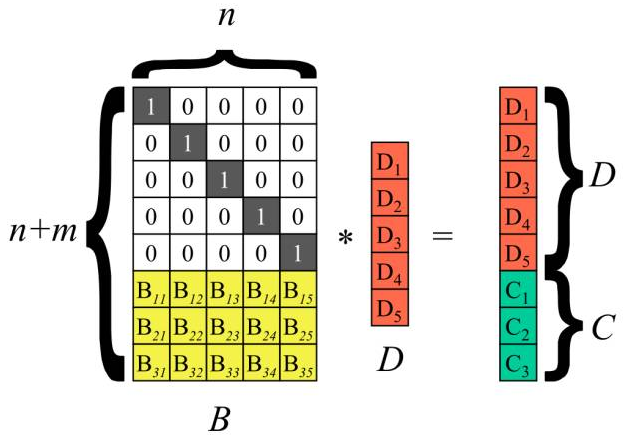
执行矩阵向量乘B*D,得到m个校验块C1~ Cm。
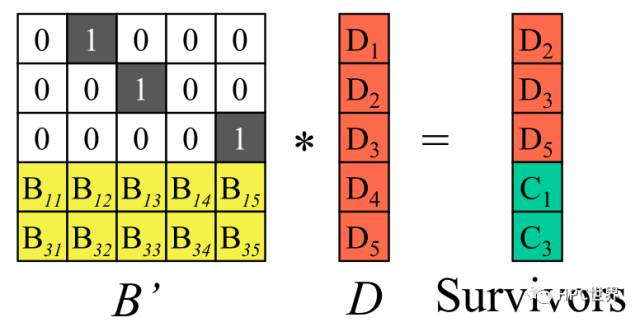
假设m个硬盘发生了故障,即图中的数据块D1、D4、C2丢失,需要从剩下的n个数据块中恢复出来源数据D1~Dn。
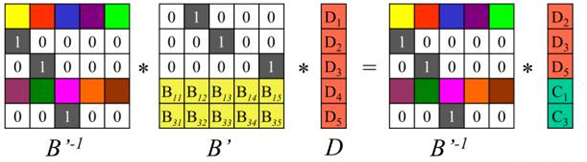
因为B的任意n行组成的矩阵都可逆,所以矩阵B’存在逆矩阵记为B’-1,显然有B’-1*B’=I。将开始等式的左右两边同时左乘矩阵B’-1,就得到了n个源数据块D1~Dn,完成数据恢复。
通常后m行使用范德蒙德矩阵构造。范德蒙德矩阵结构如下:

从矩阵中任取m行即可和单位矩阵构造成分布矩阵B。
在erasure coded pool中,每个数据对象都被存放在K+M块中。对象被分成K个数据库和M个编码块;erasure coded pool的大小被定义成K+M块,每个块存储在一个OSD中;块的顺序号作为object的属性保存在对象中。纠删码的实际存储方式如下图所示。
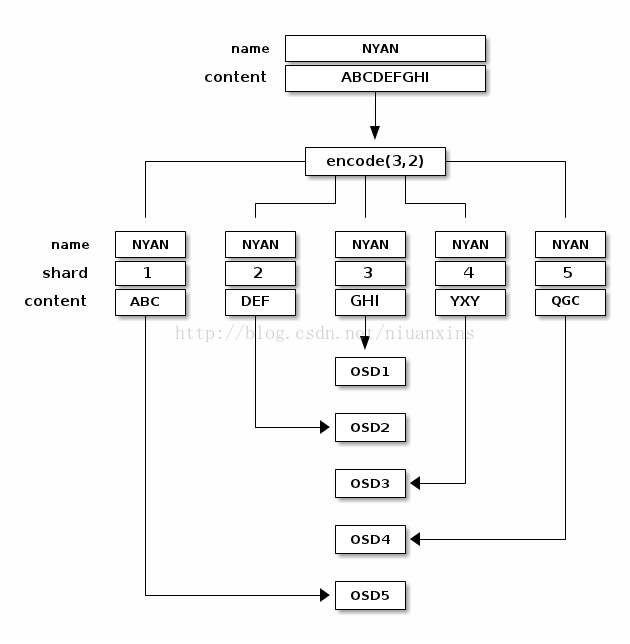
例如:创建5个OSDs (K=3 M=2)的erasure coded pool,允许损坏2个(M = 2);
对象 NYAN 内容是 ABCDEFGHI ;
NYAN写入pool时,纠删码函数把NYAN分3个数据块:第1个是ABC,第2个是DEF,第3个是GHI;如果NYAN的长度不是K的倍数,NYAN会被填充一些内容;纠删码函数也创建2个编码块:第4个是YXY,第5个是GQC;
每个块都被存储在osd中;对象中的块有相同的名字 (NYAN)但存储在不通的osd中。除了名字外,这些块都有一个序号,需要保存在对象属性中 (shard_t)。比如,块1包含ABC保存在OSD5中;块4包含YXY保存在OSD3中。当从erasure coded pool中读取对象NYAN时,纠删码函数读取3个块:块1(ABC)/块3(GHI)/块4(YXY);然后重建原始对象内容ABCDEFGHI;纠删码函数被告知:块2和块5丢失;块5不能读取是因为OSD4损坏了;块3不能读取,是因为OSD2太慢了。
因此由上可知,纠删码的优点主要是实现了高速的计算,相比三副本池减小了写放大,优化了写性能。但有2个缺点,一个是读的时候必须从不同osd中读取不同块并且组合成完整对象,因此读性能较差;另一个是只支持对象的部分操作(如不支持局部写,不支持创建rbd)。目前使用纠删码池作为rbd块设备主要有两种方法:一是创建一个三副本池存储rbd的元数据,使用纠删码做底层数据池;二是使用cache tier ,纠删码池作为三副本池的底层数据池,利用ssd中的三副本池进行加速,能够一定程度上弥补纠删码池读性能差的缺点。纠删码的主要用途有两个:1冷数据较多的池子2廉价多数据中心存储。
2. ceph中纠删码库以及具体配置
2.1 ceph的主要纠删码库
Ceph中主要的纠删码库有以下几种:
Jerasure库,lrc库,isa库,shec库,clay库,其中前三种库使用较为广泛且比较稳定,后两个库因为比较新,某些版本不支持使用。因此使用前三种库进行压测性能对比。
2007年,James基于上述理论研究给出了RS-RAID的一个开源实现,称为Jerasure。Jerasure所实现的纠删码是水平方式的,即需要同时使用k+m块不同的磁盘分别承载数据和校验数据。Jerasure库是ceph默认使用的纠删码库。
ISA插件是由Intel公司提供的纠删码开源解决方案(BSD授权),其核心算法部分采用的是汇编语言,同时针对Intel公司的CPU做过指令集层面的优化,相比Jerasure插件,在进行纠删码编解码时,ISA能够显著降低所需要的硬件资源消耗,同时有效降低编解码时长,强化了写性能。
LRC和EC的不同在于,EC只有两种类型的chunk,data chunk和code chunk, 其中每个code chunk都是其他所有的data chunk的线性组合,也就是每个code chunk和其他所有的data chunk都是有关系的,称之为global code chunk。LRC和EC不同的地方在于,LRC多了一种local code chunk,local code chunk和global code chunk的不同在于,local code chunk只与部分data chunk有关系,而global code chunk和所有的data chunk都有关系。LRC构造如下例子:
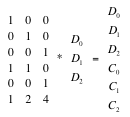
图中C0和C1均可由少于三个块构造,并加入了一个C2来保证所有块都有联系。这样能够减少读时候的性能损失,因为可以仅读取少于k个osd来构建块。Lrc的主要参数有k,m,l,其中l为新参数,代表每个局部组的osd数量,即可用l个osd恢复原来的块,l必须能被k+m整除。
2.2 ceph纠删码配置
想使用纠删码库,首先需要设定一个纠删码规则,例如:
ceph osd erasure-code-profile set myj k=4 m=2 ruleset-failure-domain=osd plugin=jerasure
利用规则生成纠删码池
ceph osd pool create ecpool 512 512 erasure myj
设置纠删码开启覆盖写,这个功能不开启无法在池上创建rbd。
ceph osd pool set ecpool allow_ec_overwrites true
另外纠删码不能单独创建rbd,此时有两种选择:创建一个三副本池作为元数据池,或者使用ssd来组成cache tier
