


前一阵子同事在上线项目部署多实例时,发现数据库中的id发生了冲突,该项目的id生成逻辑使用了雪花算法,并且需要设置dataCenterId和machineId,由于dataCenterId和machineId写死导致了id生成冲突。
由此总结一下分布式id的一些常见解法,和以往项目中的一些实践。
什么是分布式id
几乎所有系统都有生成唯一标识的需求,如:
userId、orderId、msgId等等
我们往往会把这个id设置为数据库的主键,数据库会在该主键上建立聚集索引
通常情况下我们还会根据其他普通索引来查询记录,如:
select * from order where time >xxx
select * from order order by time limit 100
在time字段上建立普通索引,会使得查询效率更高些,但是普通索引存储的并不是真正的数据而是实际数据的主键,因此通过普通索引查找数据比直接使用聚集索引效率更低些
由此我们得出分布式id的两大需求:
1、全局唯一
2、全局递增
分布式id常见解决方案
方案一:数据库自增
得最常见的方案就是使用数据库的自增来实现分布式id的生成
优点:
1、简单、实现成本低
2、保证唯一性
3、保证递增
缺点:
1、数据库单点可用性问题,通常情况下数据库时一主多从,读写分离,主库挂了就完蛋
2、数据库单点性能和扩展问题,单主库的情况下,只有一个数据库负责生成id,很容易成为性能瓶颈、并且难以扩展
要解决上述缺点可采用如下的优化方案:
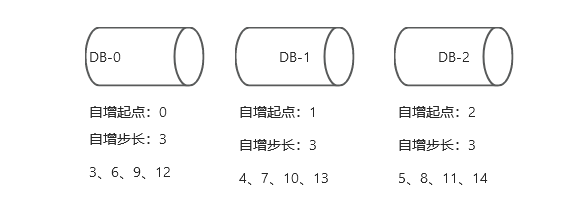
引入多主库,每个主库设置不同的自增起点,并设置相同的自增步长,这样便可实现不同主库生产不同的主键
该优化方案并非银弹,存在有这些问题:
1、id并非绝对递增。想象一个场景:同一个用户,一个请求先请求到1数据库生成了1,3两个id,一个请求请求到2数据库生成了2,4两个id,可以看出id并非绝对的递增。
2、数据库压力依然不小,因为每次生产id都需要访问数据库(后端开发的宗旨:请求能尽量在上游解决就不要传递到数据库,毕竟无状态的应用服务层扩展起来可比数据库扩展简单多了)
方案二:id生成服务
由上述方案一的优化方案依然存在的问题
1、id递增问题:分布式系统之所以头疼,很大的一个原因是因为没有一个全局时钟,要想保证绝对的时序,还是得用单点服务,用本地时钟保证绝对时序
2、数据库的压力问题:可以采用批量获取的方式,避免每次生成id都访问数据库
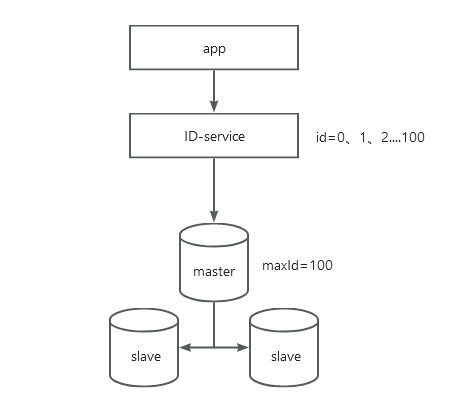
如上图,ID-service每次更新数据库中的maxId,如maxId=100,这样相当于ID-service每次提前获取了了100个id,上层调用ID-service获取id时,ID-service按顺序分配id即可,用完了这批次的id就再次更新数据库中的maxId从而获取下一批次的id,无需每次生成id都访问数据库,极大降低数据库的压力。
优点:
1、有序递增
2、数据库压力小
3、可方便的水平扩展
缺点:
1、ID-service多实例时, 生成的ID 非绝对递增的,而是趋势递增
2、生成的id可能会不连续,ID-service重启时,上一批已生成未分配的id会被弃用,从而产生id不连续
附上以往项目中的实现:
private long syncGetId() {
if (segments[index()].getMiddle() <= currentId.longValue() && shouldLoadNextSegment()) {
try {
lock.lock();
// ID使用超过50%并且没有加载下一片段,直接加载下一片段
if (segments[index()].getMiddle() <= currentId.longValue() && shouldLoadNextSegment()) {
loadingNextSegment();
}
} finally {
lock.unlock();
}
}
if (segments[index()].getMax() <= currentId.longValue()) {
try {
lock.lock();
// ID已经用尽并且没有加载下一片段,直接加载下一片段直到成功
if (segments[index()].getMax() <= currentId.longValue()) {
loadingNextSegmentAndSwitch();
}
} finally {
lock.unlock();
}
}
return currentId.incrementAndGet();
}
private void loadingNextSegmentAndSwitch() {
while (shouldLoadNextSegment()) {
loadingNextSegment();
}
setSw(!isSw());
currentId.set(segments[index()].getMin());
}
private boolean loadingNextSegment() {
long start = System.currentTimeMillis();
int currentIndex = reindex();
IdSegment segment = null;
try {
//获取下一段配置
segment = idSegmentRepository.fetchNextIdSegment(biz);
} catch (Exception ex) {
LOGGER.error("Failed to load next segment", ex);
}
if (segment != null) {
segments[currentIndex] = segment;
}
return segment != null;
}
//数据库使用version实现乐观锁,cas控制不同实例获取到不同的id段
public IdSegment fetchNextIdSegment(String biz) {
IdSegment currentSegment = findByBiz(biz);
validate(currentSegment);
long newMax = currentSegment.getMax() + currentSegment.getStep();
int affectRows = executeUpdate(currentSegment.getId(), currentSegment.getVersion(), newMax);
// 需要判断是否更新成功
if (affectRows == 1) {
return new IdSegment(currentSegment.getId(), currentSegment.getVersion(), currentSegment.getBiz(), currentSegment.getStep(), newMax);
} else {
// 如果未更新成功,递归直到更新成功
return fetchNextIdSegment(biz);
}
}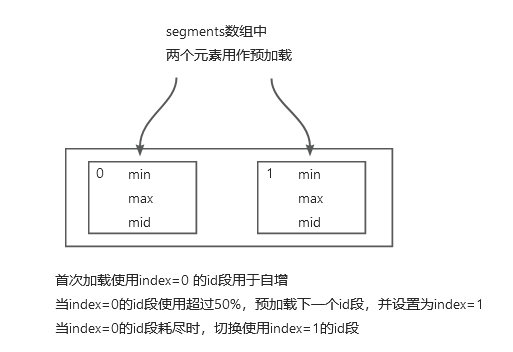
该实现增加了预加载的功能,避免id端用尽时需要等待加载,具体实现原理如上图。
方案三:uuid
上述两种方案,不管是数据库还是服务来生成ID,业务方Application都需要进行一次远程调用,比较耗时。有没有一种本地生成ID的方法,即高性能,又时延低呢?
uuid是一种常见的方案,不过项目中甚少使用该方案作为分布式id
优点:
1、本地生成ID,不需要进行远程调用,时延低
2、扩展性好,基本可以认为没有性能上限
缺点:
1、无递增趋势
2、uuid 过长作为主键查询效率不高
方案四:雪花id
雪花id噎死一中本地生产ID的方法:一个long型的ID,使用其中41bit作为毫秒数,10bit作为机器编号,12bit作为毫秒内序列号。这个算法单机每秒内理论上最多可以生成1000*(2^12),就是400W的ID,基本满足绝大部分业务的需求了。
优点:
1、有序递增
2、本地生成ID,不需要进行远程调用,时延低
3、扩展性好,基本可以认为没有性能上限
附上以往项目中的实现:
public synchronized long generateId() {
long currentTimestamp = getCurrentTimestamp();
// 如果时间戳小于上次时间戳则报错,出现这种错误一般是系统时间被动了
if (currentTimestamp < lastTimestamp) {
throw new IllegalStateException(String.format("Clock moved backwards, refusing to generate id for %d ms", lastTimestamp - currentTimestamp));
} else if (lastTimestamp == currentTimestamp) {
// 如果时间戳与上次时间戳相同,表示同一毫秒内并发请求
// 当前毫秒内,则+1,与sequenceMask确保sequence不会超出上限
sequence = (sequence + 1) & SEQUENCE_MASK;
if (sequence == 0) {
// 当前毫秒内计数满了,则等待下一秒
currentTimestamp = tilNextMills(lastTimestamp);
}
} else {
//跨毫秒
sequence = random0To9();
}
lastTimestamp = currentTimestamp;
return ((currentTimestamp - timeEpoch) << TIMESTAMP_LEFT_SHIFT_BITS) | (workerId << WORKER_ID_SHIFT_BITS) | sequence;
}要注意的是,在跨毫秒时,序列号总是归0,会使得序列号为0的ID比较多,导致生成的ID取模后不均匀(生成的ID,在数据量大时往往需要分库分表,为了分库分表后数据均匀,ID生成往往有“取模随机性”的需求)。解决方法是,序列号不是每次都归0,而是归一个0到9的随机数。
