


一、概述
MySQL InnoDB存储引擎,实现的是基于多版本的并发控制协议——MVCC (Multi-Version Concurrency Control) (注:与MVCC相对的,是基于锁的并发 控制,Lock-Based Concurrency Control)。 MVCC相较于锁并发控制,优势在于:读不加锁,读写不冲突。在读多写少的OLTP应用,极大增加了系统并发。这也是当前几乎所有的关系型数据库系统都支持MVCC。
二、快照读&当前读
快照读,读取的是记录的可见版本 (有可能是历史版本),不加锁。当前读,读取的是记录的最新版本,并且,当前读返回的记录 ,加锁。
select * from table where xxx;
- 当前读
-- S锁(共享锁)
-- 8.0以后可以使用 select * from tabel where xxx for share;
select * from tabel where xxx lock in share mode;
-- X锁(排他锁)
select * from table where xxx for update;
insert into xxx;
update table set xxx;
delete from table where xxx;
将插入、更新、删除这些都归为当前读是因为操作之前,都会有当前读的操作。
三、MySQL的锁类型
默认情况下,数据库中的锁都可以自动获取,但是也可以手动为数据进行加锁。在 MySQL 里,根据加锁的范围,可以分为全局锁、表级锁和行锁三类。
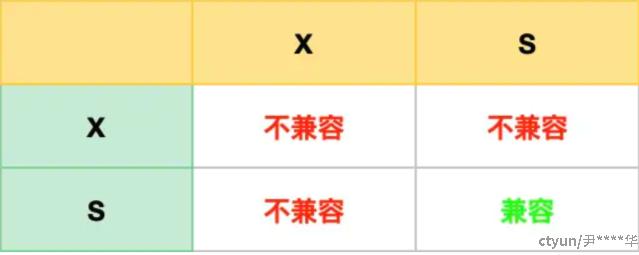
共享锁(S锁)满足读读共享,读写互斥。排他锁(X锁)满足写写互斥、读写互斥。
意向锁是一种锁的层次结构,当一个事务需要设置行锁时,会先获取意向锁,表明该事务对该行进行加锁的操作,同时其他事务可以获取表级别的锁。

1. 全局锁
# 以只读去锁住整个数据库
flush tables with read lock;
# 解锁
unlock tables;
2.表级锁
MDL---元数据锁
select * from performance_schema.metadata_locks;
3.行级锁
行级锁的实现:InnoDB 通过给索引上的索引项加锁的方式,而非记录实现行级锁,与Oracle对数据行加锁的方式不一样,InnoDB这样的加锁方式意味着,通过索引条件检索数据,innodb才使用行级锁,否则,将使用表锁。具体来说,InnoDB 实现了三种行级锁的算法:记录锁(Record Lock)、间隙锁(Gap Lock)和 Next-key 锁(Next-key Lock, record和gap lock的组合)又称临键锁。
行级锁,是通过索引检索的角度去加锁。
record锁
record锁永远都是锁定索引记录,锁定非聚集索引会先锁定聚集索引(那么就会出现 意向锁IX、X)。如果表中没有定义索引,InnoDB 默认为表创建一个隐藏的聚簇索引,并且使用该索引锁定记录。
Gap锁
锁定的是索引记录之间的间隙。例如,c1为唯一索引,SELECT * FROM t WHERE c1 BETWEEN 1 and 10 FOR UPDATE; 会阻止其他事务将 1 到 10 之间的任何值插入到 c1 字段中,即使该列不存在这样的数据;因为这些值都会被锁定。
next-key锁
record和Gap的组合。
4.语句加锁实现分析
create database if not exists test ;
use test;
CREATE TABLE `t` (
`id` int NOT NULL,
`name` varchar(10) DEFAULT NULL,
`age` int DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `name` (`name`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
insert into t values(1, 'A-Alice', 100), (3, 'E-Bob', 200), (6, 'Z-Cak', 300)
1.在主键上的动作
略,较简单。
2. 在唯一键操作
等值查询的数据存在
会在唯一索引上加record锁,在对应的主键加record锁。(非唯一/唯一索引的叶子节点数据是主键,主键的叶子节点是数据页)。唯一索引record锁,可以让唯一索引跟主键的对应关系在锁期间不被篡改。锁唯一键,则保证查看数据的链路(唯一索引--->主键--->数据)得到的结果在锁定期间不被篡改。
等值查询不存在
只在唯一索引上加GAP锁。保证不会突然出现等值的记录。
范围查询存在/不存在
(唯一键, 主键)的组合排序,在这个组合上的gap锁、next-key锁。以及primary key上的record锁。
3.在非唯一键上的动作
等值查询的数据不存在
锁的动作是根据(查询使用的非唯一键,主键)这样的组合值排序来设置点位,从而判断点位之间的gap,并来设置gap锁。
等值查询,值存在
操作动作:name为非唯一索引,查询的name='E-Bob'记录存在
-- 开启事务
begin;
update test.t set age=age + 3 where name='E-Bob';
-- 最后回滚
rollback;
锁情况


以上,第1行IX写表意向锁。第2行,next-key锁,锁定范围( ('A-Alice', 1), ('E-Bob', 3) ]。第3行,行锁主键id=3。第4行,间隙锁,( ('E-Bob', 3), ('Z-Cak', 6) )
在非索引上的动作
非索引操作,无论等值还是范围查询,需要在主键上加next-key锁。锁住表的所有范围,即我们所说的“锁表”。
