


背景和动机
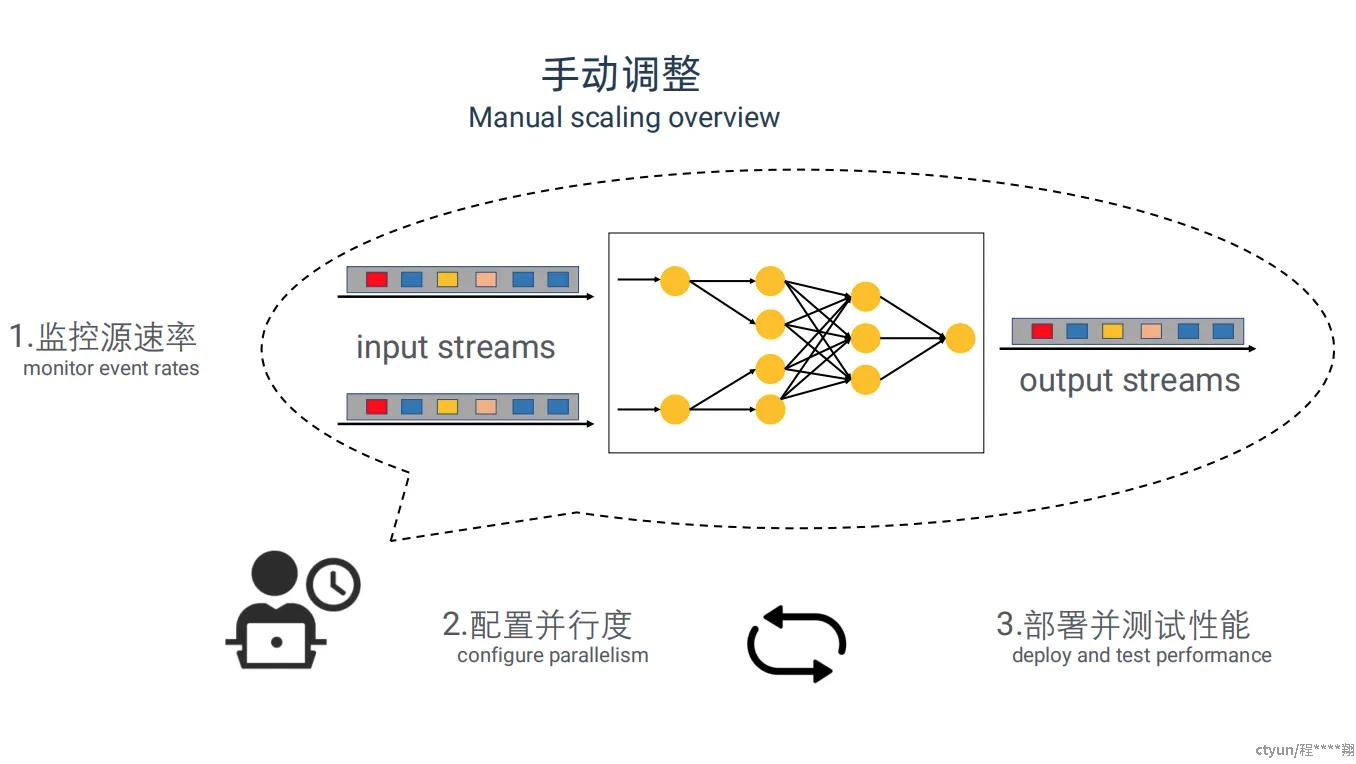
流处理 job 运行期间会有潮汐现象,即流量会时高时低,造成机器资源利用率低下。所以,为了应对紧急情况(比如偶尔的促销活动)以及提高机器资源利用率,我们需要在 job 运行时根据流量的强度调整各个算子的并行度。这便是对于 job 并行度的重新配置(或者称为扩缩容机制)。要调整流处理系统的并行度一般分为三个步骤:
判断是否需要调整 job 并行度
计算 job 里各个算子的新并行度该设为多少
按照新的并行度配置这个 job
在传统 Flink job 的执行中,需要通过手工的方式进行控制,这是很沉重的负担。
一方面,开发者得自己判断是否需要扩缩容,所以万一出现了什么紧急情况可能就得大半夜的爬起来扩缩容一下。
另一方面,开发者得根据自己的经验猜测新的并发度是多少,猜完并重新配置后如果没达到预期效果的话还得再来一次,如果再不达预期就还得整一遍,如是不断调整。
总体来说,对新手十分不友好;并且仅凭经验,并不能保证准确;调整难度大且成本高。
所以,我们希望有个动态扩缩容机制,能够自动判断要不要 scaling、自动给出各个算子的新并行度,从而解放应用开发人员。本文便提出了一个更好的流系统动态扩缩容机制来解决这一问题。
现存动态扩缩容机制的问题(2018年之前)
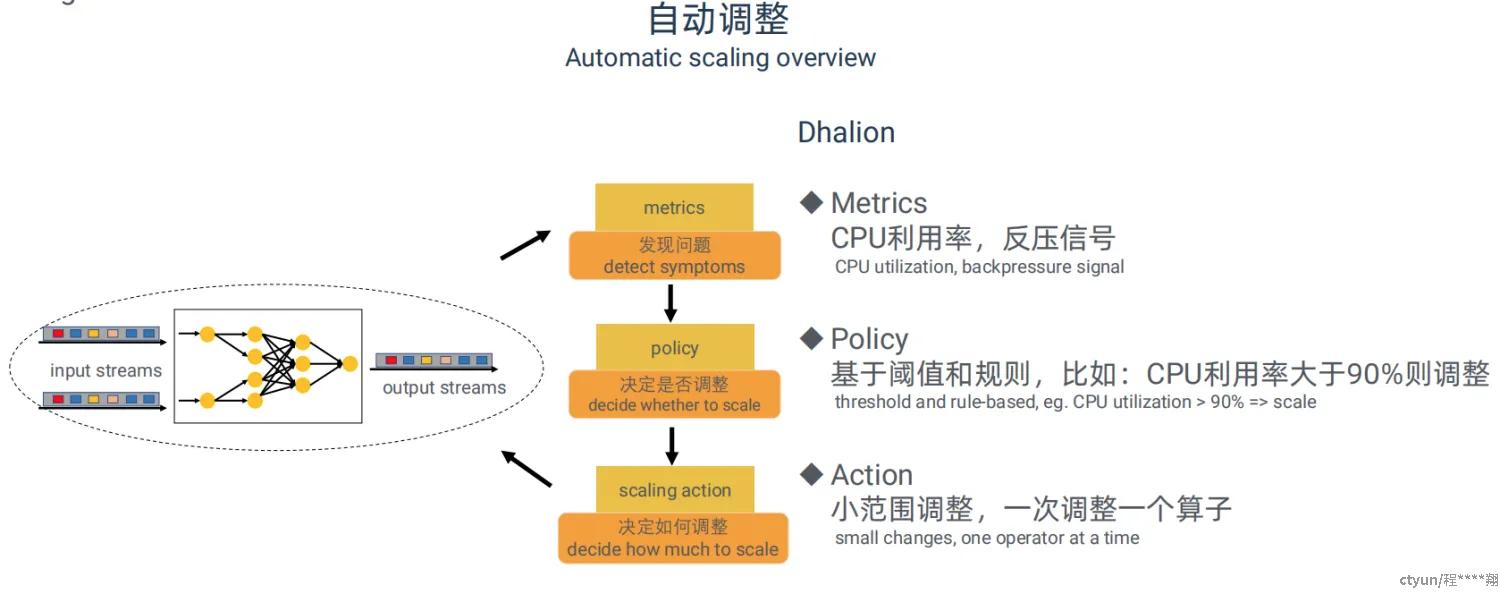
DS2 并不是第一个流处理系统上的动态扩缩容机制,此前其实也有,比如 Heron 上的 Dhalion。但是,这些机制在选用的 metrics 和 performance model 方面都有相应的缺陷。
首先,这些机制的判断依据往往是从外部观察到的 metrics,比如 CPU 利用率、内存利用率、吞吐量等(针对这个问题,本文后续推出true rate以及useful time的概念,来关注每个算子的真正的处理能力和输出能力考虑每个算子的真实处理和输出能力)。由于有性能干扰,利用 CPU 和内存利用率来作为 scaling 的判断依据容易导致误判,特别是在云上多租户环境中。为了避免对于是否需要 scale up 的误判,Google Cloud Dataflow 只将 CPU 利用率用来判断是否需要 scale down。即使如此,仍然可能会在有性能干扰时导致未能及时 scale down。而对于像 Timely 那样通过不断 spin 来等待输入的系统,CPU 利用率则更不适合。
其次,这些机制的 performance model 比较简陋。它们的 decision making 往往是 rule-based,比如如果 CPU 利用率大于 50% 同时出现了背压就 scale up。由于不能正确评估每次调参的影响,它们往往比较谨慎,可能每次就调一个算子的并行度,再跑起来看看效果,调的行的话就调下一个,不行的话就再调一次,不断地重复 throughput monitoring、decision making、state migration、redeployment 这个循环。这样的收敛速度很慢,比如有论文显示,要达到能够处理 input rate 的稳定状态,Heron 得花上一个小时的时间。在真正执行扩缩容动作的过程中,每次都需要触发一次checkpoint并且刷新实时快照的状态到外部存储,然后使用新的并发度进行重启,整个过程持续的时间会比较长,会导致上游累积很多数据,而且可能会需要用户手工介入,无形中也加大了维护成本。
DS2's idea and example
DS2的思路十分朴实,下面以论文中的一个案例进行说明:
在下面这个 logical plan 中,假设我们通过观测 metrics 发现,o1 是性能瓶颈,它的处理速度为 10 record/second,而 o2 的处理速度为 100 record/second。我们希望让 o1 的处理能力增加到 40 record/second,所以打算将 o1 的并行度提高 4 倍。但我们不知道在 o1 的并行度提升 4 倍后,o2 的并行度该提升多少,所以我们只能凭经验乱猜,然后一点点地去试。比如先调 o1,调完后让系统跑起来再看看吞吐量等指标,然后再试着调一下 o2 之类的。

这篇论文提出的更好的办法是,先了解每个算子的 true rate,然后再一次性地调整各个算子的并行度。
什么叫 true rate 呢?
对于某一个算子,当它的 input buffer 或者 output buffer 都没有被 block,那么理论上它的所有资源都被用来干正事,包括对于 record 的 deserialization、processing 和 serialization。所谓 true rate,便是在这种情况下这个算子的实际处理能力,DS2认为我们应该关注算子的真实计算的时间(反序列化、处理、序列化),忽略等待时间。

假设我们知道,此时 o1 的 true rate 是 10 record/second,o2 的是 200 record/second,那么我们其实直接就可以知道,如果把 o1 的并行度提高四倍,o2 的输入流量就高达 400 record/second。由于 o2 的 true rate 是200 record/second,所以 o2 的并行度也得提升 2 倍才行。
所以,我们通过这种方式从头到尾地分析一遍各个算子,就可以一步到位地知道各个算子的并行度该设为多少。然后去实际地 scaling,再然后就发现系统的吞吐量直接达到了预期值。
每个operator的最优并行度的计算方式:
上游所有和当前operator关联的operator的真实输出速率之和 / 当前operator的真实处理速率。
其中,
真实处理速率 = W时间内从上游拉取的数据量条数 / W窗口大小(userful time)
观察处理速率 = W时间内从上游拉取的数据量条数 / W窗口大小(observed time)
真实输出速率 = W时间内往下游推送的数据量条数 / W窗口大小(userful time)
观察输出速率 = W时间内往下游推送的数据量条数 / W窗口大小(observed time)
Useful Time:一个operator算子真正计算的时间 (反序列化 -> 处理 -> 序列化) ,注意这里不包含等待输入和等待输出的时间。
Observed Time:同上,但包含等待收入和输出的时间。
True Rates(真实速率):单位Useful Time内处理和输出速率。
Observed Rates(观察速率):通过简单地计算一个operator算子在经过的单位时间(包括各种等待时间)内处理和输出的记录数而得出的速率。
Instrumentation and Integration
论文中将这个新的 controller 称为是 DS2,集成了 DS2 后的流式系统图如下:
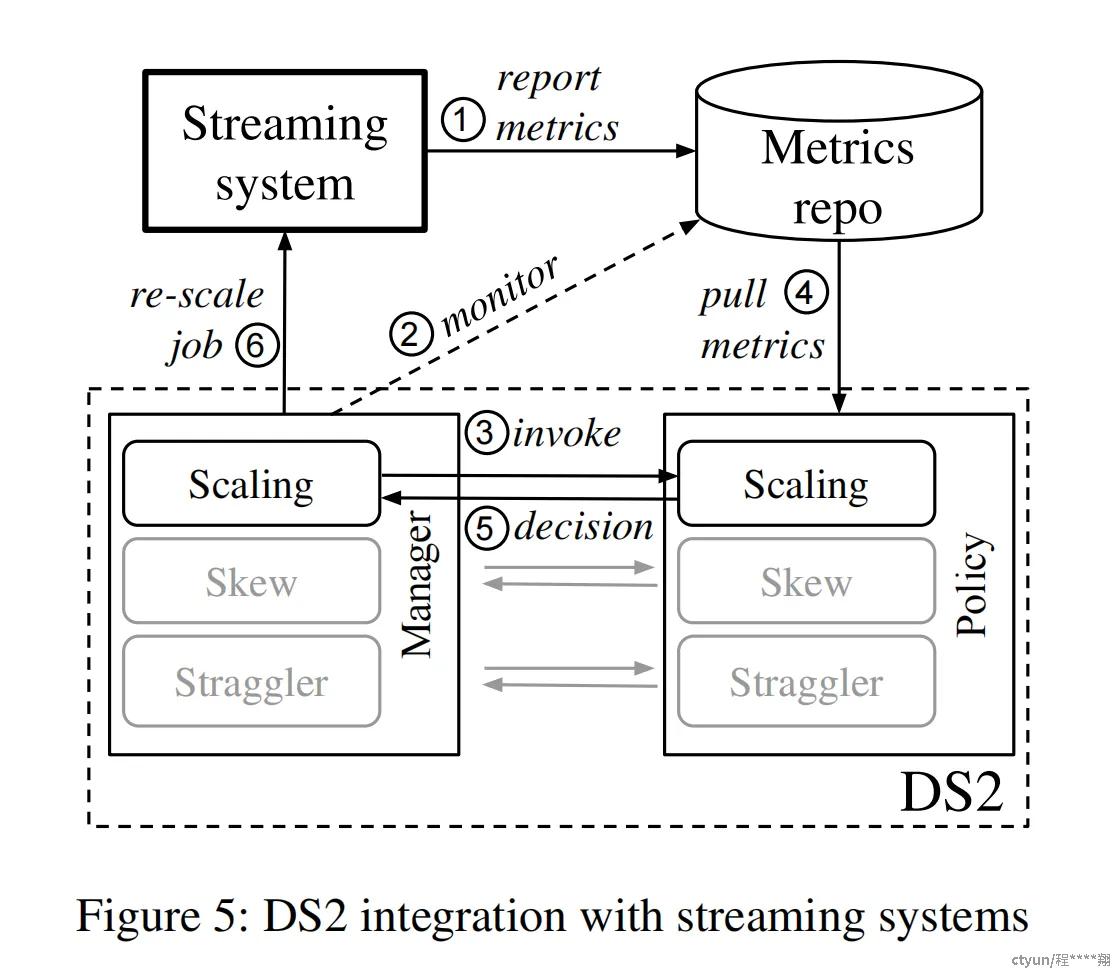
在生产环境下的流式系统中,每处理一条数据就汇报metric是不现实的。MetricRepo是所有metric收集的入口,负责以一个固定的时间间隔从系统(各个JobWorker)拉取指定metric的数据。
DS2是Rescale动作的决策器+执行器,用户作业初始启动时,会向MetricRepo注册一个metric订阅(主要包含:单位时间处理的数据量,输出的数据量,useful time(序列化+反序列化+处理时间),waiting time等),后续MetricRepo会以一个固定的时间间隔将最新metric推送到DS2中。
DS2收集到最新的metric之后,会调用DS2Policy进行计算,然后根据计算结果判断是否需要触发Rescale动作,如果是,会通过DS2Manager通知JobMaster开始执行该动作,并把具体的调整信息传递给JobMaster。
JobMaster收到触发Rescale的通知,开始触发动态扩缩。
后续一直循环重复该流程即可。
一般而言,随着一个算子并行度的线性增加,该算子的处理能力并不会线性增加。一般情况下,由于有 data dependent 和各种 coordination overhead,scaling 都是 sub-linear,也就是说,1+1 可能是小于 2 的。在 scaling 是线性的情况下,论文中的方法确实能够一步到位,对每个算子并行度的设置都不多不少。而在非线性的情况下,论文中的方法是无法做到一步到位的。因此,一次 scaling 后如果发现效果不行就再做一次 scaling,这样不断地迭代。只要你 scaling 的实际趋势是单调的,那总是可以通过几次线性拟合后达到预期值的。所以,在后续工作中,我们或许可以基于机器学习之类的方法进行非线性拟合,毕竟机器学习擅长拟合非线性函数。论文中,作者通过实验发现,最多迭代三次就可以达到预期值,这也是论文标题“three steps is all you need”的来源。论文中通过各种理论分析,证明在满足某些情况下 DS2 只需要迭代一次就能得出最优配置。而这个迭代三次是通过实验得出的经验性规律,没什么理论依据,也未必在所有流式 workload 和实现了这套机制的流式系统中都成立。
相关报告:Flink Forward Asia 2019-马庆祥(奇虎360)
原文传递:Three steps is all you need: fast, accurate, automatic scaling decisions for distributed streaming dataflows
