


一、背景
随着对于业务实时性的要求,以及企业数据量的井喷式增长,对于海量数据的实时分析变得尤为关键。为了满足海量数据的实时报表、大屏与决策分析,可以采用Flink+Doirs的架构体系。
二、组件基本概念
Doris组件介绍
Doris基本架构非常简单,只有FE(Frontend)、BE(Backend)两种角色,不依赖任何外部组件,对部署和运维非常友好。架构图如下
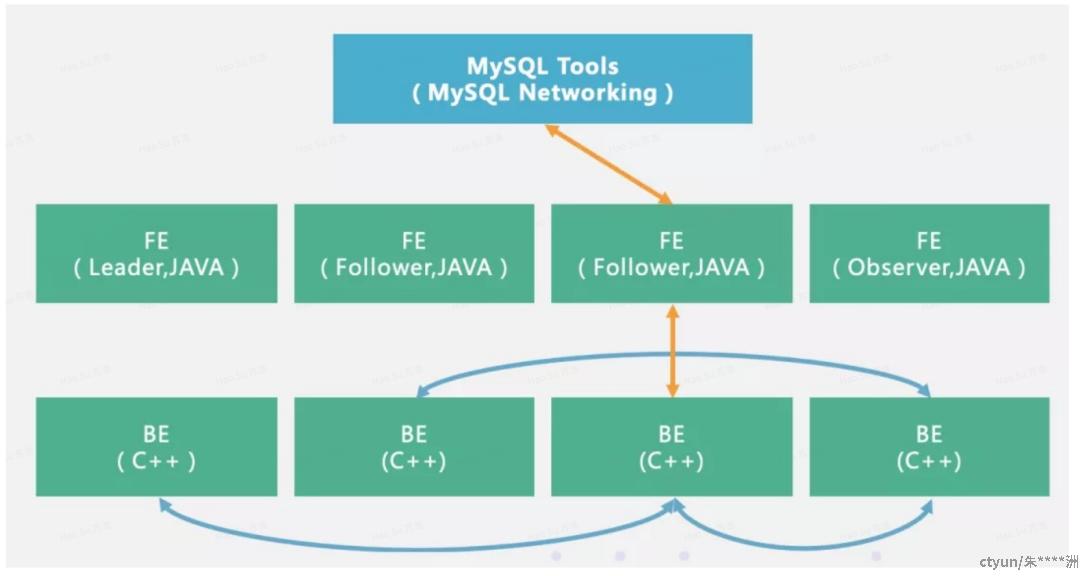
FE(Frontend)以 Java 语言为主。
主要功能职责:
1) 接收用户连接请求(MySql 协议层)
2) 元数据存储与管理
3) 查询语句的解析与执行计划下发
4) 集群管控
FE 主要有有两种角色,一个是 follower,还有一个 observer,leader是经过选举推选出的特殊follower。follower主要是用来达到元数据的高可用,保证单节点宕机的情况下,元数据能够实时地在线恢复,而不影响整个服务。
BE(Backend) 以 C++ 语言为主。
主要功能职责:
1) 数据存储与管理
2) 查询计划的执行
Flink组件介绍
Apache Flink是一个开源的流处理框架,其核心组件包括分发器(Dispatcher)、资源管理器(ResourceManager)、作业管理器(JobManager)和任务管理器(TaskManager)。
- 分发器(Dispatcher):负责应用提交,提供REST接口,启动作业并管理Web UI展示和监控作业执行信息。
- 资源管理器(ResourceManager):负责集群中的资源分配和回收,管理task slots,这是Flink集群中资源调度的单位。
- 作业管理器(JobManager):负责接收Flink作业、协调检查点、故障恢复等,同时管理TaskManager。
- 任务管理器(TaskManager):执行计算的节点,每个TaskManager负责管理其所在节点上的资源信息,如内存、磁盘、网络等。 这些组件共同工作,使得Flink能够高效地处理流数据和批数据,提供了高吞吐量、低延迟的数据处理能力,并且支持事件驱动和微批处理的计算模型。
基本架构
整体数据链路:
- 通过FlinkCDC采集Binlog到Kafka中的Topic1
- 开发Flink任务消费上述Binlog生成相关主题的宽表,写入Topic2
- 配置Doris Routine Load 任务,将Topic2的数据导入Doris
上述的实时数仓架构中,kafka作为数据中间存储层,会造成数据丢失,数据回溯难的问题。Kafka的定位是消息队列,可作为缓存介质使用,对于数据查询和存储其实并不适合。
随着数据湖技术的兴起,我们可以将kafka替换为数据湖,这样就能够支持数据回溯,支持数据更新,实现数据批流读写,支持实时接入。
目前市场上最流行的数据湖为三种: Delta、Apache Hudi和Apache Iceberg。其中Delta和Apache Hudi`对于多数计算引擎的支持度不够,特别是Delta完全是由Spark衍生而来,不支持Flink。对于Iceberg,Flink是完全实现了对接机制,且目前已经接入了doris,可以直接在doris中查询iceberg的数据。
