


1.PAX存储引擎元数据管理
PAX( Partition Attributes Across) 是一种存储布局的优化方案,结合了行存储和列存储的优点。在 PAX 布局中,数据以分区为单位进行存储,每个分区内的属性(即列)是连续存储的。PAX兼具列存的连续IO读取特性、行存元组内数据的空间局部性。
在PostgreSQL中,PAX存储引擎可以基于Parquet文件格式实现。Parquet 文件将数据分割成行组(row group),每个行组包含多个行的数据,类似于 PAX 分区的概念。在每个行组内,Parquet 按列存储数据,即每一列的数据在行组内是连续存放的。这与 PAX 在分区内按列存储的做法一致。创建一张PAX表后,insert语句插入的元组将形成一个文件,称为一个block,即一个Parquet文件。执行多次插入操作后,一张PAX表将拥有多个block文件。下文将介绍PAX如何通过元数据管理PAX表和其中的block文件,特别是block/元组的可见性判断如何实现。
PostgreSQL中,PAX可以插件的形式实现,具有与内核松耦合的特性。这种特性得益于内核支持的自定义Acess Methods(AM)机制。插件开发者可以定义一组表的AM,从而实现自建的存储引擎。具体来说,AM包含了一组操作,如对表进行扫描、对表进行插入、删除,以及索引、vacuum/analyze相关的操作:
static const TableAmRoutine heapam_methods = {
...
.slot_callbacks = heapam_slot_callbacks,
.scan_begin = heap_beginscan, //顺序扫描
...
.scan_getnextslot = heap_getnextslot, //顺序扫描
...
.index_fetch_tuple = heapam_index_fetch_tuple, //索引扫描
.tuple_insert = heapam_tuple_insert, // 插入
...
// 其他访问方法
.tuple_fetch_row_version = heapam_fetch_row_version,
.tuple_get_latest_tid = heap_get_latest_tid,
.tuple_tid_valid = heapam_tuple_tid_valid,
.tuple_satisfies_snapshot = heapam_tuple_satisfies_snapshot,
.index_delete_tuples = heap_index_delete_tuples,PostgreSQL默认的存储方式是Heap表。对于Heap表而言,Heap AM中定义了表内的元组可见性判断方式,这就是Postgre
SQL默认的MVCC机制。可以看出,当开发者自定义AM时,除了考虑数据文件的存储与读写外,还应考虑数组元组如何与内核原有事务、MVCC机制相配合。
PAX插件提供了block级别的MVCC,block内的元组对事务的可见性等同于整个block对事务的可见性。这一机制是基于PAX辅助表和PAX元数据实现的。在PAX中,一张PAX表可以附带一张辅助表。辅助表中的每个元组对应该表的一个block文件。PAX辅助表定义如下:
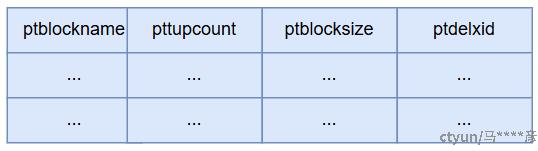
辅助表字段分别是block文件名、文件中元组数量、文件大小。最后一个字段ptdelxid是删除该元组的事务ID,在现版本中与小block合并、PAX表的VACUUM有关系。上文说到,PAX插件提供block级别的MVCC,正是通过辅助表中元组的可见性来实现。辅助表中记录和block文件一一对应,对事务的可见性也一致。事务在写入block文件(PAX中实际的元组)的同时,也向辅助表中插入一条记录;另外的事务在读取block以及其中的元组时,就可以根据辅助表中对应的记录做MVCC判断。
2.Parquet列存文件
Parquet 是一种列式存储文件格式,为高效的数据存储和分析而设计,适合在分布式系统(如 Apache Hadoop、Apache Spark 等)中处理大规模数据集。Parquet 文件格式提供高效的数据压缩和读取性能。Parquet的特点是支持复杂的嵌套数据结构;对于嵌套的字段,Parquet也能将其拆分成原子的类型进行存储。
2.1 Parquet文件布局
Paruqet文件中包含以下部分:行组(RowGroup )、列 (Column )、页(Page)、文件元数据,如图:
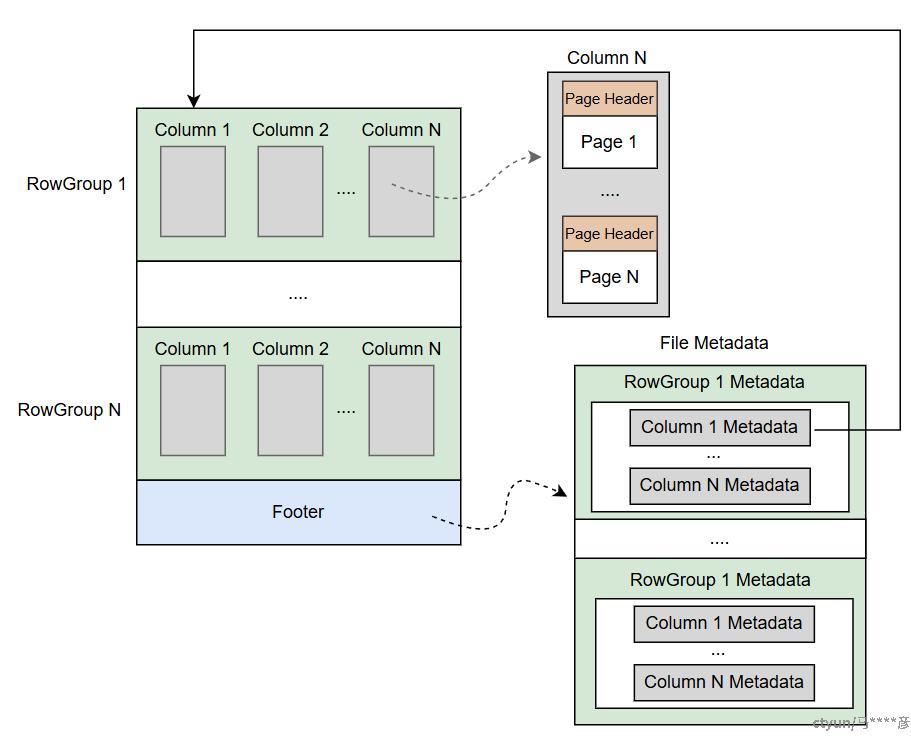
Parquet文件布局是一种嵌套的层次结构,与PAX存储非常相似。层次结构从外到内为:RowGroup -> Column -> Page。每个文件有一个Footer,Footer中记录了所有行组、列、Page的偏移信息,读取Parquet文件时首先读取Footer以定位到需要的行组。如上图所示,Footer内有三种元数据,分别是文件、行组、列元数据。Page同样有元数据对其进行描述,但不存放在Footer中,而是以inline形式存放于Page中(与Page Data一同存放)。几种元数据包含的信息如下:
-
File Metadata: 描述了整个Parquet文件的版本和Schema信息,以及存放的行组等
-
RowGroup:描述了了组内有几行,数据大小等
-
Column Metadata: 描述了该列的编码(Encoding)信息、Page的偏移量、压缩前后的数据大小等
-
Page Header:记录页面中值的数量、编码方式、crc校验码、统计信息等
值得一提的是,Page Header中还包含了支持谓词下推的统计数据。统计数据以min-max索引形式存在,记录每个页中的最大/最小值。根据这项特性,执行带where条件的查询时可以把谓词下推至存储层,在扫描页面时根据min-max值过滤掉一些没必要扫描的页面。例如,对于 where i > 500这一条件,min-max为(100,400)的Parquet页面无需扫描、读取,减少了不必要的IO。
2.2 Parquet列存模型
Parquet列存模型中有两个概念:拆解和组装。拆解是指将逻辑上的一条数据拆分为原子的字段,按字段(列)存储。重组是指,给定按列存储的字段(集),恢复原始的记录,保留其嵌套结构。在重组部分,Parquet可以对任意字段子集按原始嵌套格式进行重组,且单个字段的重组不依赖其他字段。
Parquet数据的定义格式称为Schema,它和Protobuf相似:
message Document {
required int64 DocId;
optional group Links {
repeated int64 Backward;
repeated int64 Forward;
}
repeoted group Name {
repeoted group Language {
required string Code;
optional string Country;
}
optional string url;
}
}Parquet 字段允许声明为:
-
required: 字段存在且重复一次
-
optional: 字段为null或者重复一次
-
repeated:字段为null或者重复任意次
Parquet支持的类型有:
-
BOOLEAN: 1 bit boolean
-
INT32: 32 bit signed ints
-
INT64: 64 bit signed ints
-
INT96: 96 bit signed ints
-
FLOAT: IEEE 32-bit floating point values
-
DOUBLE: IEEE 64-bit floating point values
-
BYTE_ARRAY: arbitrarily long byte arrays.
2.2.1 Parquet拆解:记录到列存
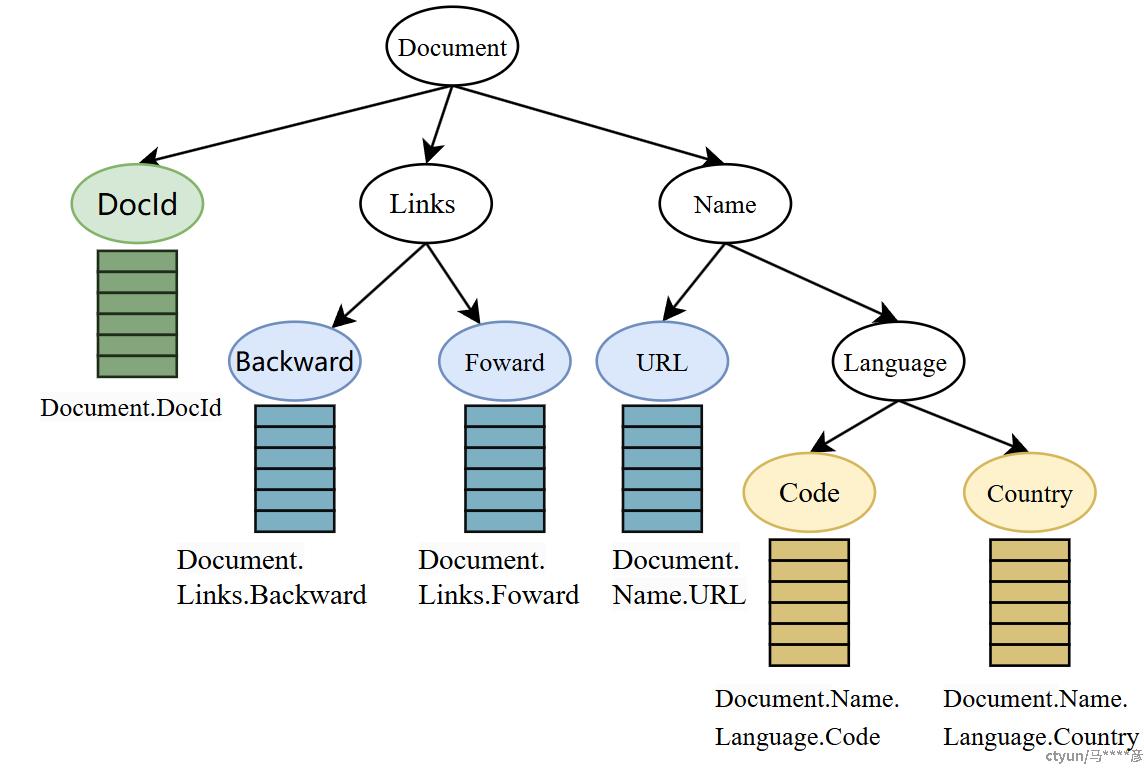
拆解过程将嵌套的字段分解为原子类型并且存储。拆解较为简单,Schema是一个树结构,而叶子节点就是Parquet支持的原子类型;对每个叶子节点的数据单独存储即是”按列存储“。如图,对叶子节点进行同类型字段的存储即可。
2.2.2 Parquet重组:列存到记录
按列存储的方式没有保留原始嵌套结构的表示,因此将列式存储重组为Parquet Schema时,需要引入额外的辅助信息。对于要存储的每个值,Parquet额外存储两个字段:Repetition Level,Definition Level。
为什么要引入这两个字段?以下通过举例,说明这两个字段的必要性和作用。
先考虑一种简单情形:Schema中所有字段均不允许为空、不允许重复,也就是所有字段有且仅出现一次。此时,即使数据按列分别存储,也不影响重组为符合原始Schema的记录,因为字段的一个值必然属于特定的一条记录;同时,字段名字本身就记录了shcema路径(例如Document.Links.Backward),因此字段在记录的schema层级中出现的位置也是确定的。这种情形下,不需要引入任何辅助信息,也可以正确重组记录。
Record1
DocID:10
Links
Forward:20
Forward:40
Forward:60
Name
Language
Code:'en-us'
Country:'us'
Language
Code 'en'
URL:'xxxx//A'
Name
URL:'xxxx//B'
Name
Language
Code:'en-gb'
Country:'gb'
Record2
DocID: 20
Links
Backward:10
Backward:30
Forward:80
Name
URL:'xxxx//C'现在考虑在简单情形的基础上,允许字段重复:可以直观地想到,对于按列存储的一组值,无法确定是否包含了重复值;更重要的是,即使知道有重复值,无法确定是哪一层级的字段重复引起的。例如对于上述Schema的Name.Language.Code字段,可能是由于Name或者Language重复引起的;如果Code字段本身是可重复字段,那还有可能是它自身在重复。因此,对列存中的每个值,Parquet需要记录“该字段在哪一层级进行重复”的信息,也就是Repetition Level,才能正确地将列存还原为一条记录。
考虑上文例子Record 1。对于 Code字段,如果是由于Language字段引起的重复,则其Repetition Level为2。如果是Code自身重复,Repetition Level为3。同理Name引起重复则为1。有一种特殊情况,即Code第一次在记录中出现,则Repetition Level为0,暗示一条新的记录由此开始。
再考虑允许字段为空的情形:与重复字段类似,我们无法确定一个为NULL的字段从哪一层级开始是空值。为此Parquet引入了Definition Level。对于一个字段,Definition Level描述“在当前路径上,有多少可空值实际被定义”。
例如,考虑Record 1中URL字段。在Name的第三次重复中,URL没有定义,但父结构Name已定义。因此,它的Definition Level是1。考虑Country字段。在Name的第二条次重复中,Name已定义但Language未定义,因此Definition Level同样是1。
