


OceanBase是蚂蚁集团自主研发的分布式关系型数据库,能在普通硬件上实现金融级高可用,首创“三地五中心”城市级故障自动无损容灾新标准,具备极高的可扩展性和高可用性。
基本概念
Cluster:
OceanBase集群(Cluster)由一个或多个Region组成,Region由一个或多个Zone组成,Zone由一个或多个OBServer组成,每个OBServer可有若干个Unit,每个Unit可有若干个日志流(Logstream)的副本(Replica),每个Logstream可使用若干个分片(Tablet)。
Region:
Region对应物理上的一个城市或地域。
Zone:
Zone指一个数据中心或一个物理区域,它是一个逻辑上的概念,通常包含多个存储节点,这些节点在物理上可以分布在不同的机房、不同的机架或不同的服务器上。
OBServer:
OBServer构成OceanBase集群的基础组件,是OceanBase数据库的核心进程和部署单元,承担数据存储、计算、分布式事务处理等关键功能。
Tenant:
OceanBase数据库采用了多租户架构,租户(Tenant)通过资源池(ResourcePool)与资源关联,从而独占一定的资源配额。在租户下可以创建Database、表、用户等数据库对象。
ResourcePool:
资源池(ResourcePool)是资源分配的基本单位,每个资源池由若干个Unit组成,同一个资源池内的各个Unit具有相同的资源规格。
Unit:
资源单元(Unit)是租户在OBServer节点上的容器,描述租户在OBServer上的可用资源(CPU、Memory、Disk等)。
Partition:
分区(Partition)是用户创建的逻辑对象,是划分和管理表数据的一种机制。
Tablet:
分片(Tablet)是实际的数据存储对象,支持在机器之间迁移(Transfer),是数据均衡的最小单位。
Logstream:
日志流(Logstream,LS)是由OceanBase数据库自动创建和管理的实体,它代表了一批数据的集合,包括若干Tablet和有序的Redo日志流。
ODP:
OceanBase Database Proxy,又称OBProxy,是OceanBase数据库专用的代理服务器。
RootService:
总控服务(RootService)运行在某个OBServer上,主要提供资源管理、容灾、负*均衡、schema管理等功能。
GTS:
每个租户启动一个全局时间戳服务(Global Timestamp Service,GTS),事务提交时通过本租户的时间戳服务获取事务版本号,保证全局的事务顺序。
Locality:
租户下日志流在各个Zone上的副本分布和类型称为Locality。
Primary Zone:
用户可通过一个租户级的配置,使租户下日志流的Leader分布在指定的Zone上,此时称Leader所在的Zone为Primary Zone。
系统架构
OceanBase数据库支持无共享(Shared-Nothing,SN)和共享存储(Shared-Storage,SS)两种部署模式。
其中,SS模式采用了存储计算分离的架构,每个租户在共享对象存储上存储一份数据和日志,每个租户在节点的本地存储上缓存热点数据和日志。一方面社区版不支持存算分离架构,另一方面SS模式主要适用多云环境,再就是底层存储不影响管理面分析,故以SN模式作为参考。
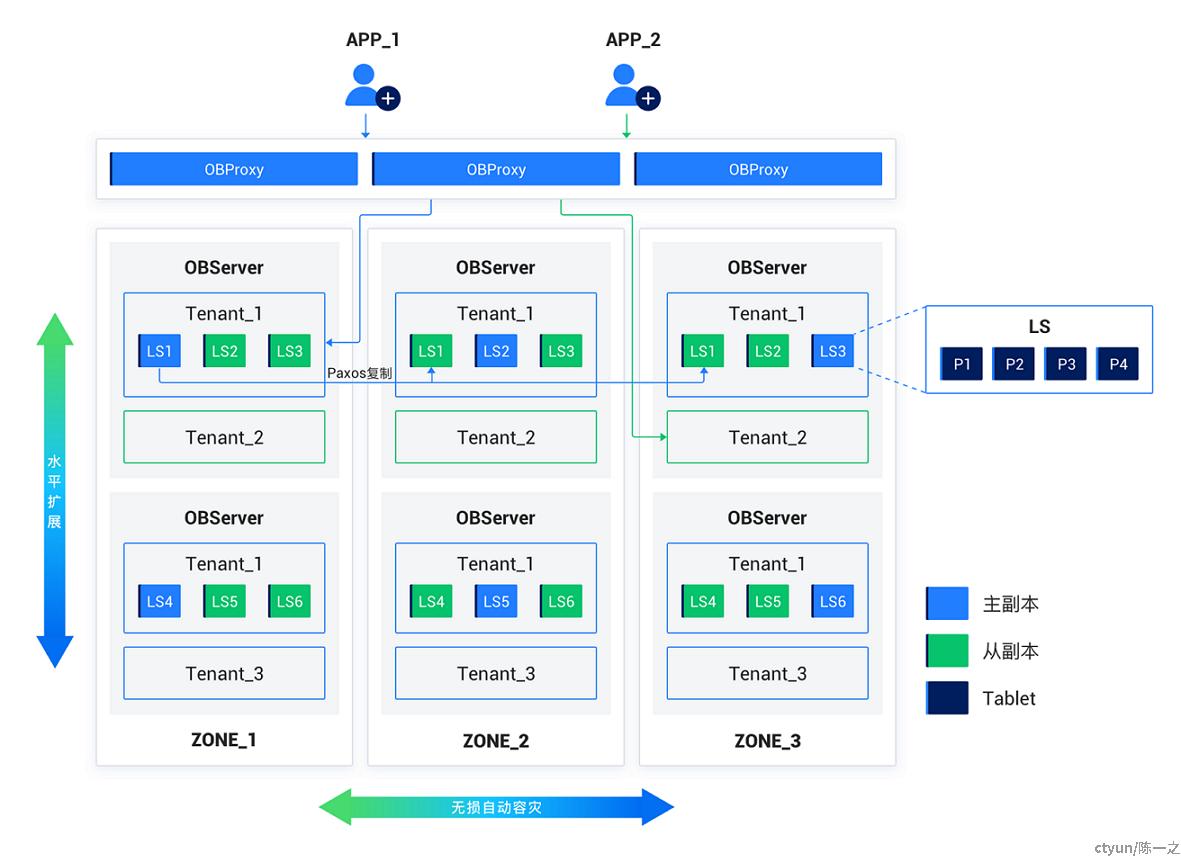
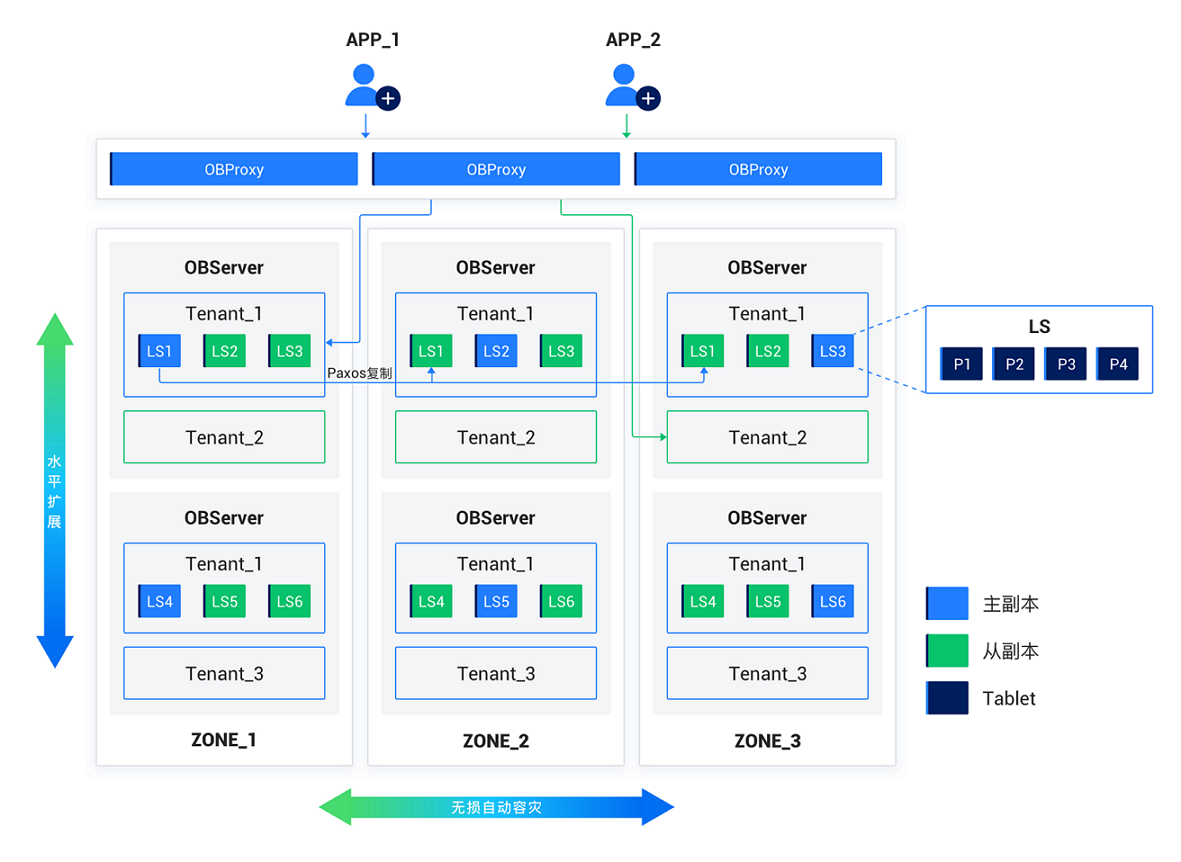
横向是容灾区域的伸缩,以Zone为基本单位。Region是地域的抽象,包含一个或多个Zone,便于逻辑上理解,不直接影响调度。
纵向是存储节点的伸缩,以OBServer为基本单位。各个节点之间完全对等,每个节点都有自己的SQL引擎、存储引擎、事务引擎。每个Zone可有不同数量和规格的OBServer实例。租户定义的资源Unit会自适应分布到不同OBServer容器上,随着OBServer节点的增减和负*变化也可能在其间迁移。
资源迁移也就是数据迁移,数据迁移的对象是日志流LS。LS迁移实际影响的是其所管理的分片Tablet和Redo日志,行为上可能是单个LS的转移、切分,或多个LS的合并、重组。
流量路径上,应用通过负*均衡访问数据代理OBProxy,OBProxy解析SQL并将请求转发给最合适的OBServer,所以从OBProxy到OBServer可能发生跨Zone的访问。一般情况下是根据数据分片规则,将请求转发给负责该分片数据的LS的主副本所在节点。读写分离模式下也可能将读请求转发给从副本。
图中未标明的还有RootService和GTS角*,二者均是OBServer上的服务,通过Paxos协议实现高可用。OB实现的是优化过的Multi-Paxos协议,但依赖单Leader推进状态机,所以还是单点读写模型。RootService和GTS的主副本所在位置可能会对业务请求产生影响:RootService主要负责集群管理,应用访问数据库不直接依赖它,所以它对应用请求直接影响较小,但它可能会重均衡资源分布,间接影响应用流量路径;应用写请求*依赖GTS获取事务版本号,如果数据节点与GTS不在同一个Zone里,就会发生跨区域访问;OBServer有本地事务提交信息的缓存,如果信息量足够,应用读请求可以不需要访问GTS。
应用数据管理
OceanBase采用多租户架构,租户之间互相隔离,故多租户管理与单租户管理没有本质区别,可以看作是业务的垂直拆分,仅需讨论单租户模式。
从应用的角度,数据管理主要两方面的考虑:(1)应用管理数据的粒度;(2)数据在Zone之间的分布。
数据库表
以SQL型数据库版本MySQL模式为例,显然应用关注的数据粒度是库表。使用MySQL模式的租户连接OB集群,创建库表与原生MySQL数据库并无二致,特殊的是分区、表组和索引。
分区
OceanBase数据库可以把普通的表的数据按照一定的规则划分到不同的区块内,同一区块的数据物理上存储在一起。这种划分区块的表叫做分区表,其中的每一个区块称作分区。
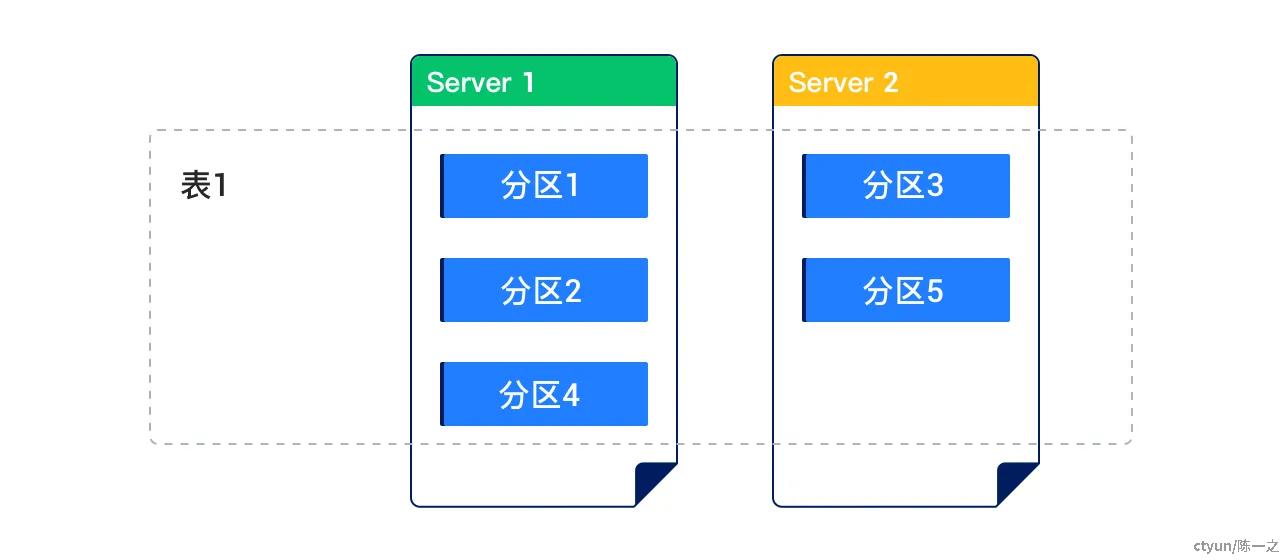
从应用程序的角度来看,只存在一个Schema对象,访问分区表不需要修改SQL语句。不过,不同分区对象可以集体或单独管理,数据库的存储单位和负*均衡单位都是分区,不同的分区可以存储在不同的节点,也可以单独指定主节点的放置策略。因此,从数据库的角度来看,分区表是存储的负*均衡;从应用的角度来看,分区表也影响流量的负*均衡。
MySQL模式目前支持Range、Range Columns、List、List Columns、Hash、Key和组合七种分区类型。
Range:
Range分区根据分区表定义时为每个分区建立的分区键值范围,将数据映射到相应的分区中;Range分区的分区键必须是整数类型或YEAR类型,如果对其他类型的日期字段分区,则需要使用函数进行转换;Range分区的分区键仅支持一列。
Range Columns:
Range Columns分区与Range分区的作用基本类似,不同之处在于Range Columns分区的分区键的结果不要求是整型,还可以是浮点、时间和字符串类型;Range Columns分区的分区键不能使用表达式;Range Columns分区的分区键可以写多个列(即列向量)。
List:
List分区可以显式地为每个分区的分区键指定一组离散值列表;List分区的优点是可以方便地对无序或无关的数据集进行分区;List分区的分区键可以是列名,也可以是一个表达式,分区键必须是整数类型或YEAR类型。
List Columns:
List Columns分区与List分区的作用基本相同,不同之处在于List Columns分区的分区键不要求是整型,还可以是时间和字符串类型;List Columns分区的分区键不能使用表达式;List Columns分区支持多个分区键。
Hash:
Hash分区通过对分区键上的Hash函数值来散列记录到不同分区中;Hash分区的分区键必须是整数类型或YEAR 类型,并且可以使用表达式。
Key:
Key分区与Hash分区类似,通过对分区键应用Hash算法后得到的整型值进行取模操作,从而确定数据应该属于哪个分区;Key分区的分区键不要求为整型,可以为除TEXT和BLOB以外的其他数据类型;Key分区的分区键不能使用表达式;Key分区的分区键支持向量;Key分区的分区键中不指定任何列时,表示Key分区的分区键是主键。
组合:
组合分区通常是先使用一种分区策略,然后在子分区再使用另外一种分区策略,适合于表数据量非常大的场景。
表组
表组(Table Group)是一个逻辑概念,表示一组表的集合。默认情况下,不同表之间的数据是随机分布的,没有直接关系。通过定义表组,可以控制一组表在物理存储上的邻近关系。
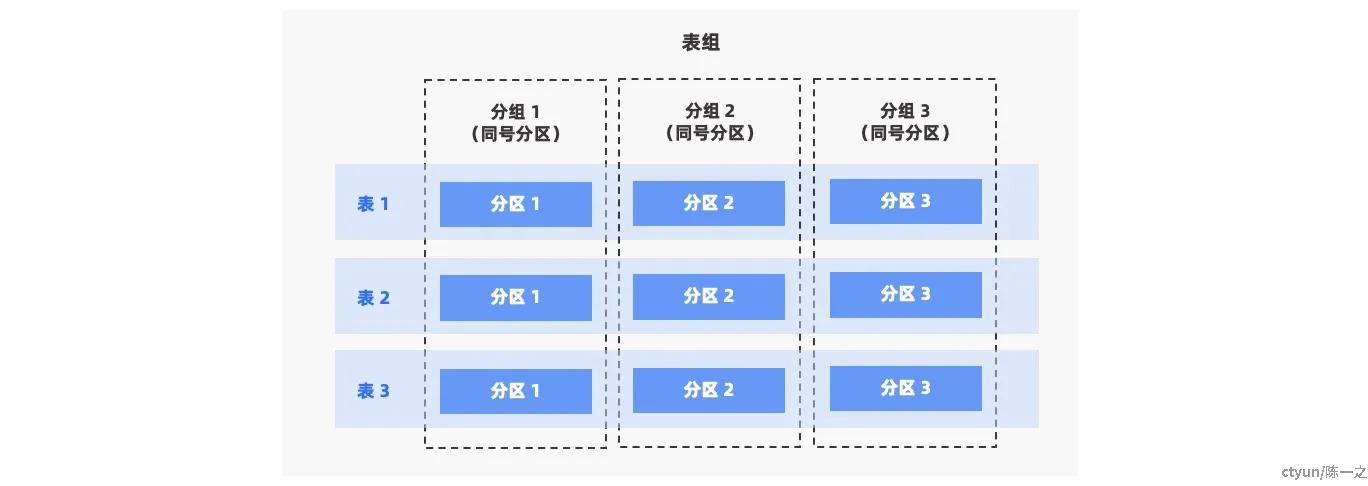
在应用多活场景,业务往往使用单一标识(如用户ID)来切分数据和聚合流量,切分数据指水*分片,用于建立多个自治的应用站点;聚合流量指请求闭环,流量在自治站点内封闭,避*跨区域的访问降低整体性能,也控制单一站点故障的影响范围。单一标识可能贯穿多个业务表,所以表组的引入拥有极高的业务价值,可以显著降低管理成本。
表组通过SHARDING属性来定义表数据的分布关系:
- NONE:表组内的所有表的所有分区均聚集在同一台机器上,并且不限制表组内表的分区类型。
- PARTITION:表组内每一张表的数据按一级分区打散,如果是二级分区表,则一级分区下的所有二级分区聚集在一起。要求所有表的一级分区的分区定义相同;如果是二级分区表,也只校验一级分区的分区定义。
- ADAPTIVE:表组内每一张表的数据根据自适应方式打散。即,如果表组内的表是一级分区表,则按一级分区打散;如果表组内的表是二级分区表,则按每个一级分区下的二级分区打散。要求所有表的分区级别和分区定义相同。
索引
在OceanBase中,某个表上定义的索引也是以表的形式存在。自然地,主表与索引表的关联分布是应用需要了解的内容,具体来说就是——通过索引访问表数据是否会跨越不同节点。
这里有两种模式,分别是局部索引(LOCAL关键字定义)和全局索引(GLOBAL关键字定义):局部索引的每个分区副本会和表数据的对应分区副本存于同一节点;全局索引的副本分布和表数据的副本分布相互DL,索引和表数据可能不在同一节点。
在创建索引的时候,需要将用户查询模式、索引管理、性能、可用性等方面的需求*合起来考虑,选择一个最合适自身业务的索引方式:
- 如果用户需要唯一索引,并且索引键覆盖所有分区键,则可以定义成局部索引,否则需要用全局索引。
- 如果主表的分区键是索引的子集,则可以采用局部索引。
- 如果主表分区属性和索引的分区属性相同,建议采用局部索引。
- 如果比较关注索引分区管理的代价,主表分区总是不断变动,尽量避*创建全局索引。
- 如果数据分布不均、经常跨分区查询或全表排序、聚合,全局索引可能更加合适。
数据流量
数据库流量分为写流量、强一致读流量和弱一致读流量,写流量和强一致读流量由OceanBase数据库的Leader副本提供服务,弱一致读流量由Leader副本和Follower副本提供服务。ODP提供了数据库流量的路由选择能力,ODP实现了一个简单的SQL Parser模块,解析出SQL中的库名、表名及hint,从而根据业务SQL、路由规则、及OBServer节点的状态,选择最合适的一个OBServer节点转发请求。
数据分布
基于Paxos协议的多副本架构是高可用能力的基础,多副本中的“副本”本质是同一份数据在不同节点的拷贝,而数据在OceanBase数据库中有多种层面的承*容器,例如数据分区、日志流、Unit、租户等。一般情况下业务提及的“副本”往往是指“数据分区副本”。
OceanBase数据库的存储引擎采用分层LSM-Tree结构,数据分为两部分:基线数据和增量数据。基线数据是持久到磁盘上的数据,一旦生成就不会再修改,称之为SSTable。增量数据存在于内存,用户写入都是先写到增量数据,称之为MemTable,通过Redo Log来保证事务性(也称为Commit Log,CLog;或Write-Ahead Log,WAL)。
所以,数据的一致性也就是日志的一致性。日志流(Logstream,LS)是由OceanBase数据库自动创建和管理的实体,它代表了一批数据的集合,包括若干数据分区,及对其进行事务操作的日志和事务管理结构。

每个租户由若干个Unit组成,日志流根据一定的规则分布于这些Unit上,从而决定了归属于日志流的数据分区在Unit上的分布。OceanBase数据库V4.0开始在租户管理上增加了限制,要求同一个租户所有Zone的Unit个数相同。系统为每个Zone的Unit进行了编号,不同Zone之间相同编号的Unit组成一个Unit Group。
流量分布
流量分布通过Primary Zone来描述,Primary Zone描述了Leader副本的偏好位置,而Leader副本承*了业务的强一致读写流量,即Primary Zone决定了OceanBase数据库的流量分布。当配置了某张表的Primary Zone后,RootService会尽量将表的Leader调度到指定Zone上,这个过程不是即时的,也受集群运行状态和环境的影响。
Primary Zone实际上是一个Zone的列表,列表中包含多个 Zone:当Primary Zone列表包含多个Zone时,用“;”分隔的具有从高到低的优先级;用“,”分隔的具有相同优先级,表示流量打散在多个 Zone 上,这几个Zone同时提供服务。
日志流组的概念是为了适配Primary Zone打散在多个Zone上而引入的:
- 当Primary Zone为单个Zone时,Unit Group内只需要创建单个日志流。
- 当Primary Zone为多个Zone时,Unit Group内需要创建多个日志流来实现服务能力水*扩展。
这些日志流具有相同的分布属性,他们共同组成一个日志流组,日志流组内的日志流个数等于Primary Zone的Zone个数。
举个具体的例子,假设应用部署在三个容灾单元(Zone):
- 如果只配置一个Primary Zone:无论业务表是否分区,表Leader都会被调度到这个Zone上。此时无论上层应用流量如何拆分,ODP都会将数据请求转发到这个Zone进行读写,即存在跨Zone流量。
- 如果配置多个Primary Zone,比如说z0,z1,z2:如果业务表不分区,则与第一种情况类似,此时RootService会根据集群运行情况自适应选择一个Zone;如果业务表同样分3个区,分别是p0(uid%3=0)、p1(uid%3=1)、p2(uid%3=2),那么可以配置p0、p1、p2的Leader的分区偏好为z0、z1、z2,配合上层应用流量路由可以实现一定程度的流量分区闭环(不包括写数据一致性同步产生的跨Zone流量)。
应用容灾架构
应用容灾架构映射应用容灾等级,选择多机房/多地域的集群架构,也是为了获得机房级/地域级的容灾能力。从技术的角度,只要将数据副本分散到多个机房/地域,通过跨机房/地域的Paxos组,就能获得相应的容灾效果。但是,技术只提供了逻辑框架,实际的部署方案,还需要权衡人员、时间、金钱和质量要求。
在解决机房级和地域级容灾问题上,OB推荐的是同城三机房三副本部署和三地五中心五副本部署方案。
同城三机房三副本部署:
- 同城3个机房组成一个集群(每个机房是一个 Zone)。
- 任意一个机房发生故障,剩余副本依然可以构成多数派,RPO=0。

三地五中心五副本部署:
- 三个城市,按2-2-1的机房分布组成一个5副本的集群。
- 任意一个机房或者城市发生故障,剩余副本依然可以构成多数派,RPO=0。
- 3份以上副本才能构成多数派,每个城市最多只有2份副本,其中两个城市应距离较近,以降低时延。

常见的还有两地三中心部署方案,但这个方案的容灾等级不稳定,能够解决机房级别故障,不能稳定解决地域级别故障。
- 两个城市,按2-1机房分布组成一个3副本或5副本的集群。
- 任意一个机房发生故障,剩余副本依然可以构成多数派,RPO=0。
- 单机房地域发生故障不影响可用性和性能。
- 双机房地域中的任一机房故障不影响可用性,但影响性能(需跨地域共识)。
- 双机房地域故障影响可用性,需要在单机房地域恢复集群,RPO可能不为0。

