大模型断点续训调研
1、摘要
大模型的断点续训技术对于保障大模型训练稳定性至关重要。这篇技术分享对现有学术界、业界的研究成果进行了调研总结,以挑战和优化点作为划分,依次介绍每个优化点要解决什么问题、思路是什么、哪些文章/工作用到了哪些优化点,以及其对应优化效果。
2、什么是断点续训?为什么要用断点续训?
大模型训练面临几大挑战:首先,大模型参数量庞大,且训练需要用到海量的训练数据,这导致单次训练周期往往长达数周甚至数月,对算力调度和稳定性提出极高要求。此外,用海量数据训练大模型通常依赖数千至数万张显卡组成的集群,其存在较高的软硬件故障风险,可能导致训练意外中断,因此,我们需要断点续训技术,用于在中断发生后快速恢复训练。
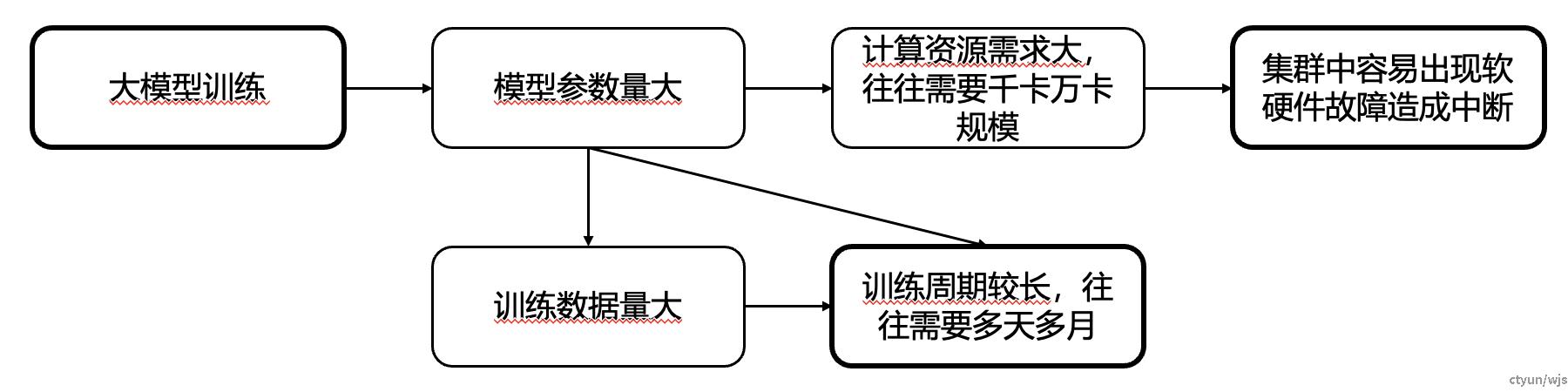
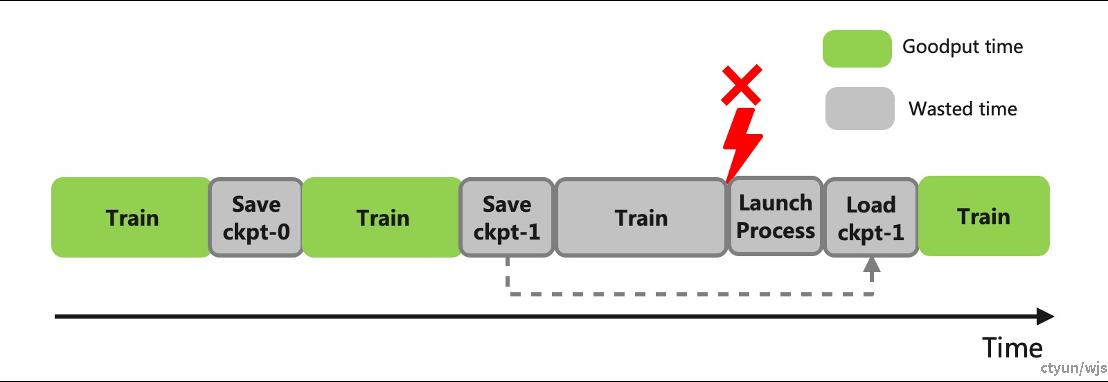
断点续训的目的:在训练的过程中定期保存记录训练状态的断点,从而使得模型训练能够在发生中断之后快速恢复。
3、调研方法与范围
调研内容:对大模型断点续训技术当前在学术界与业界的主流做法进行了深入调研,共调研十项工作,详细分析了每项工作的背景、挑战与问题、做法与效果分析。
检索方式
检索信息主要来源:Google Scholar、ACM、IEEE及友商官网文档
检索词:大模型checkpoint、分布式训练checkpoint、checkpoint profiling
时间:集中于2020年至2025年
调研内容汇总
| 序号 | 技术方向 | 典型应用场景 |
|---|---|---|
| 工作1 | 蚂蚁、天翼云 | DLRover - SnapCheckpoint |
| 工作2 | 华为+USTC | ExCP: Extreme LLM Checkpoint Compression via Weight-Momentum Joint Shrinking (ICML 2024) |
| 工作3 | 香港大学+字节跳动 | ByteCheckpoint: A Unified Checkpointing System for Large Foundation Model Development |
| 工作4 | 伊利诺伊+微软 | Universal Checkpointing: Efficient and Flexible Checkpointing for Large Scale Distributed Training |
| 工作5 | Rochester理工 | DataStates-LLM: Lazy Asynchronous Checkpointing for Large Language Models (HPDC2024) |
| 工作6 | 阿里巴巴 | EasyCkpt |
| 工作7 | 港理工+NUS+港科大+哈工大+华为 | Fault-Tolerant Hybrid-Parallel Training at Scale with Reliable and Efficient In-memory Checkpointing |
| 工作8 | 上海交通大学+华为 | BAFT: bubble-aware fault-tolerant framework for distributed DNN training with hybrid parallelism (FCS2024) |
| 工作9 | 亚马逊AWS | Gemini: Fast Failure Recovery in Distributed Training with In-Memory Checkpoints (SOSP2023) |
| 工作10 | UT Austin+微软 | CheckFreq: Frequent, Fine-Grained DNN Checkpointing (FAST2021) |
4、断点续训面临哪些挑战?断点续训业界、学术界的做法是什么?
没有任何一个方法能够应对断点续训所面临的所有困难。虽然有这么多的文章在做断点续训,但是各家的创新点多少都有重叠之处,可以归纳出13个优化点。
以下将以优化点为维度进行介绍,主要包括:
- 每个优化点要解决什么问题?
- 思路是什么?
- 哪些文章/工作用到了它?
- 效果如何?
| 挑战 | 优化点 | 做法 |
|---|---|---|
| 挑战1:断点存储较为耗时:断点存储的耗时高度受到模型大小、存储IO性能等因素的影响 挑战2:对训练造成阻塞:若断点保存时间过长,可能对训练效率造成阻塞,影响训练效率 |
优化点1:异步持久化 | 将同步checkpoint存储优化为异步checkpoint存储,与训练过程平行进行,防止对训练过程造成阻塞 |
| 优化点2:Checkpoint阶段化拆分 | 对checkpoint过程进行拆分,更细粒度地进行并行运行 | |
| 优化点3:惰性阻塞 | 在对checkpoint进行阶段化拆分的基础之上,只在不要的阶段对训练进行阻塞,防止不必要的训练阻塞 | |
| 挑战3:断点较为臃肿:大模型的断点信息量大,如果全都存储较为臃肿 | 优化点4:部分存储checkpoint | 对相邻checkpoint之间的关联进行分析,只存储发生显著改变的部分,从而减小checkpoint尺寸,防止对checkpoint进行全量存储造成的性能损失 |
| 挑战4:断点存储的时机:断点存储的时机难以决定,进行的时机不当会对训练资源造成占用 | 优化点5:实时checkpoint写入 | 在异步checkpoint存储的框架下,无需等待gpu-to-host-memory完全结束,即可实时进行host-memory-to-storage的写入操作 |
| 优化点6:通过profiling优化断点传输时机 | 通过profiling机制,寻找空档时段,优化断点操作时机 | |
| 挑战5:分布式场景下需要考虑因素众多:checkpoint的任务量均衡、防止断点续训引起不必要的通讯代价等 | 优化点7:分布式存储/读取checkpoint | 对checkpoint进行分布式的存储与读取,防止不必要的通信代价,防止单点任务量过大 |
| 优化点8:checkpoint传输路径优化 | 利用传输速率最高的传输路径传输checkpoint | |
| 挑战6:断点续训灵活性差:大多数断点续训机制和大模型并行训练策略高度绑定,不支持并行策略灵活变动 | 优化点9:支持并行策略灵活调整 | 破除checkpoint对于并行策略的依赖,使得checkpoint支持并行策略的灵活调整 |
| 挑战7:断点续训与硬件高效配合 | 优化点10:内存预分配 | 预先分配checkpoint需要的内存空间,防止重复内存分配 |
| 挑战8:硬件损坏导致checkpoint丢失,导致无法正常续训 | 优化点11:断点多副本存储 | 将断点在多处进行存储备份,以在出错时提升恢复概率 |
| 优化点12:parity check保护checkpoint | 利用parity check保护因硬件损坏丢失的checkpoint可恢复 | |
| 挑战9:断点的存储频率较难掌握:太频繁浪费资源,间隔太长导致续训后浪费太多算力 | 优化点13:自适应调整checkpoint频率 | 通过持续profiling,动态调整checkpoint的频率 |
具体优化点、应对的挑战、做法与效果
优化点1:异步持久化
应对的挑战:
- 挑战1:断点存储较为耗时
- 挑战2:对训练造成阻塞时间较长
目的:防止checkpoint存储过程对训练过程造成阻塞。
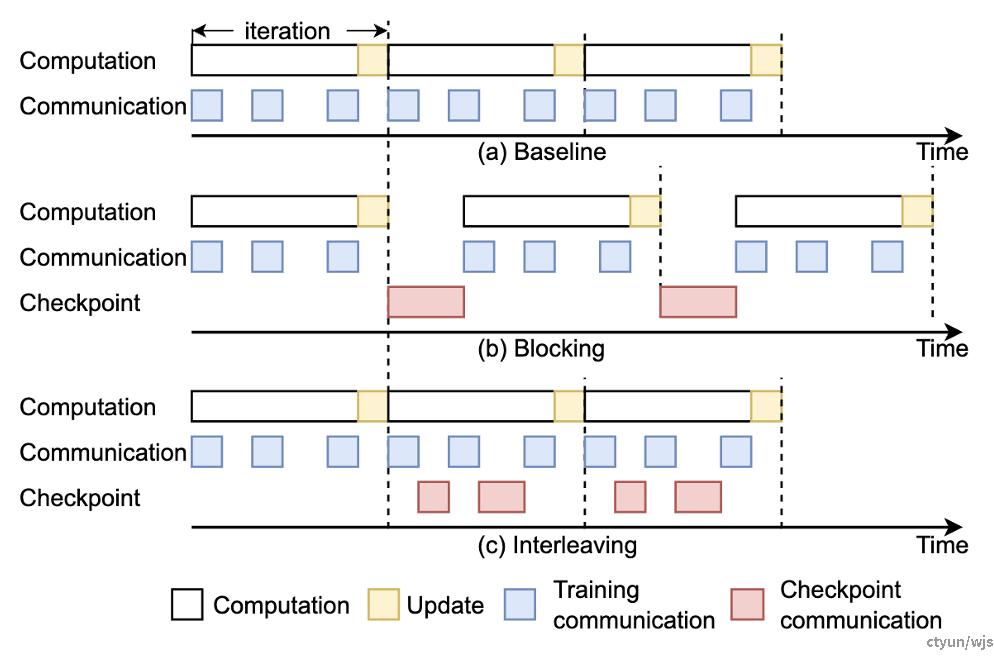
做法:将同步的checkpoint存储优化为异步checkpoint存储,与训练过程平行进行
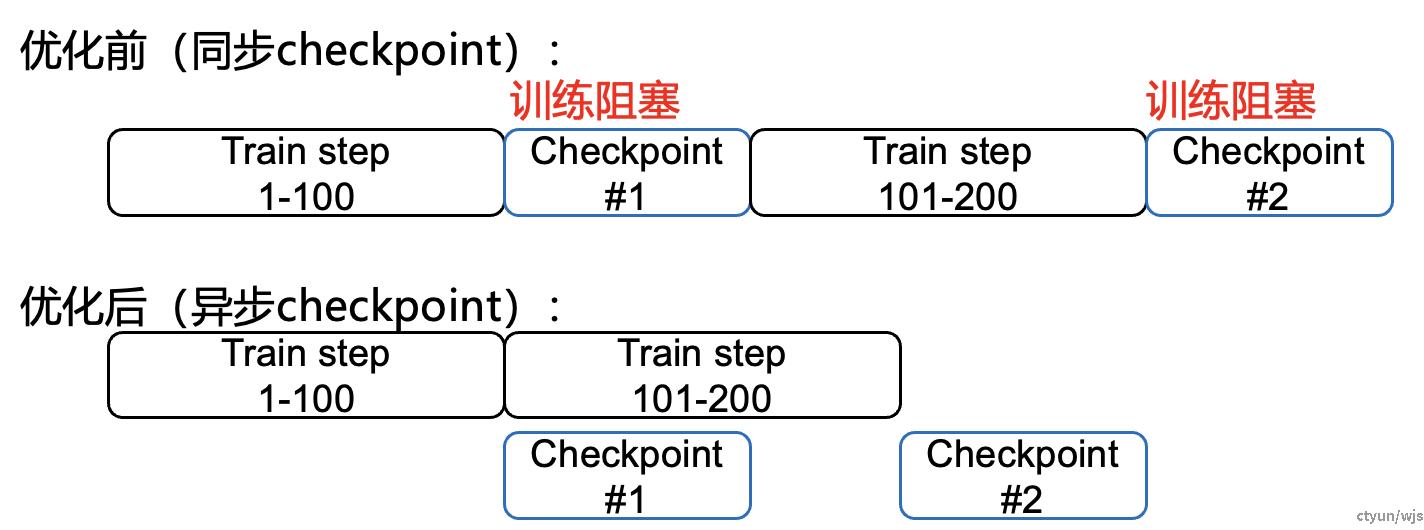
典型工作:蚂蚁dlrover、阿里Easyckpt、港理工REFT、上交BAFT、亚马逊Gemini等
提升程度:以蚂蚁dlrover为例,相较于同步checkpoint,速度提升约10倍
优化点2:Checkpoint阶段化拆分
应对的挑战:
- 挑战1:断点存储较为耗时
- 挑战2:对训练造成阻塞时间较长
目的:将checkpoint的存储与读写过程进行拆分,更细粒
度地进行并行运行,从而提高断点续训效率,减少训练阻塞
(挑战1&2:断点续训提速,减少阻塞)
典型工作:字节ByteCheckpoint
做法:ByteCheckpoint 设计了全异步的存储流水线( Save Pipeline ),将 Checkpoint 存储( P2P 张量传输,D2H 复制,序列化,保存本地等) 、读取(读取、反序列化等)的不同阶段进行拆分,实现高效的流水线执行。
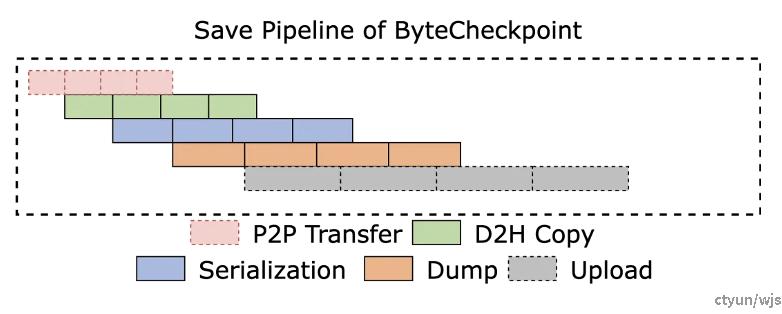
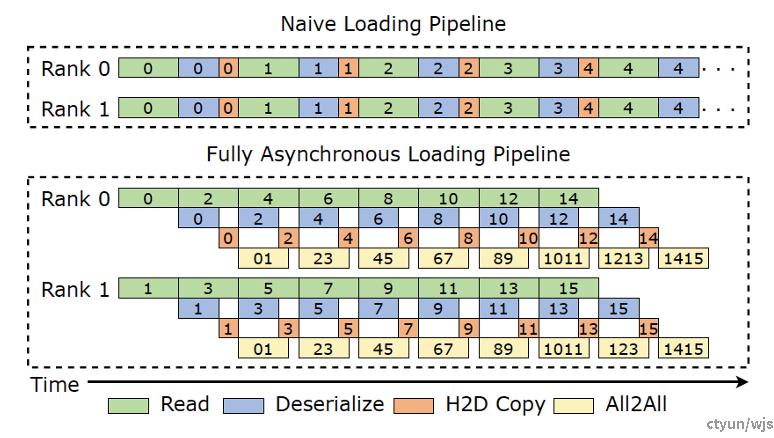
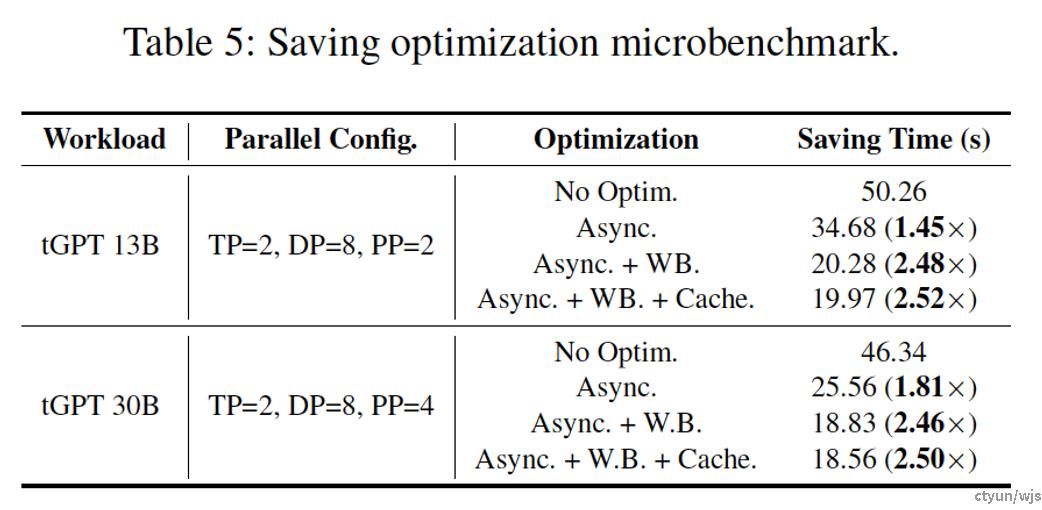
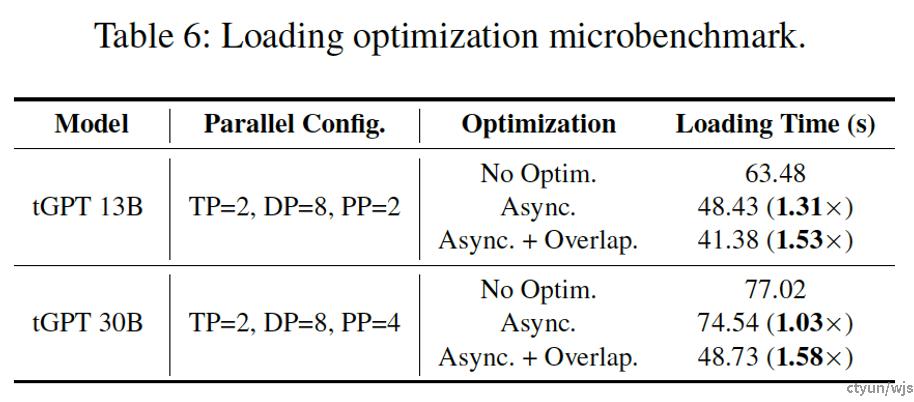
提升程度:本文的checkpoint阶段化拆分方法能将checkpoint存储效率提升约1.45-1.8倍,将读取效率提升约1.5倍
优化点3:惰性阻塞
应对的挑战:
- 挑战1:断点存储较为耗时
- 挑战2:对训练造成阻塞时间较长
目的:防止checkpoint存储过程对训练过程造成不必要的阻塞,只有在不阻塞会造成一致性问题时才进行训练阻塞。(挑战1&2:断点续训提速,减少阻塞)
典型工作:RIT DS-LLM
做法:本方法允许在发出checkpoint request之后立即开始执行下一轮训练,在训练过程进行前传与反传的同时,同步进行checkpoint copying。仅仅当update阶段即将开始时,如果checkpoint拷贝到host memory的过程尚未结束,update阶段会被阻塞。此外,将checkpoint从host memory存储到持久化存储的过程也可以与update过程同步进行。本方法可以被称之为惰性的原因在于,本方法会尽可能的推迟等待的过程,除非不进行等待会造成一致性问题。
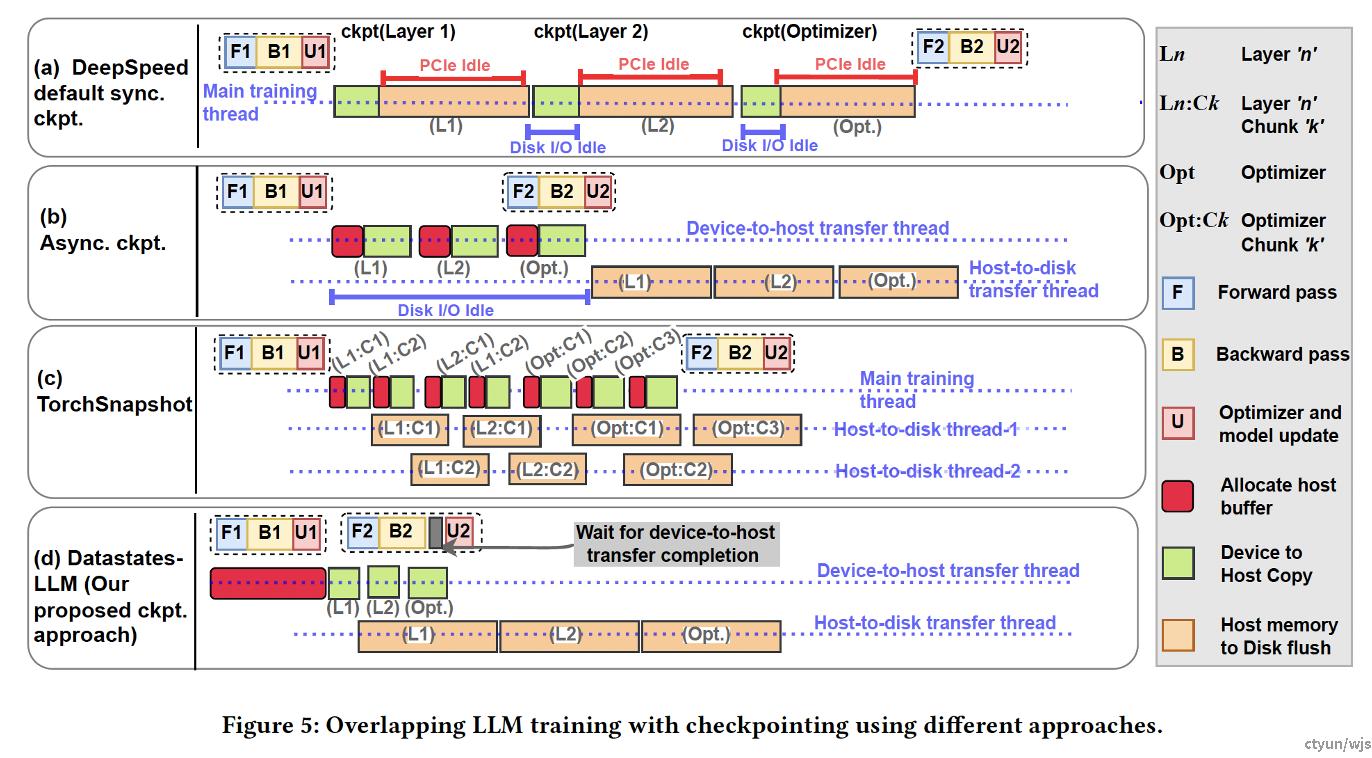
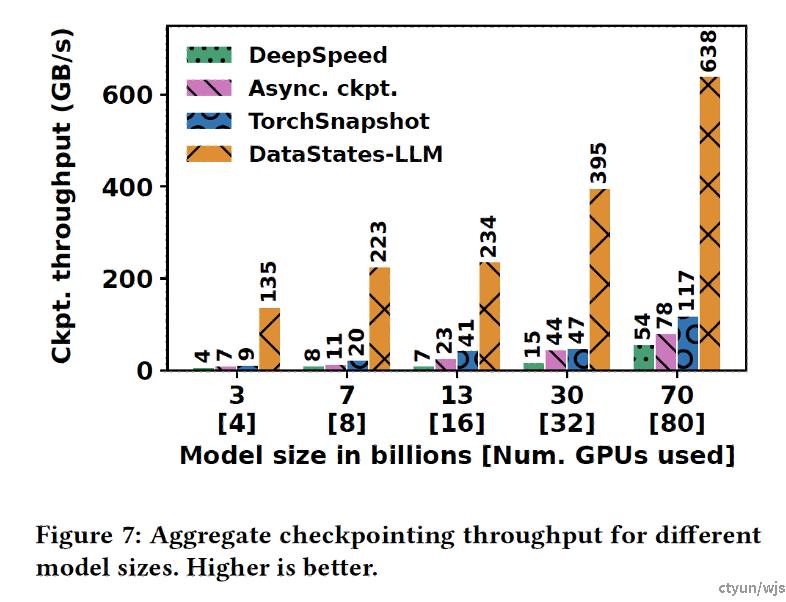
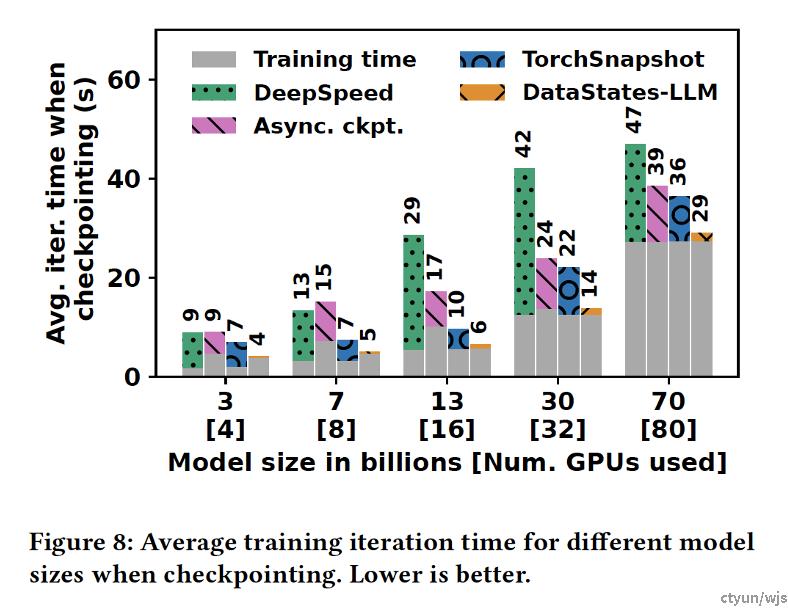
提升程度:本文未进行消融实验。总体而言,该方法将ckpt throughput提升了9-20倍,断点存储的时间开销显著下降
优化点4:部分存储checkpoint
应对的挑战:
- 挑战3:断点较为臃肿:大模型的断点信息量大,如果全都存储较为臃肿
目的:大模型全量存储checkpoint,checkpoint较大,速度较慢,此举对checkpoint进行压缩,防止对checkpoint进行全量存储造成的性能损失。
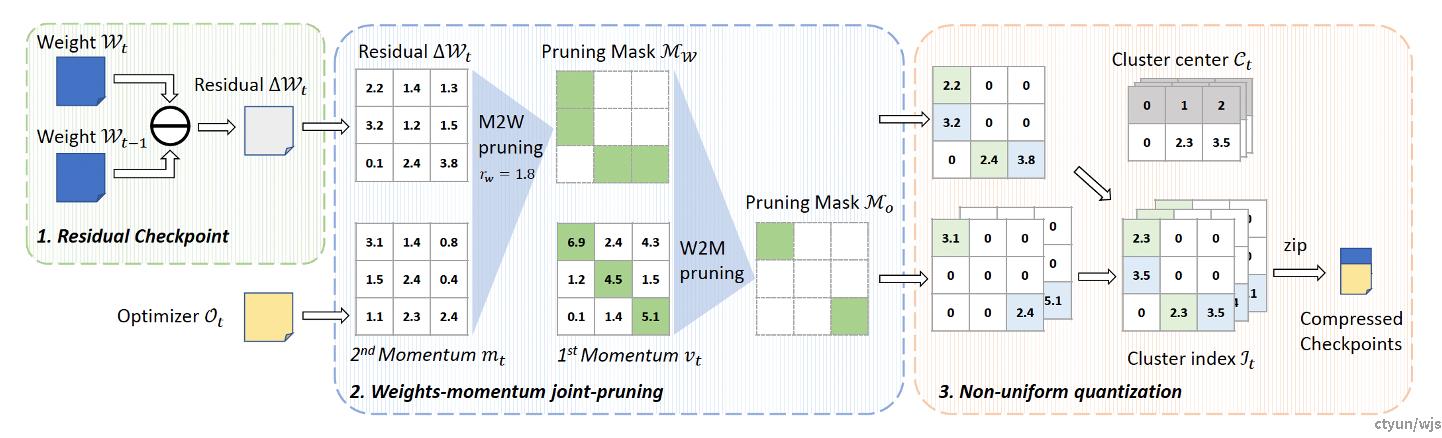
做法:对相邻checkpoint之间的关联进行分析,只存储发生显著改变的部分,从而减小checkpoint尺寸。
典型工作:华为+中科大ExCP
提出residual checkpoint机制,在存储checkpoint的时候只存储梯度变化大于阈值的权重,从而减少存储checkpoint所需的空间并尽可能做到训练性能无损。
该方法给出了训练收敛性证明,并在实验中,
从benchmark分数、实际对话结果展示等形
式验证了该方法对于训练效果是近乎无损的。
提升程度:以ExCP为例,该方法在pythia-
410M与PanGu-pi模型上分别将checkpoint
大小缩减约70、25倍。
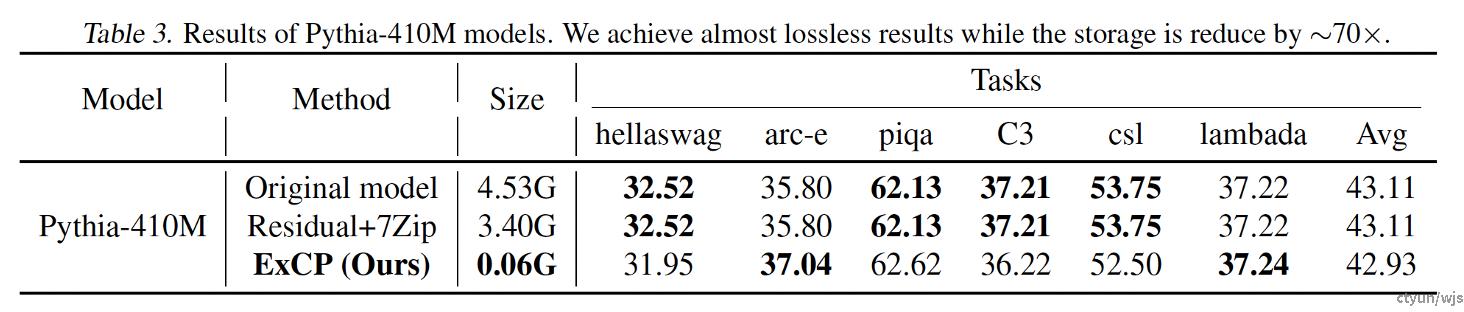
优化点5:实时checkpoint写入
应对的挑战:
- 挑战4:断点存储的时机:断点存储的时机难以决定,进行的时机不当会对训练资源造成占用
目的:优化checkpoint的时机,在GPU-Host Memory-Disk的存储流程中,优化Disk Flush的启动时间机,减小不必要的等待。
典型工作:RIT DS-LLM
做法:在GPU-Host Memory-Disk的存储流程中,没有必要等checkpoint的所有部分都成功复制到主机内存后才开始进行持久化存储的操作。一旦部分检查点数据从 GPU 复制到主机内存,就立即将其刷新到持久化存储中。
提升程度:(文章缺少消融实验,无法看出本优化点单独带来的提升)总体而言,该方法将ckpt Throughput提升了9-20倍,断点存储的时间开销约为纯异步方法的33%-74%
优化点6:通过profiling优化断点传输时机
应对的挑战:
- 挑战4:断点存储的时机:断点存储的时机难以决定,进行的时机不当会对训练资源造成占用
目的:优化checkpoint的时机,充分利用分布式场景下的设备空闲时间,将checkpoint相关操作安排在空闲时段进行,从而减小checkpoint相关操作的时间开销。
典型工作:上海交大BAFT
做法:每个节点在完成局部模型计算任务后,都需要等待前节点或后节点发送的激活值或梯度来继续计算。在等待数据到达时,设备处于停滞状态,从而产生气泡。这些气泡会造成系统资源的浪费,但我们可以利用它们进行checkpoint相关操作,以消除checkpoint带来的开销。
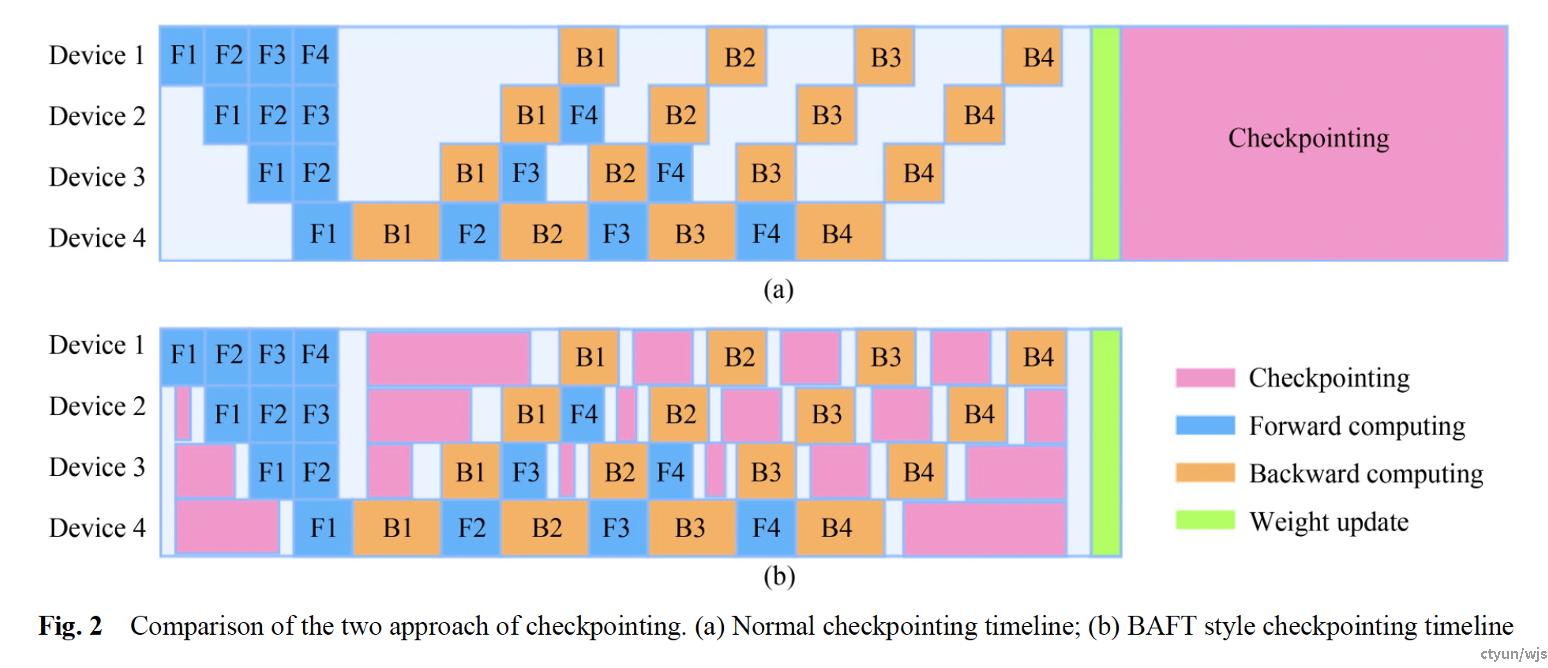
提升程度:BAFT方法可以实现几乎零开销的checkpoint机制。
优化点7:分布式存储/读取checkpoint
应对的挑战:
- 挑战5:分布式场景下需要考虑因素众多:checkpoint的任务量均衡、防止断点续训引起不必要的通讯代价等
目的:防止checkpoint保存造成不必要的通信代价,防止单点任务量过大。
做法:对checkpoint进行分布式的存储与读取,防止不必要的通信代价,防止单点任务量过大。
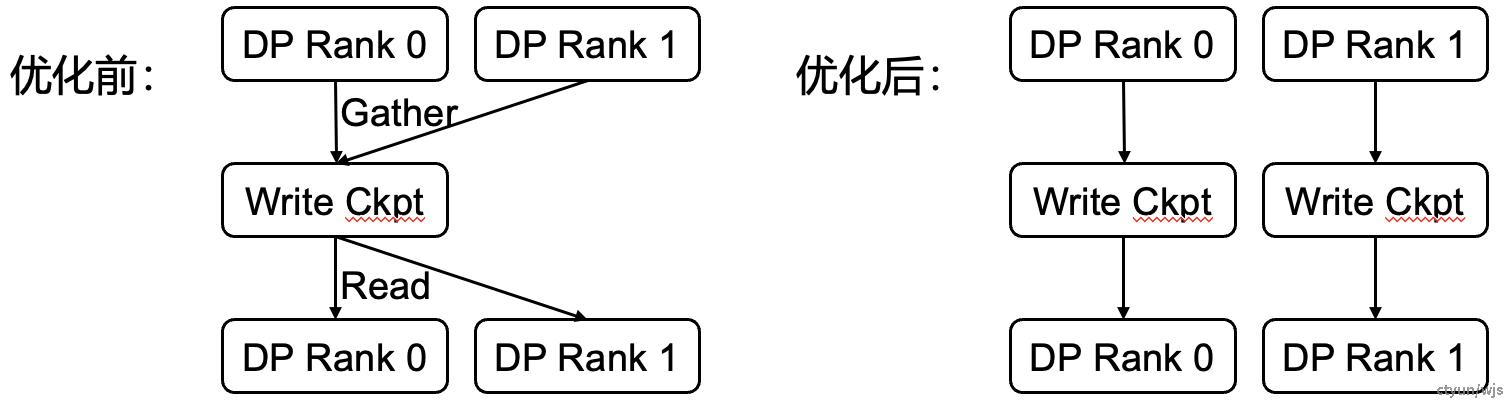
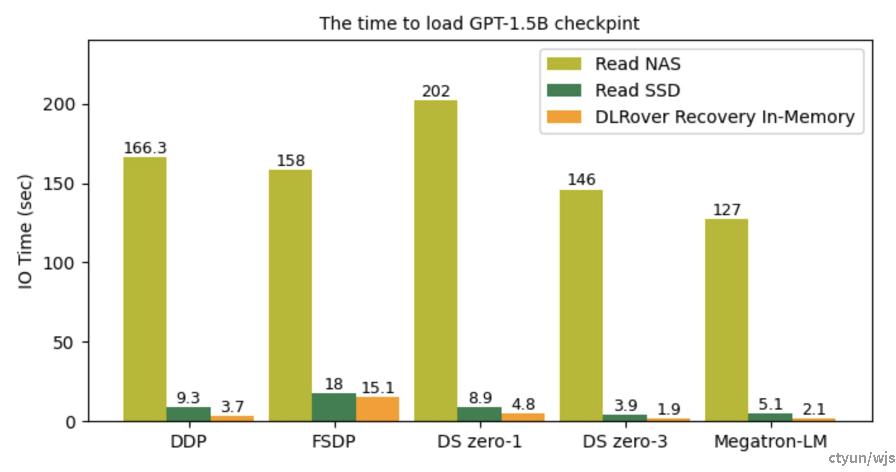
典型工作:蚂蚁DLRover
提升程度:将checkpoint loading时间缩减约25%。
优化点8:Checkpoint传输路径优化
应对的挑战:
- 挑战5:分布式场景下需要考虑因素众多:checkpoint的任务量均衡、防止断点续训引起不必要的通讯代价等
目的:分布式场景下利用传输速率最高的传输路径传输checkpoint,减少不必要的通信代价。
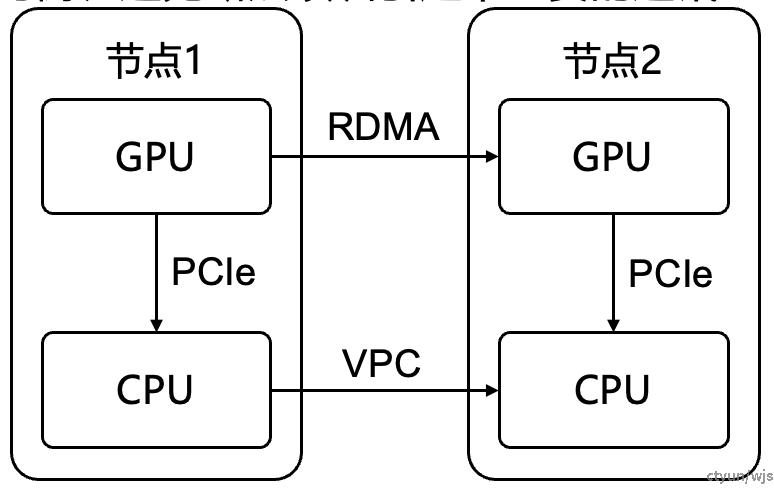
做法:对于将checkpoint统一发送至节点2进行存储的过程而言,可以通过profiling的方式,选择以下路径中较快的:
- 路径1:GPU@Node1 – GPU@Node2 – CPU@Node2
- 路径2:GPU@Node1 – CPU@Node1 – CPU@Node2
路径1中的GPU间断点传输会对训练所需要的GPU间通信效
率造成影响,具体哪条路径更优需要通过profiling决定。
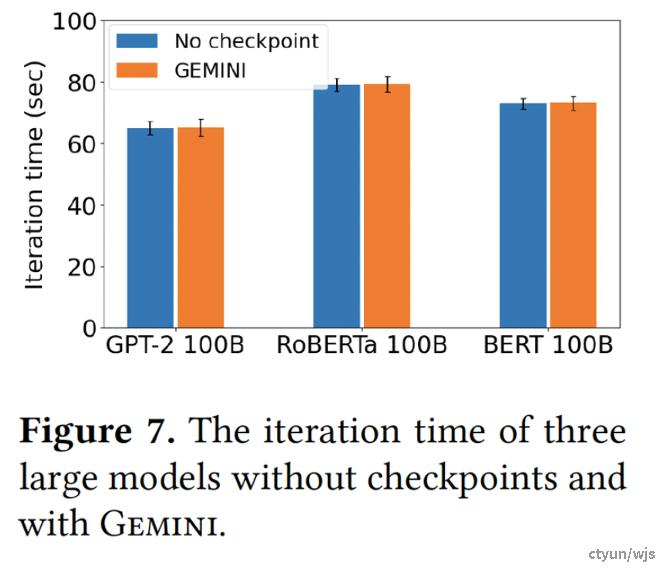
典型工作:亚马逊Gemini
提升程度:论文缺少体现优化点单独提升程度的消融实验,但从总的Checkpoint效率来看,Gemini可以实现几乎零开销的断点保存。
优化点9:支持并行策略灵活调整
应对的挑战:
- 挑战6:断点续训灵活性差:大多数断点续训机制和大模型并行训练策略高度绑定,不支持并行策略灵活变动
目的:在出现训练中断时,可用于替换的计算节点不足,或是需要暂停训练过程,进行并行策略调整,checkpoint技术需要打破对于并行策略的高度绑定,支持并行策略的灵活调整。
现有方法的弊端:现有的绝大多数断点续训技术与并行策略高度绑定,续训时需保持并行策略不变
典型工作:微软UniversalCheckpoint
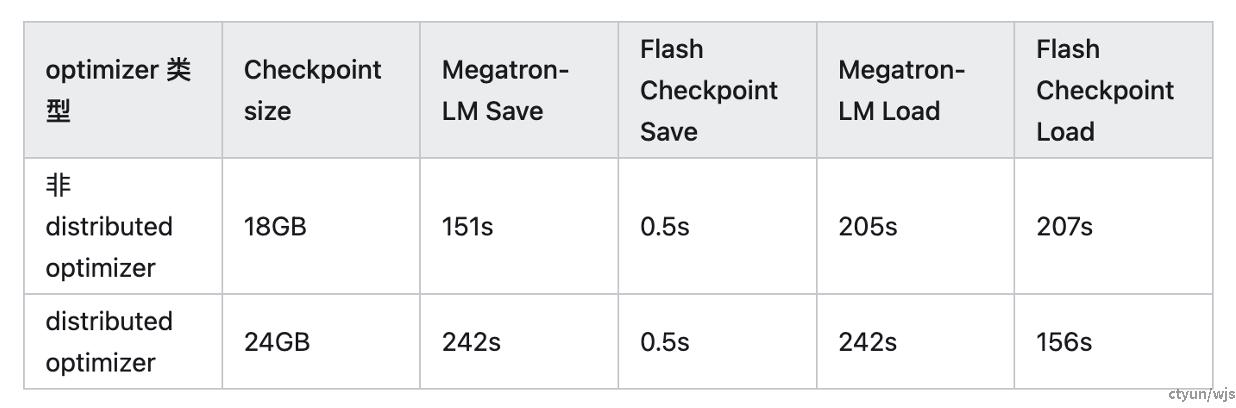
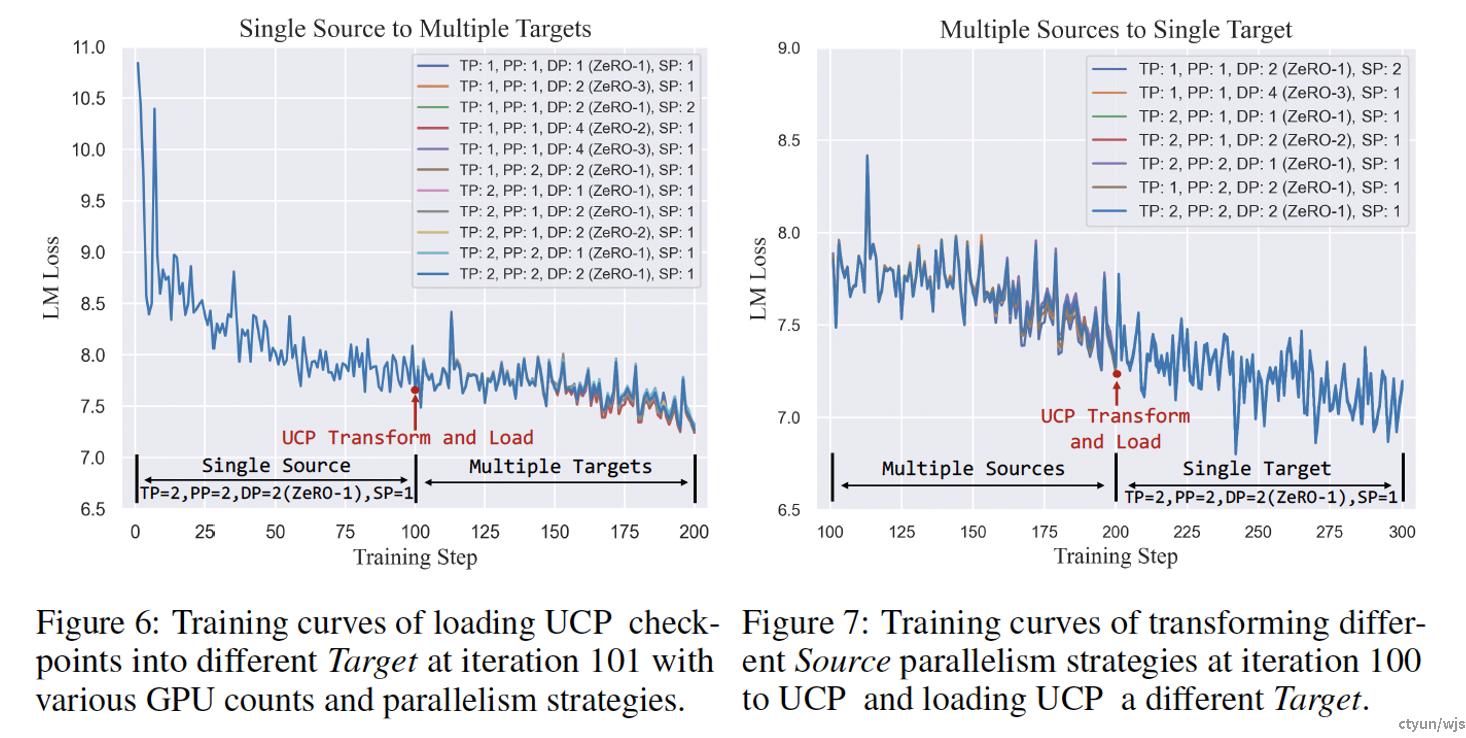
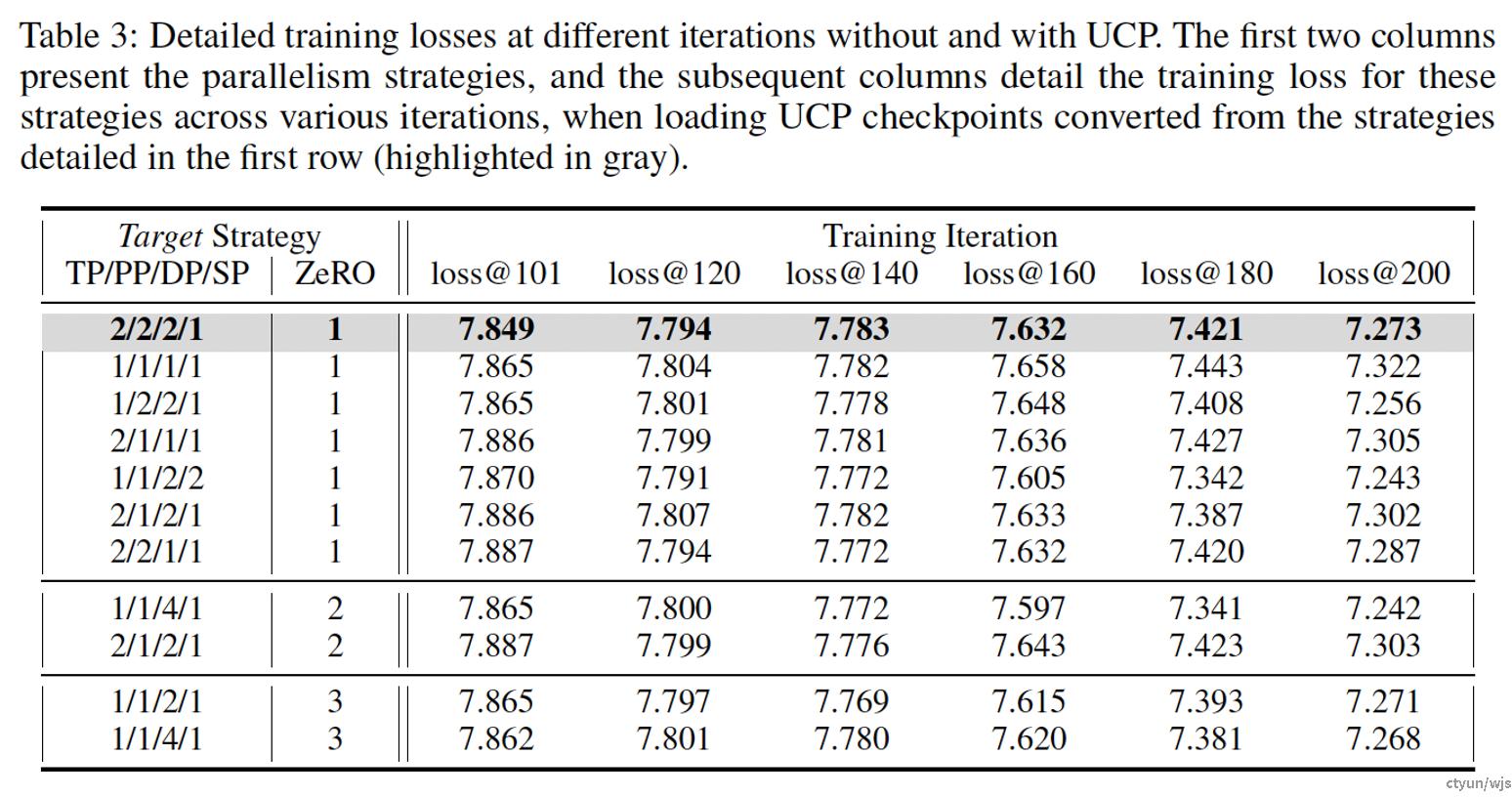
做法:破除checkpoint对于并行策略的依赖,使得checkpoint支持并行策略的灵活调整。提出原子checkpoint的存储形式作为断点中间存储形式,提出UCP语言,实现checkpoint的拆分,以及在续训时根据新并行策略进行checkpoint的读取
提升程度:论文验证了所提方法在变动3D并行策略、变动卡数、变动节点数量的场景下的断点续训效果,基本可以实现无损续训。
优化点10:内存预分配
应对的挑战:
- 挑战7:断点续训与硬件高效配合
目的:预先分配checkpoint需要的内存空间,防止重复内存分配。
做法:在内存中事先分配足够的空间用于存储checkpoint,之后的checkpoint存储过程均会复用这部分内存,以此防止内存的重复分配所造成的开销。
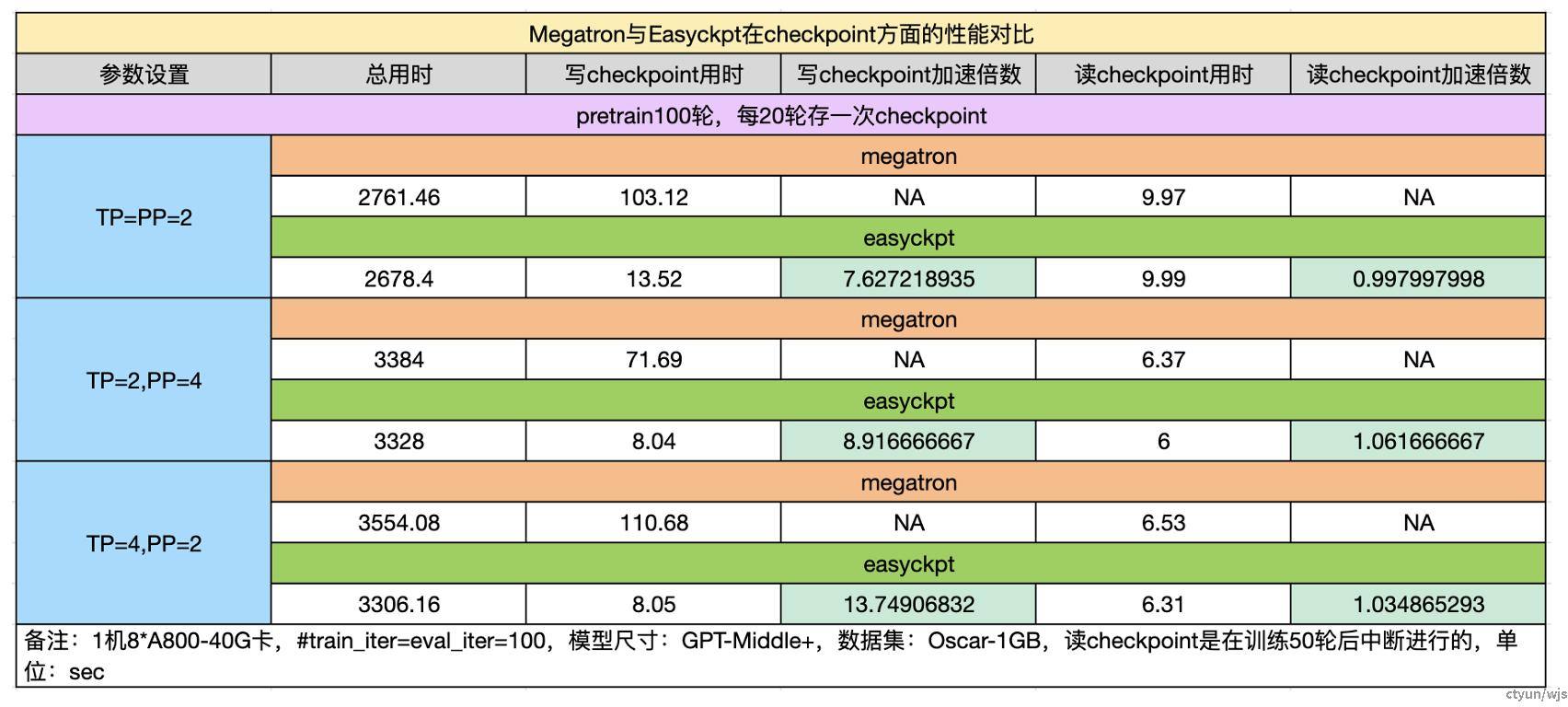
典型工作:RIT DS-LLM、阿里EasyCkpt
提升程度:以阿里EasyCkpt为例,最终能够将Checkpoint存储速度提升约7.6-13.8倍。
优化点11:断点多副本存储
应对的挑战:
- 挑战8:硬件损坏导致checkpoint丢失,导致无法正常续训
目的:将断点在多处进行存储备份,以在出错时提升恢复概率。
典型工作:亚马逊Gemini
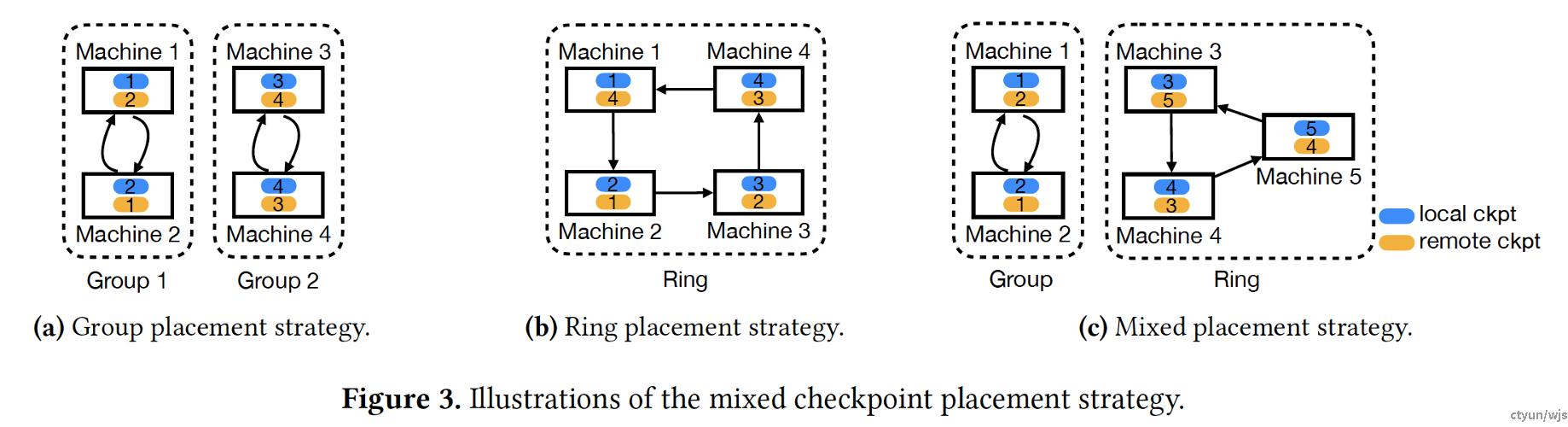
做法:Gemini采用了断点多副本存储机制,包含group和ring两种机制。在Group机制中,假设机器数为N,副本数为m,Gemini将所有worker分成N/m个组。在训练过程中,每台机器将其断点广播给同一组中的其他m-1台机器,还将一份断点写入自己的CPU内存作为本地副本。
在ring机制中,每台机器将检查点从GPU内存写入本地CPU内存,并将检查点发送给环中从其左边开始的连m-1台机器。
这种做法可以有效防止因为机器故障造成的断点保存丢失,从而提升断点续训的恢复率。
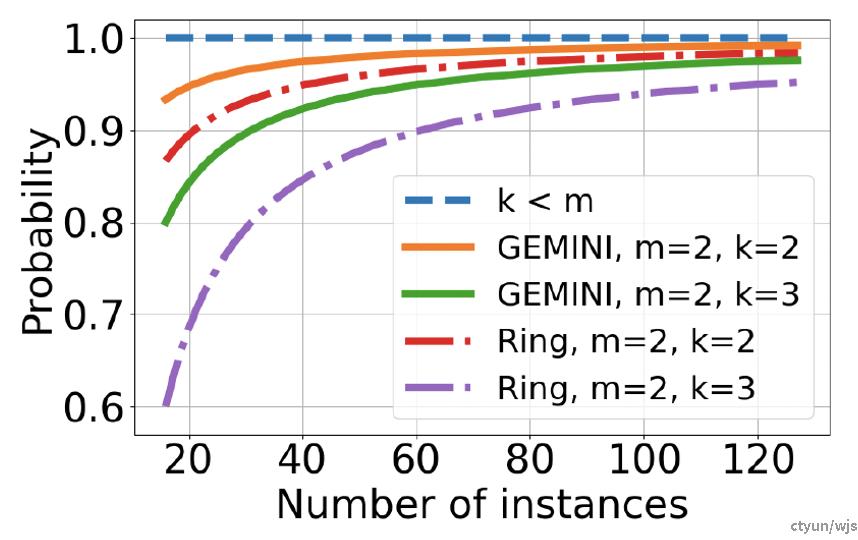
提升程度:以Gemini为例,16节点,2副本,2台机器损坏,ring策略,恢复率93.3%
优化点12:parity check保护checkpoint
应对的挑战:
- 挑战8:硬件损坏导致checkpoint丢失,导致无法正常续训
目的:利用parity check保护因硬件损坏丢失的checkpoint可恢复。
典型工作:港理工REFT
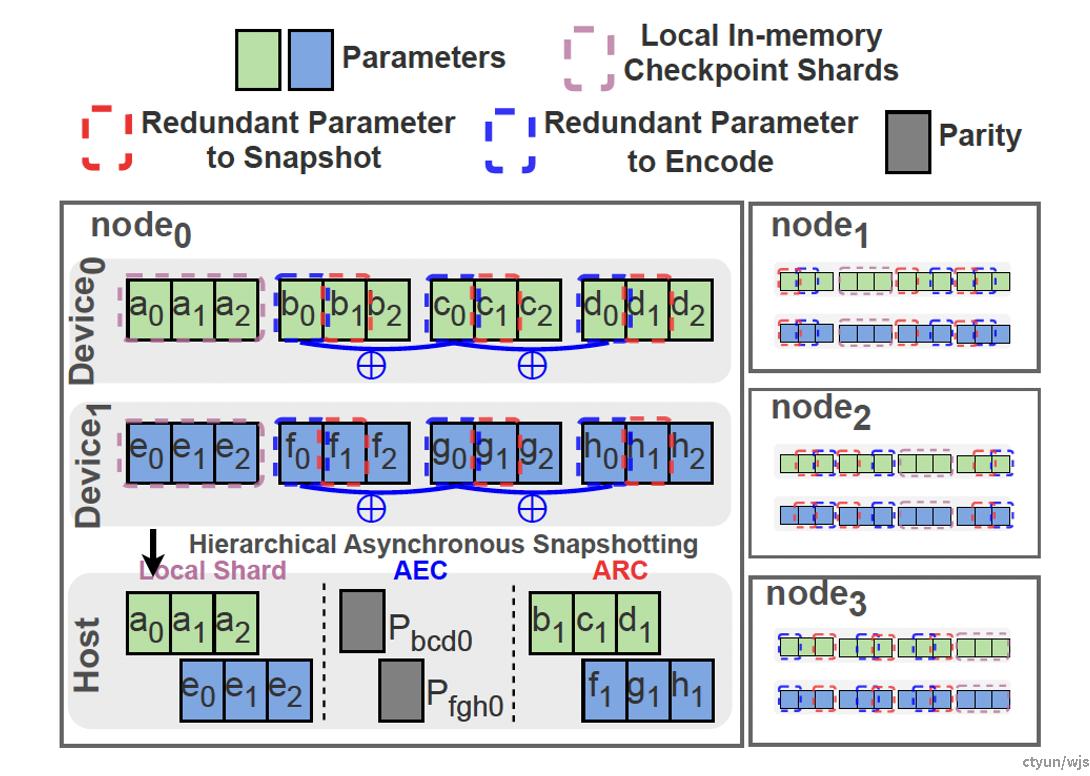
做法:对不同的checkpoint做XOR运算,使得其中某一个Checkpoint因硬件损坏发生丢失时,靠其他的checkpoint以及parity code可以算出丢失的checkpoint,从而提高Checkpoint的可恢复性。
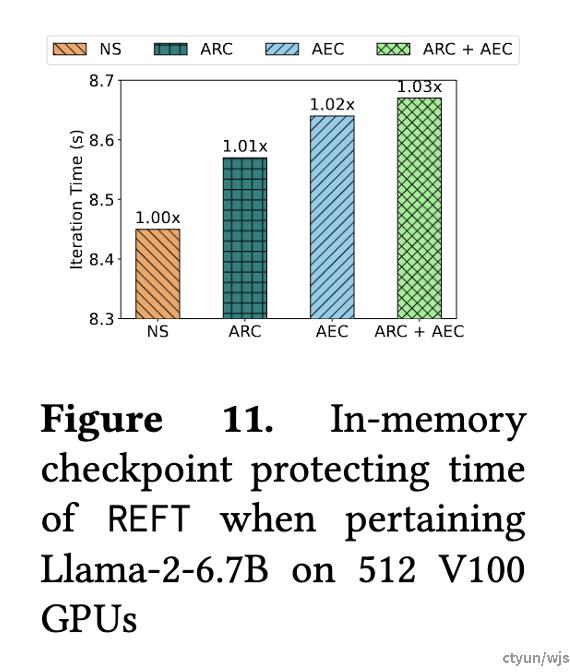
提升程度:在使用512张V100训练Llama2-6.7B模型时,REFT所采用的策略只对checkpoint存储造成约1-3%的性能影响。
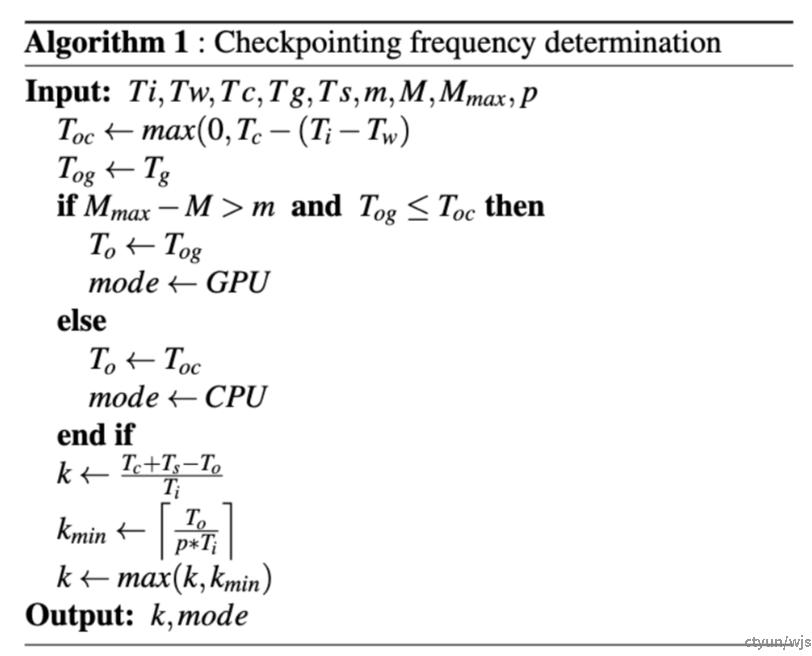
优化点13:自适应调整checkpoint频率
应对的挑战:
- 挑战9:断点的存储频率较难掌握:太频繁浪费资源,间隔太长导致续训后浪费太多算力
目的:没有一种checkpoint频率适用于所有模型、硬件和训练环境。checkpoint频率影响因素众多,设置过大过小都不合适。此外,训练环境的波动也使得静态的checkpoint频率未必最优。
典型工作:微软CheckFreq
做法:CheckFreq首先使用profiler监控前X iteration的iteration时间、权重更新时间、CPU、GPU存储checkpoint的时间、持久化存储写入checkpoint的时间、GPU显存占用、checkpoint大小等信息,之后根据GPU显存可用情况决定存储路径:GPU-Storage、GPU-CPU-Storage。然后,根据存储checkpoint的时间开销不大于总时间p%的原则,计算出存储checkpoint的频率。Profiling是动态进行的,checkpoint的频率也是动态决定的。
优势:针对不同模型、不同训练环境,动态调整checkpoint频率,在不造成过大开销的前提下,保证checkpoint尽可能频繁,从而降低由于checkpoint过于不频繁导致续训时的算力浪费。