karpenter把功能拆得很细,用到大量controller
func NewControllers(
mgr manager.Manager,
clock clock.Clock,
kubeClient client.Client,
recorder events.Recorder,
cloudProvider cloudprovider.CloudProvider,
) []controller.Controller {
// 整个集群的缓存
cluster := state.NewCluster(clock, kubeClient)
// 核心控制器,启用新的NodeClaim以兼容pending pod
p := provisioning.NewProvisioner(kubeClient, recorder, cloudProvider, cluster)
// pod驱逐队列,生产者为node terminator
evictionQueue := terminator.NewQueue(kubeClient, recorder)
// 中断队列,生产者为disruption controller
disruptionQueue := orchestration.NewQueue(kubeClient, recorder, cluster, clock, p)
return []controller.Controller{
p, evictionQueue, disruptionQueue,
// 中断控制器,判断NodeClaim是否需要中断,如需要则发送命令到中断队列
disruption.NewController(clock, kubeClient, p, cloudProvider, recorder, cluster, disruptionQueue),
// watch pending pod,发送到Provisioner的批处理窗口
provisioning.NewPodController(kubeClient, p),
// watch 可调度的node,发送到Provisioner的批处理窗口
provisioning.NewNodeController(kubeClient, p),
// 更新hash到nodepool,更新到所有对应NodeClaim的annotations中
nodepoolhash.NewController(kubeClient),
// 删除过期的NodeClaim
expiration.NewController(clock, kubeClient),
// 以下五个控制器用于更新cluster缓存
informer.NewDaemonSetController(kubeClient, cluster),
informer.NewNodeController(kubeClient, cluster),
informer.NewPodController(kubeClient, cluster),
informer.NewNodePoolController(kubeClient, cluster),
informer.NewNodeClaimController(kubeClient, cluster),
// watch deleting node,执行的操作包括删除 NodeClaim、确保底层实例被删除等,最后移除node的finalizer
termination.NewController(clock, kubeClient, cloudProvider, terminator.NewTerminator(clock, kubeClient, evictionQueue, recorder), recorder),
// 以下三个控制器用于统计指标
metricspod.NewController(kubeClient),
metricsnodepool.NewController(kubeClient),
metricsnode.NewController(cluster),
// 当nodepool的nodeclass引用发生变化时,校验是否存在nodeclass,并更新nodepool的conditions
nodepoolreadiness.NewController(kubeClient, cloudProvider),
// 统计当前集群已经分配给nodepool的资源容量,并更新resources字段(cpu、mem)
nodepoolcounter.NewController(kubeClient, cluster),
// 校验nodepool的属性是否合法,结果更新到Conditions中
nodepoolvalidation.NewController(kubeClient),
// watch pod,更新对应NodeClaim的LastPodEventTime
podevents.NewController(clock, kubeClient),
// 检查NodeClaim的一致性,并更新NodeClaim的Conditions
nodeclaimconsistency.NewController(clock, kubeClient, recorder),
// NodeClaim生命周期控制器,调用provider进行创建/删除,维护NodeClaim的conditions
nodeclaimlifecycle.NewController(clock, kubeClient, cloudProvider, recorder),
// NodeClaim gc控制器,当NodeClaim为已注册且对应node为not ready且时,删除该NodeClaim
nodeclaimgarbagecollection.NewController(clock, kubeClient, cloudProvider),
// 根据nodeclaim状态维护NodeClaim的 Drifted 和 Consolidatable 两个condiction,会影响NodeClaim是否会被中断
nodeclaimdisruption.NewController(clock, kubeClient, cloudProvider),
status.NewController[*v1.NodeClaim](kubeClient, mgr.GetEventRecorderFor("karpenter")),
status.NewController[*v1.NodePool](kubeClient, mgr.GetEventRecorderFor("karpenter")),
}
}其中比较关键的controller有Provisioner、disruption和nodeclaimlifecycle
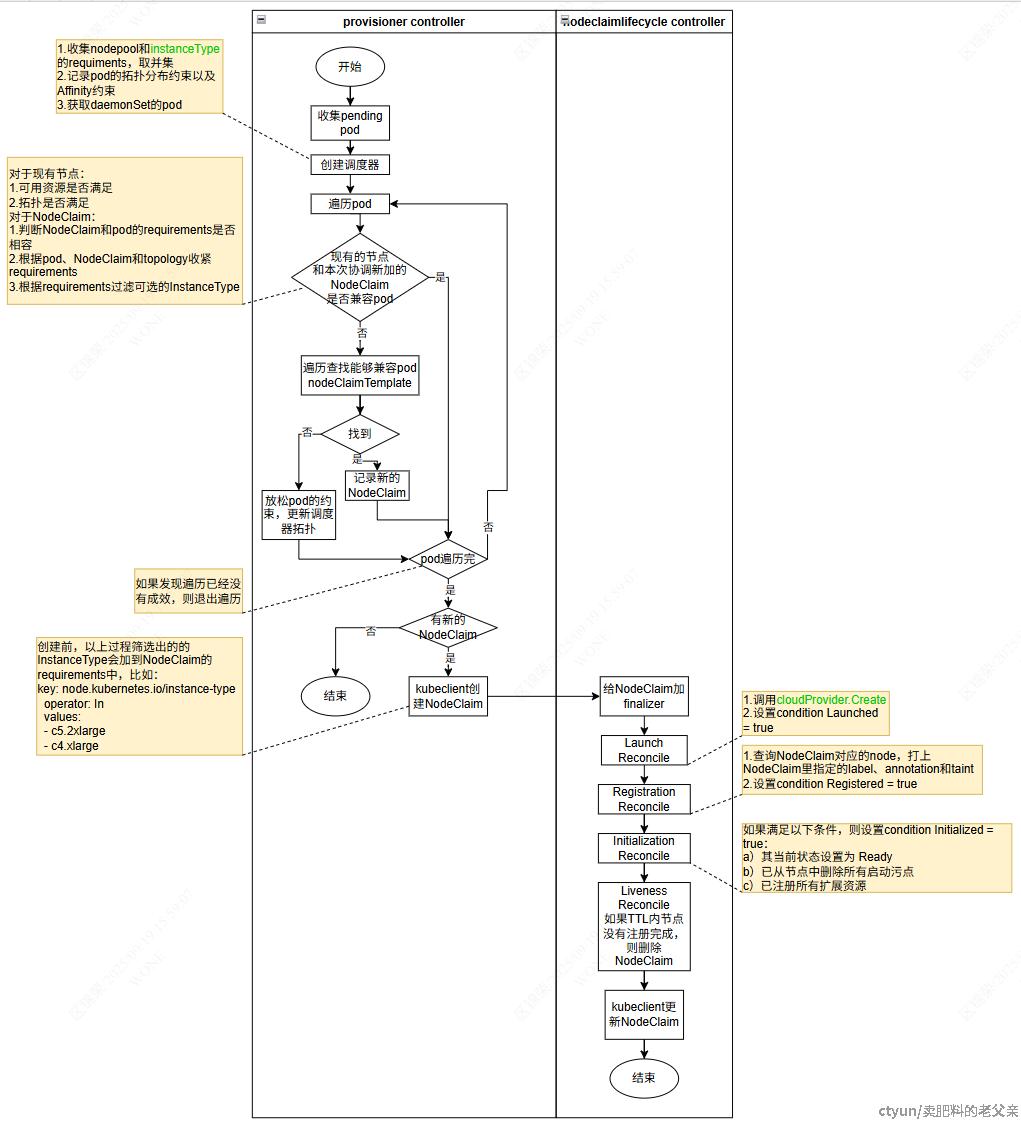
扩容流程
当出现pending状态的pod时会触发扩容流程
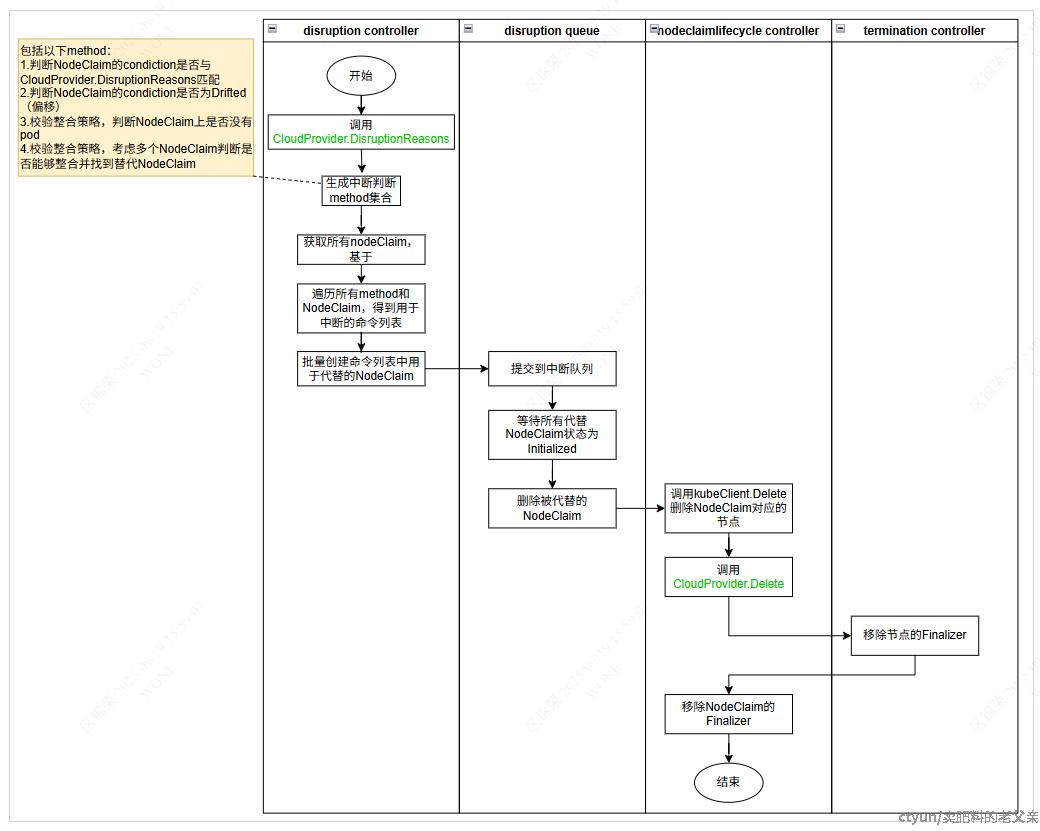
中断流程
当NodeClaim的Drifted或者其他指定condiction为true,以及集群出现过剩容量时,会触发中断流程