


什么是 Skill
Skill 英译为 技能,每一个Skill期望为Agent扩展一种 能够处理特定事务的能力。
本质上,Skill 是用于指导AI大模型完成一个特定事务的 一套标准化流程 + 一组行为约束 + 一组基础工具/脚本 + 一组必要资源。
其中:
- 一套标准化流程:定义完成该事务的步骤顺序 —— 先做什么、后做什么、最后做什么。这是AI的行动指南和路线图,确保执行路径清晰可控,不会跑偏。
- 一组行为约束:规定AI必须遵守的规则和边界 —— 哪些必须做、哪些绝对不能做、输出格式是什么、质量标准是什么。这是AI的 "军规",保障结果的规范性、安全性和一致性。
- 一组基础工具/脚本:提供AI可调用的具体能力,如函数、API、命令行工具或代码脚本。AI不需要从零实现每个步骤,直接调用这些工具即可高效完成子任务。
- 一组必要资源:提供完成任务所需的外部素材和知识,如配置文件、模板文件、规则库、数据字典、参考文档等。这些是AI工作时需要查阅和引用的"资料库"。
举个例子,在一家小公司,没有实施企业应用集成,每月发工资都是人事MM一笔一笔账核算出来的。大体有这些:
- 获取员工基本薪资表,做成 Excel 基表
- 获取员工的考勤数据,计算 请假、迟到、早退等导致的薪资扣发
- 获取员工项目奖金、绩效奖金相关数据,计算奖、惩情况与金额
- 汇总员工应发工资
- 导入社保抵扣项
- 计算个税
- 生成实发工资表
现在,有个 硅基员工 来接手这个枯燥的任务。
为了能够顺利交接任务,找了之前人事MM出了一个 《员工工资核算操作手册》,由以下四部分构成:
操作流程:
- 从人事系统中,导出《部门员工及基础薪资表》,按计发工资年月进行命名,如 2026-05-员工工资表.csv。该步骤可以使用 download_member_salary.py脚本。
- 从考勤系统中,导出 《部门员工考勤统计表》,按计发工资年月进行命名,如 2026-05-员工考勤统计表.csv。该步骤可以使用 download_member_attendance.py脚本。
- 从人事系统,导出《部门员工奖金表》,按计发工资年月进行命名,如 2026-05-员工奖金表.csv。该步骤可以使用 download_member_bonus.py脚本。
- 汇总员工奖金、绩效奖金相关数据,计算奖、惩情况与金额,汇总员工考勤导致的薪资扣发情况与金额,并按员工工号合并到2026-05-员工工资表.csv
- 依据《2026年个税税率表》、《员工社保缴纳基数库》计算社保抵扣项,和个税申报、扣除金额,按员工工号合并到2026-05-员工工资表.csv
- 统计员工实发工资,按员工工号合并到2026-05-员工工资表.csv
要求与注意事项:
- 需要申请各系统权限,获取登录授权码,并配置到脚本中。
- 实发工资必须保留两位小数
- 禁止修改考勤、奖金等原始数据
- 最终输出必须是UTF-8编码的CSV文件
- 过程数据保存到临时目录,处理完成后立即删除
工具脚本说明:
| 脚本名称 | 功能说明 | 调用方式 |
|---|---|---|
| download_member_salary.py | 从人事系统导出基础薪资表 | python download_member_salary.py --month 2026-05 --output ./data/ |
| download_member_attendance.py | 从考勤系统导出考勤统计表 | python download_member_attendance.py --month 2026-05 --output ./data/ |
| download_member_bonus.py | 从人事系统导出奖金表 | python download_member_bonus.py --month 2026-05 --output ./data/ |
| merge_salary_data.py | 合并工资、考勤扣款、奖金数据 | python merge_salary_data.py --salary ./data/2026-05-员工工资表.csv --attendance ./data/2026-05-员工考勤统计表.csv --bonus ./data/2026-05-员工奖金表.csv --output ./temp/ |
| calc_tax_and_social.py | 计算社保和个税 | python calc_tax_and_social.py --input ./temp/merged_salary.csv --tax-table ./config/tax_2026.json --social-base ./config/social_base.json --output ./temp/ |
| calc_net_salary.py | 计算实发工资并生成最终报表 | python calc_net_salary.py --input ./temp/tax_social_deducted.csv --output ./output/2026-05-实发工资表.csv |
| cleanup_temp.py | 清理临时目录 | python cleanup_temp.py --temp-dir ./temp/ |
必要文件说明:
| 文件名称 | 用途说明 | 格式/来源 |
|---|---|---|
| 2026年个税税率表 | 计算个人所得税的税率标准和速算扣除数 | JSON格式,包含起征点、级距、税率、速算扣除数 |
| 员工社保缴纳基数库 | 每个员工的社保缴纳基数(养老、医疗、失业等) | CSV格式,字段:工号、姓名、社保基数、公积金基数 |
| 系统授权码配置文件 | 存储各系统访问的token和授权信息 | config/auth.json,需提前申请并配置 |
| 考勤扣款规则表 | 迟到、早退、事假、病假对应的扣款标准 | config/deduction_rules.json |
有了这本《员工工资核算操作手册》,硅基员工 就能按照固定流程,调用现成脚本,遵守各项约束,查阅必要文件,稳定、准确地完成每月工资核算任务,无需每次重新思考步骤,也不会因为“没经验”而出错。
而这个 面向 硅基员工 的《员工工资核算操作手册》本质就是一个 Skill。
Skill 解决的核心问题
通过上面《员工工资核算操作手册》的例子,我们可以直观感受到,Skill 的作用,就是把重复的 指令、经验、流程,变成可版本化、可分发、可执行的文档和脚本。
主要解决:
1. 消除重复指令
以往,相同的提示词,不同场景、不同项目、不同分支,甚至每个提交都 复制+粘贴 一遍。
写成 Skill 后 AI 自己加载,不用你再打字。比如"本项目禁止直接修改 production 分支的配置文件",写在 Skill 里,每次 AI 动手前都会读到。
2. 知识、经验传承
你踩过的坑、总结出的最佳实践、团队规定的流程,如果不写下来,就只能靠口口相传。人传人会衰减,AI 传 AI 也不会。Skill 把这些经验变成可版本化、可共享、可迭代的有型资产。
3. 提升效率
毫无疑问,团队通过将经过验证的技术、经验、流程,通过 Skill方式进行固化和分享,能够大幅度提升团队效率。
一方面,团队成员就可以站在巨人的肩膀上,大踏步前进,而不用把河底的石头再摸一遍;另一方面,同样的事情,不同的人处理的方式不一样效果也参差不齐,但现在大家都对着一套skill进行打磨,能够实现 1 + 1 > 2 的效果。
解剖一个 Skill
上一篇 《Superpowers 工程化实践》我们介绍了Superpowers通过一些列Skill,从而实现对所有变更进行标注化、流程化管理,使AI Coding从野路子走成正规军。
进入Superpowers 的 Skills 存放目录结构如下:

核心是skills目录下的一些列skill实现。 下面我们就解剖 brainstorming 看一看Skill 的庐山真面目...
Skill的目录结构
用 tree 命令 展开 brainstorming 目录:
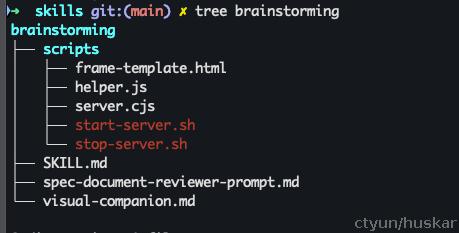
其中 SKILL.md 文件是 Skill 的核心文件,每个一个Skill必备,除此之外,其他文件和目录都是可选的(按Skill需要进行扩展)。
比如,Superpowers 的 receiving-code-review Skill 就仅有一个 SKILL.md文件:

Skill目录中常见的目录和文件介绍如下(约定俗成的一些目录和文件):
| 目录/文件 | 类型 | 作用说明 |
|---|---|---|
SKILL.md |
核心文件 | 这是 Skill 的"大脑",AI 首先读取此文件来理解该 Skill 的目标、流程、约束和行为模式 |
scripts/ |
目录 | 存放可执行脚本(Python、Shell、Node.js 等)。AI 可调用这些脚本来完成具体子任务,如数据下载、文件处理、API 调用等 |
scripts/*.py |
脚本文件 | Python 脚本,用于数据处理、计算、文件操作等任务 |
scripts/*.sh |
脚本文件 | Shell 脚本,用于环境配置、服务启停、批量操作等系统级任务 |
scripts/*.js |
脚本文件 | Node.js 脚本,用于前端相关或 JavaScript 生态的工具 |
references/ |
目录 | 存放参考文档和资源文件,供 AI 查阅和学习。这些不是直接执行的代码,而是提供上下文和知识支撑 |
references/*.md |
参考文档 | 详细的说明文档、规范指南、最佳实践等,AI 在执行过程中可按需查阅 |
references/*.json |
配置文件 | 结构化数据,如规则库、映射表、配置参数等 |
references/*.csv |
数据文件 | 表格数据,如税率表、社保基数库、员工信息表等 |
assets/ |
目录 | 存放静态资源文件,如模板、图片、样式文件等 |
assets/*.html |
模板文件 | HTML 模板,用于生成报告、页面或可视化内容 |
assets/*.css |
样式文件 | CSS 样式表,用于格式化输出内容 |
assets/*.png/*.svg |
图片资源 | 图标、示意图等图像文件 |
templates/ |
目录 | 存放代码模板或文件模板,AI 可基于这些模板生成输出文件 |
templates/*.template |
模板文件 | 代码片段或文件结构模板,可包含占位符供 AI 替换填充 |
config/ |
目录 | 存放配置文件,定义 Skill 的行为参数、环境变量、认证信息等 |
config/*.json/*.yaml |
配置文件 | Skill 的运行时配置,如 API 密钥、路径设置、开关选项等 |
tests/ |
目录 | 存放测试脚本和测试数据,用于验证 Skill 的正确性 |
tests/test_*.py |
测试文件 | 单元测试或集成测试脚本 |
tests/fixtures/ |
测试数据目录 | 存放测试用的样例数据文件 |
docs/ |
目录 | 存放 Skill 的说明文档、使用示例、架构设计等 |
docs/*.md |
文档文件 | 详细的使用说明、设计文档、变更日志等 |
examples/ |
目录 | 存放示例代码或示例输入输出,帮助用户理解如何使用该 Skill |
examples/*.md |
示例文件 | 使用示例场景的说明文档 |
examples/*.csv/*.json |
样例数据 | 演示用的输入输出样例 |
SKILL.md
打开该文件,是一篇markdown 纯文本, 截取了一部分:
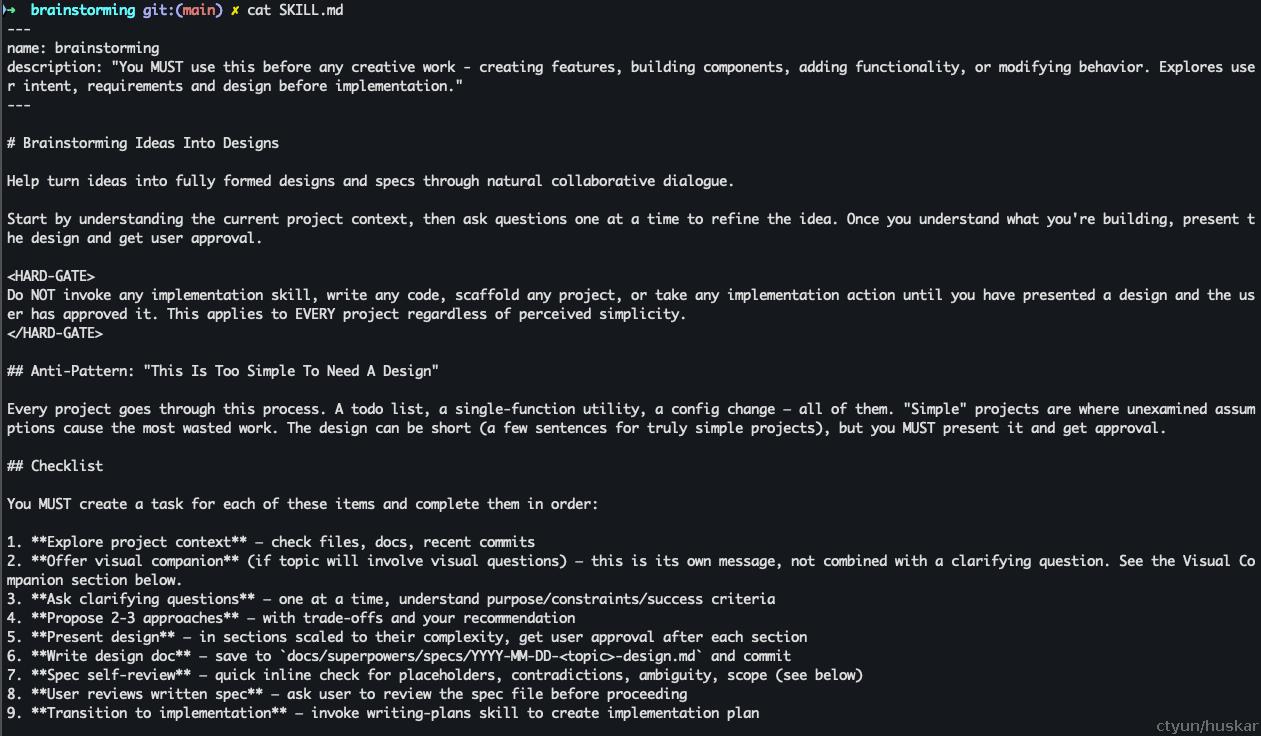
由于内容较多,我按章节进行了总结,大家可以对照查看
| 段落 | 说明 |
|---|---|
| 元数据 (Meta) | Skill 的元数据,用于 Agent 识别和加载。包含核心字段:name(技能名称)、description(技能描述,说明何时及为何使用此技能) |
| 硬性门禁 (HARD-GATE) | 最核心的约束规则:在展示设计方案并获得用户批准之前,禁止调用任何实施技能、编写代码、搭建项目或采取任何实施行动。适用于所有项目,无论其看似多么简单 |
| 反模式说明 | 驳斥"太简单不需要设计"的错误观念。指出即使简单的项目(待办列表、单功能工具、配置更改)也必须经过设计流程,否则未审查的假设会导致大量无用功 |
| 检查清单 | 定义完成该 Skill 必须按顺序执行的 9 个步骤:探索上下文 → 提供可视化伴侣 → 澄清问题 → 提出方案 → 展示设计 → 编写文档 → 规格自审 → 用户审阅 → 过渡到实施 |
| 流程图 (Process Flow) | 使用 DOT 语言描述的完整流程可视化,展示从探索上下文到调用 writing-plans 技能的所有分支路径和决策点 |
| 终态定义 | 明确 Skill 的终态是调用writing-plans技能。禁止调用其他实施技能(如 frontend-design、mcp-builder 等) |
| 理解想法 | 如何探索和拆解用户需求:先查看项目状态、评估范围、识别多子系统项目并帮助分解、逐个提问、优先使用选择题、只关注目的/约束/成功标准 |
| 探索方案 | 提出 2-3 种不同方案,包含权衡分析,以对话方式推荐并解释理由 |
| 展示设计 | 按复杂程度分节展示设计(架构、组件、数据流、错误处理、测试),每节后征求反馈,准备回溯澄清 |
| 隔离性与清晰度设计 | 将系统分解为小而独立的单元,每个单元有单一目的、清晰接口、可独立理解和测试。大文件通常表示职责过多 |
| 现有代码库工作 | 先探索现有结构,遵循现有模式。针对影响工作的问题进行针对性改进,不做无关重构 |
| 文档编写 | 将验证后的设计保存到docs/superpowers/specs/YYYY-MM-DD-<主题>-design.md,使用清晰简洁写作技能(如有),提交到 git |
| 规格自审 | 编写规格后检查四项:占位符扫描、内部一致性、范围检查、模糊性检查。内联修复后无需重新审阅 |
| 用户审阅门禁 | 要求用户审阅书面规格,等待回应。如要求更改则修改后重新运行审阅循环,只有用户批准后才继续 |
| 实施阶段 | 调用writing-plans技能创建详细实施计划,不调用任何其他技能 |
| 关键原则 | 六条核心原则:一次一个问题、首选选择题、无情遵循 YAGNI、探索备选方案、增量验证、保持灵活 |
| 可视化伴侣 | 基于浏览器的工具,用于展示线框图、图表、可视化选项。包括:提供方式(单独消息征得同意)、每个问题的决策标准(可视化用浏览器,文本用终端)、详细指南引用 |
注意,SKILL.md 元数据格式是固定的:
-------------------------
name: <技能名称>
description: "<技能描述>"
-------------------------
如何调用脚本或资源
brainstorming 有一个能力:在交互确认设计或方案是,Agent 可以将一些方案以表格或图形的方式,通过html 可视化的方式展示给用户,方便用户进行直观感受、review.
下面我们来分析一下,这个功能是如何运作的。
首先,SKILL.md中定义了该能力和触发的描述
在SKILL.md中,我们看到如下描述:
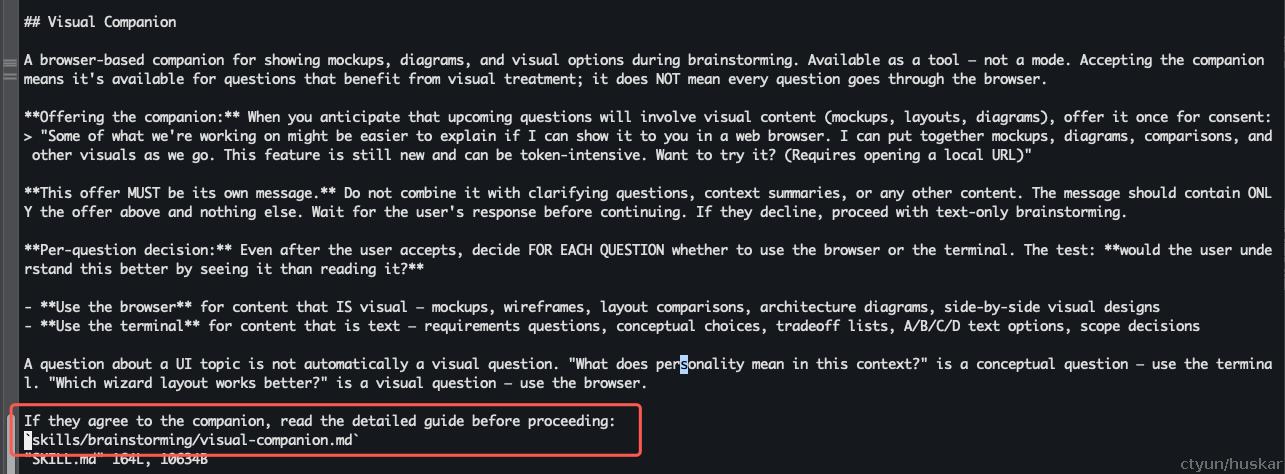
其大意是,浏览器可视化 是一个工具(辅助能力),而不是一种模式;需要询问用户(询问话术),并征得用户同意后,开启浏览器可视化。如果需要执行该操作,请参考 skills/brainstorming/visual-companion.md
visual-companion.md 触发脚本
进入skills/brainstorming/visual-companion.md 文件,可以看到该文件与SKILL.md 类似,也是针对场景和功能进行描述(引导AI如何执行具体的动作)。
在 How it Works 一节中,说明了如何触发脚本,实现可视化跟随
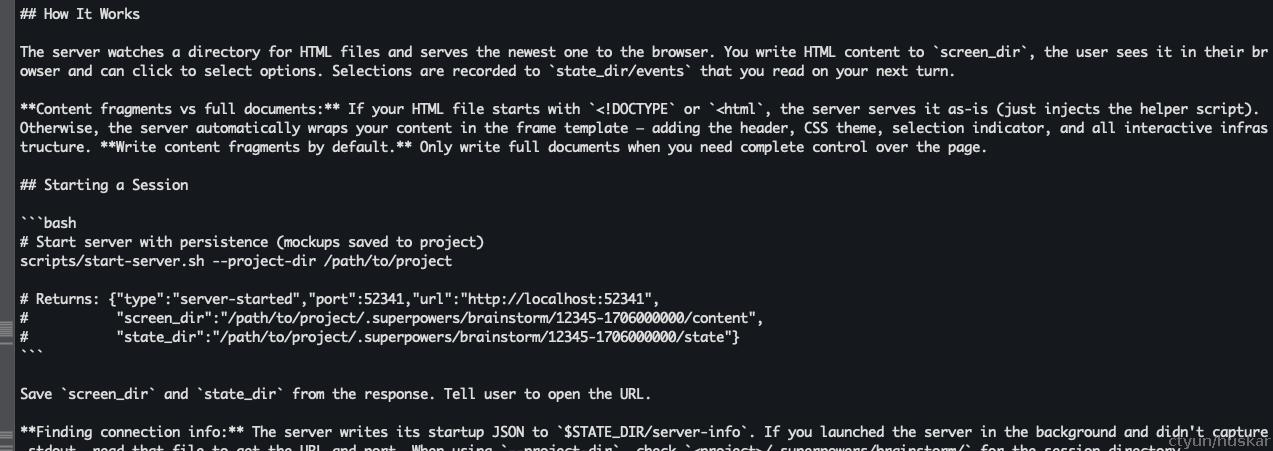
而脚本的功能是,启动一个服务端口,并绑定一个临时目录,AI在交互式过程中,会生成html文本,并保存到临时目录中,然后页面访问该端口,并展示该目录下的html文件。
上述是一个大体流程,细节我们就不再追溯了。
但有两个东西,可以提一嘴:
- 在Skill 中,调用脚本也是通过标注或说明的方式,不再是传统脚本间的调用(固定的,静态的)
- visual-companion.md 内容与SKILL.md 的内容本质是一样的;但是拆分为两个文件,是为了实现 渐进式加载, 避免每次加载SKILL.md 都将 visual-companion.md 加载到上下文中。其一,上下文空间寸土寸金,这里浪费了,其他有用的信息就会被挤占;其二,无用的内容在上下文中,还会形成干扰。
实战 —— 开发一个golang 代码审查的Skill
需求与背景
部门的golang编码规范中,核心包括两部分:格式或风格规范 和 代码质量规范。

其中格式或风格规范,可以借助 gofmt 命令进行校验,或一般基于静态代码检查的工具也能实现。但码质量规范,因为其具备较强的抽象性,或需要联系源代码上下文,甚至需要模拟运行过程才能识别,常规检查工具无法胜任。这部分review,目前还是依赖人工review。
需求:
实现一个golang代码审查的Skill,能够对golang项目的代码,按照 《Golang 编码规范.docx》 中编码规范要求, 对代码进行review,并给出反馈。其中,【强制】类规则代码必须满足,如果不符合需要重点标记,并给出修复建议;【推荐】类规则代码尽量满足,如果不符合,需要给出建议,但不强制; 【建议】类规则代码尽量满足,如果不符合,需要给出提示
限制:
- review 范围由用户指定(提交,分支,或文件), 如果不指定则默认view 当前工程中的所有golang文件
- 仅review,给出报告(含修复建议),但不能自动修改代码
实现
首先,将《Golang 编码规范.docx》整理为 golang-fmt.md,作为该skill 的资源文件。
然后,整理任务提示词:
实现一个golang代码审查的Skill,针对golang项目,按照
限制:
1. review 范围由用户指定(提交,分支,或文件), 如果不指定则默认view 当前工程中的所有golang文件
2. 仅review,给出报告(含修复建议),但不能自动修改代码
最后,采用 /writing-skills Skill 来创建该skill(复制上面的提示词):

完成后,在工程的.opencode/skills 目录已生成该skill 文件。
验证
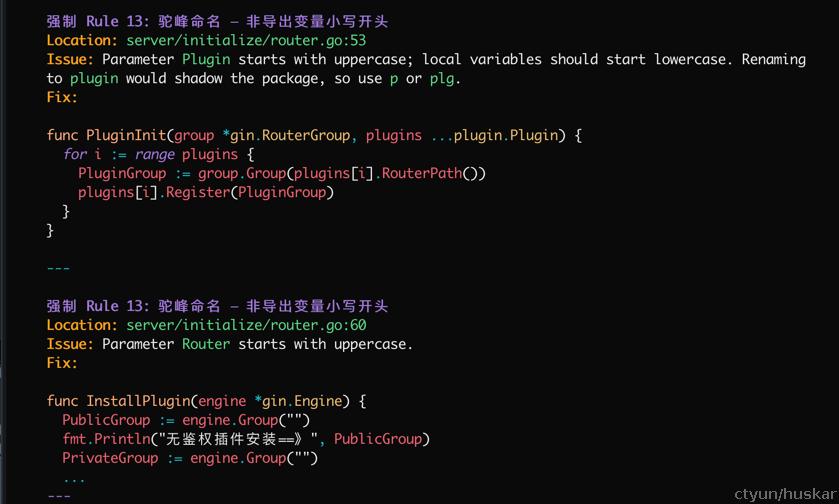
将该skill copy到一个golang 工程中,并启动opencode,运行该skill对特定的commit 进行review

效果:
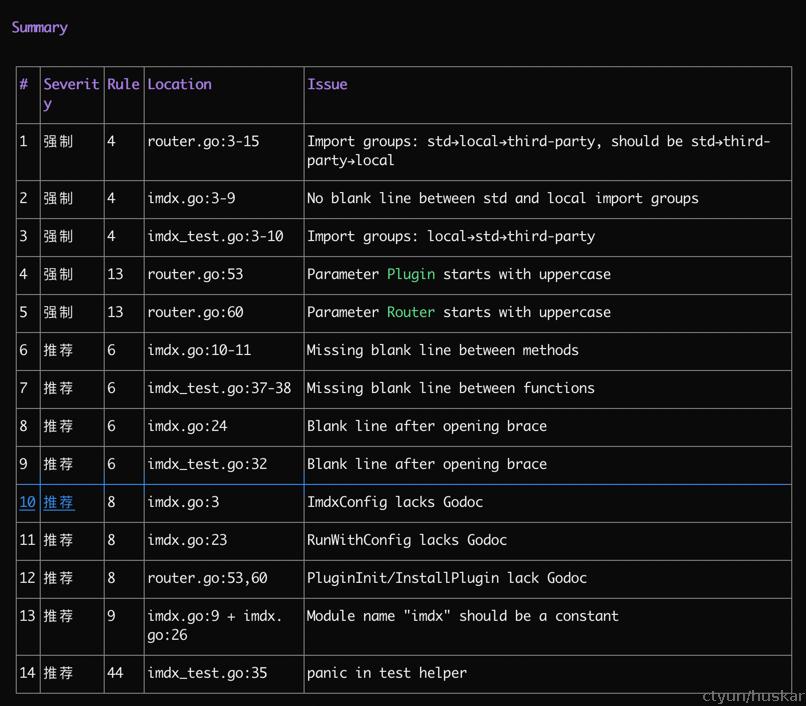
写在最后
受篇幅限制,本篇课程主要以介绍Skill的基本内容和概念为主,并简单演示使用 writing-skills 技能(类似的还有skill-creator) 创建一个Skill。
实际上,好的Skill艺术成分是很高的。除了需要考虑:
- Skill的功能分布,如何组织流程?
- 如何触发,有哪些门禁?
- 检查清单如何定义?
- 需要哪些工具或脚本?
- 说明 Skill 何时结束、下一步应该做什么?
还需要考虑,触发是否稳定、上下文是否精简、Token效率等等...
比如,有些内容可以有工具获取,也可以通过AI推导。这里是Token效率的关键,但有存在灵活性限制问题。
比如,在review skill中,review的内容可以通过git 工具以patch或diff的方式导出,也可以模糊化,由AI自己阅读文件或自行调用git 命令进行推导;如果我们通过脚本的方式提供git命令处理,那么token效率会很高;反之,如果由AI自己处理,那么获得较高的灵活性和适配性,但Token消耗会激增。
如何做好平衡是一个挑战...
这里仅举这个例子,事实上还有很多技巧和很多值得推敲的点...
本篇就先不展开了,后面争取再开一篇,可以展开聊聊。
