


Skywalking是一个优秀的开源性能监控组件,也被称为分布式追踪系统。其中最重要,最基本的功能即为trace(追踪)能力。它将系统中发生的各类调用串联起来,并在界面上以调用顺序、时长、类型等维度展示,以便发生故障的时候,能够快速定位和解决问题。
但是,调用链只记录调用过程中各模块间发生关键交互的行为,通常并不会如arthas之类的进程分析工具一样详细到调用堆栈级别,因此除了调用链中记录的某一段的长短以外,对于调用链之间的空白部分的理解、认识与分析,也是利用调用链解决分布式系统故障问题的关键。
本文以一次线上问题记录的调用链为例,介绍一些调用链中空白部分可能存在的情况。
以路径为/firewall/desktop/{vmUuid}的请求为例
一、常规情况
访问时长为14ms左右,长紫色线为网关接收到请求,转发至后端并最终相应的总时长。
长浅蓝线为后端某服务接收到请求并进行处理的时长
短浅蓝线为两次数据库调用时长。
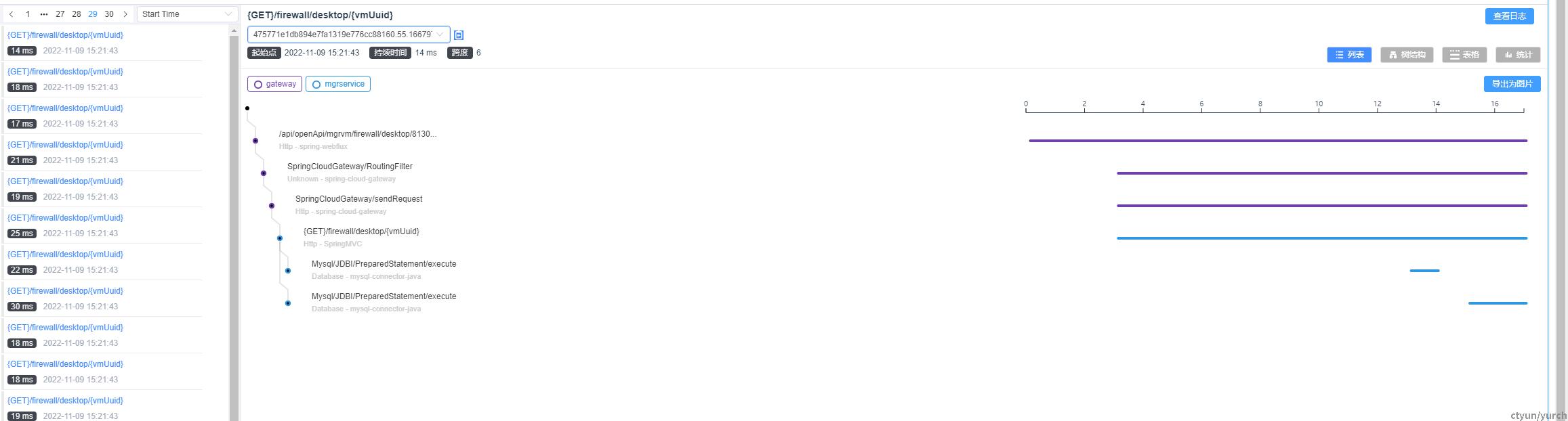
因为总时长较短,此时空白部分可以暂时理解为业务处理时长。
二、慢响应情况
此次响应总时长达到700ms,可以看到两次数据库请求耗时并未增加,主要增加的耗时,在于网关发出请求到后端服务接收到请求之间增加了大片空白。 此外,后端服务运行第一个SQL语句之前的处理时长也大幅度增加。

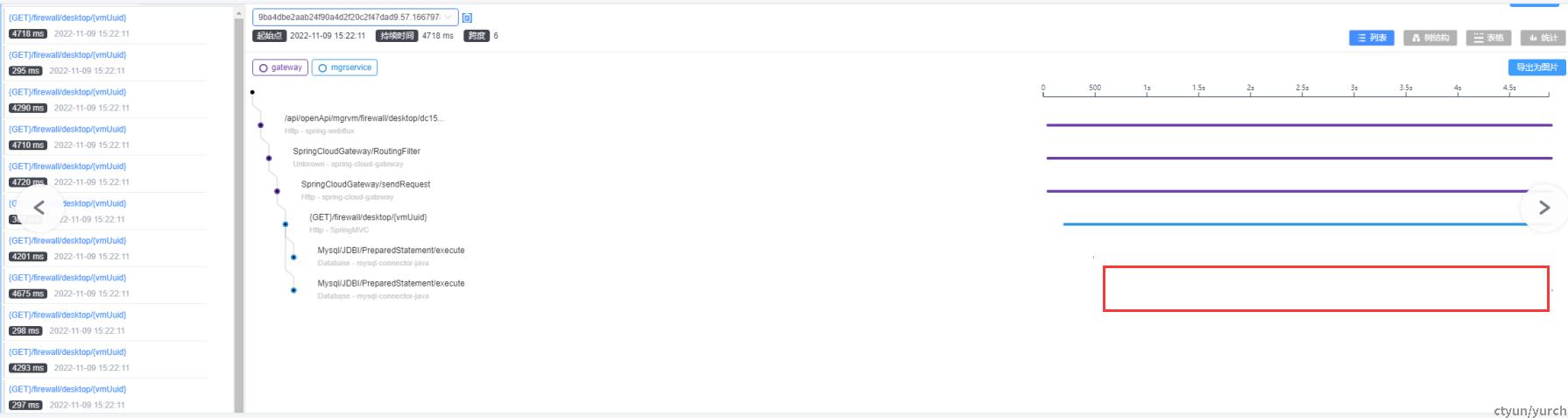
三、超慢响应情况
此次总响应时长达到4.7秒,已经是正常情况的200多倍,而情况与上文中的慢响应情况又有所不同,主要耗时发生在两条耗时极短的SQL语句之间。
四、极慢响应情况
此次总响应时间超过12秒,且能观测到的后端服务3段处理之间均出现了大量耗时空白。

在这种时候调用链其实无法非常直观的展现到底是什么原因导致了慢响应的出现,因为真正耗时的部分是空白,并没有记录下来。并且不同的慢请求中,耗时的部分并不一致。
首先,我们排除一部分很直接,但是可能性较小的原因。
1:业务逻辑处理超时:
对于空白部分的理解,最直接的就是在处理业务逻辑。 对于同一个接口,在不同的请求参数下确实可能出现处理耗时差异极大的情况。但对于一个已经上线且相对稳定接口,如果突然出现平均耗时大幅上升的情况,通常并不会是因为业务的突然变更,尤其是在此例中,SQL的处理时间并未明显增长,说明数据的量级未发生大的变化。
当然,在日常排查中,如果只有这一个接口出现异常,而其他接口全部正常,确实有可能是业务逻辑问题,要结合日志与代码进行检查, 这种情况比较容易发现与排除。
2:垃圾回收导致处理停滞
full GC带来的stop of the world, 确实可能导致程序对请求的处理停滞,尤其在程序负载突然上升并带来大量full GC的情况下, 会导致请求响应速度急剧下降。
但是full GC带来的停滞,通常不会到达秒级甚至十秒级这个级别,尤其在微服务系统中,分配内存普遍偏小的情况下。如果一旦出现,通常是是由于服务出现了内存泄漏或内存不足之类的严重问题,已经濒临崩溃的边缘。
3:网络问题
对于此例中,两个服务之间出现空白的情况, 非常直观的想法是由于网络问题导致,这是一种合理的猜测,可以结合系统中是否成批量出现连接超时的异常进行定位。但在此例中,后端服务接收到请求后对请求的处理依然缓慢,所以网络并不是决定性因素。
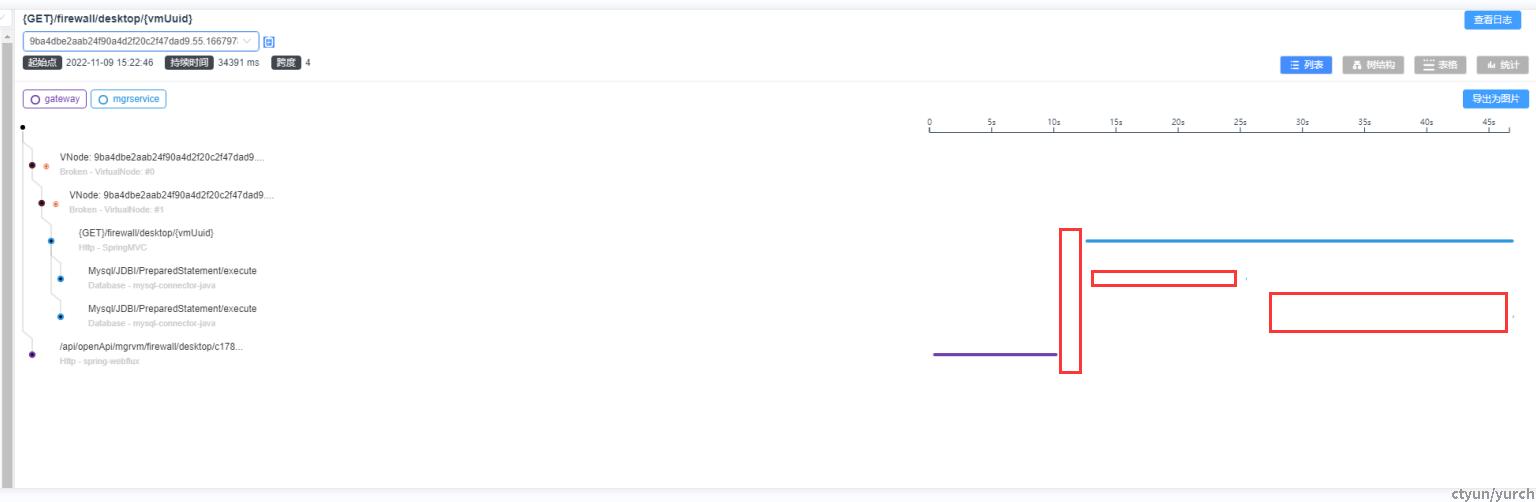
五、超时情况
此次调用总时长实际超过了45秒,已经远远超过了网关设定的超时时间。
从途中可以看到,网关在后端服务响应之前,就已经进行了 响应,这是触发了网关本身的超时机制。
六、分析
在超时情况中,有一个关键点是,代表网关进行超时响应的紫线与后端服务接收的请求的蓝线之间,甚至还有一片达到秒级的间隔。这大大降低了网络原因造成超时的可能性,如果是网络原因导致的连接不通畅,更可能出现的现象是网关直接与后端连接超时,后端服务根本无法收到请求, 而不是在超过10秒后还是处理请求。
经过对Skywalking中 SpringBoot agent源码的研究,我们可以认识到,skywalking对于这段调用链的记录,并非开始于后端服务收到请求时,而是在后端服务开始处理这个请求时。 实际上,因为Skywalking的agent基于javaagent技术实现,其原理是对于各类框架的关键处理方法进行增强,所以一般都是在框架开始处理请求之后,在此之前,框架通常已经完成了读socket中读取流以及反序列化等操作。
因此,在此例中,紫线与蓝线之间的空白中,其实有一个较容易被忽视的耗时操作,也是就等待Tomcat服务器为请求分配处理线程的时间。在Tomcat支持NIO后,服务器默认有200个工作线程,在所有线程均繁忙时,新请求会进入等待队列,对于这些等待队列中的请求,直到工作线程开始处理它时,都不会在调用链中展现出来。
而两条耗时并不长的SQL执行前,其实也有类似的操作,也就是等待数据库连接池分配连接的时间。在数据库中的所有连接都繁忙时,新来的SQL请求会一直等待空闲的连接,直到配置的60s等待超时为止。SQL等待数据库连接的超时会对请求等待工作线程的超时形成恶劣的影响,因为每个请求的处理时长变长,会导致等待中的线程的等待+处理时间变得更长,在此例中,最长甚至达到了数百秒。
按照这个思路,我们找到了在问题出现前连续调用的几个超慢SQL请求,问题的出现的逻辑也形成链条:
慢SQL请求->数据库连接池的连接长期处于繁忙状态->大量正常SQL无法获取到连接-> 请求无法分配工作线程->处理时长不断上升
