


一、什么原因导致的pod被驱逐?
在Kubernetes集群中,pod正常运行所依赖的最重要的资源是CPU、内存和磁盘。然后,可以将这些资源分为可压缩资源(CPU)和不可压缩资源(内存和磁盘)。可压缩资源不会导致pod被驱逐,因为当pod的CPU使用率很高时,系统可以通过重新分配权重来限制pod的CPU使用率。但对于不可压缩资源,如果没有足够的资源,则不可能继续请求资源(内存耗尽意味着资源耗尽)。所以Kubernetes会从节点上驱逐一定数量的pod,以确保节点上有足够的资源。
当不可压缩资源耗尽时,Kubernetes使用kubelet来驱逐pod,每个计算节点的kubelet通过捕获cAdvisor指标来监视节点的资源使用情况。如果在部署应用程序时设置了正确的参数并了解所有可能性,就可以更好地控制集群。
二、什么是pod驱逐
pod驱逐是Kubernetes在某些场景下的特有功能,如节点NotReady、节点资源不足、将pod驱逐到其他节点等。Kubernetes中有两种驱逐机制:
- kube-controller-manager:周期性检查所有节点的状态,当节点处于NotReady状态超过一定时间后,清除节点上的所有pod。
- kubelet:定期检查节点的资源,当资源不足时,根据优先级将部分pod驱逐。
三、kube-controller-manager 触发pod驱逐
Kube-controller-manager定期检查节点状态,当节点状态为NotReady且超过podEvictionTimeout时间时,该节点上的所有pod将被驱逐到其他节点,具体的驱逐速度还受驱逐速度参数、集群大小等的影响。
以下启动参数可以来控制pod驱逐:
- pod-eviction-timeout: 当NotReady状态节点超过设置的超时时间后,pod将执行驱逐,默认是5分钟;
- node-eviction-rate: 节点驱逐pod速率;
- unhealth-zone-threshold: 集群中节点宕机的数量超过该阀值,集群处于不健康状态。
四、kubelet 触发pod驱逐
Kubelet定期检查节点的内存、磁盘、inode 和pid等资源的使用率。根据 kubelet 的配置当使用率达到一定阈值后会先回收可以回收的资源,若回收后资源使用率依然超过阈值则进行pod驱逐操作。
|
Eviction Signal |
Description |
|
memory.available |
memory.available := node.status.capacity[memory] - node.stats.memory.workingSet |
|
nodefs.available |
nodefs.available := node.stats.fs.available |
|
nodefs.inodesFree |
nodefs.inodesFree := node.stats.fs.inodesFree |
|
imagefs.available |
imagefs.available := node.stats.runtime.imagefs.available |
|
imagefs.inodesFree |
imagefs.inodesFree := node.stats.runtime.imagefs.inodesFree |
|
pid.available |
pid.available := node.stats.rlimit.maxpid - node.stats.rlimit.curproc |
- available:当前节点可用内存,计算方式为 cgroup memory 子系统中 memory.usage_in_bytes 中的值减去 memory.stat 中 total_inactive_file 的值;
- available:nodefs 包含 kubelet 配置中 --root-dir 指定的文件分区和 /var/lib/kubelet/ 所在的分区磁盘使用率;
- inodesFree:nodefs.available 分区的 inode 使用率;
- available:镜像所在分区磁盘使用率;
- inodesFree:镜像所在分区磁盘 inode 使用率;
- available:/proc/sys/kernel/pid_max 中的值为系统最大可用 pid 数;
Kubelet 可以通过参数 --eviction-hard来配置以上几个参数的阈值,该参数默认值imagefs.available<15%,memory.available<100Mi,nodefs.available<10%,nodefs.inodesFree<5%,当达到阈值时会驱逐节点上的pod。
当pod驱逐发生时,kubelet支持两种驱逐模式:
- soft: 过一段时间后再驱逐pod;
- hard:直接驱逐pod。
五、pod驱逐故障处理
从下面的截图可以很清晰的看到pod为什么被驱逐了,驱逐原因:The node had condition: [DiskPressure] 或 The node was low on resource: ephemeral-storage。节点上没有足够的磁盘空间和本地存储,导致kubelet触发pod驱逐。

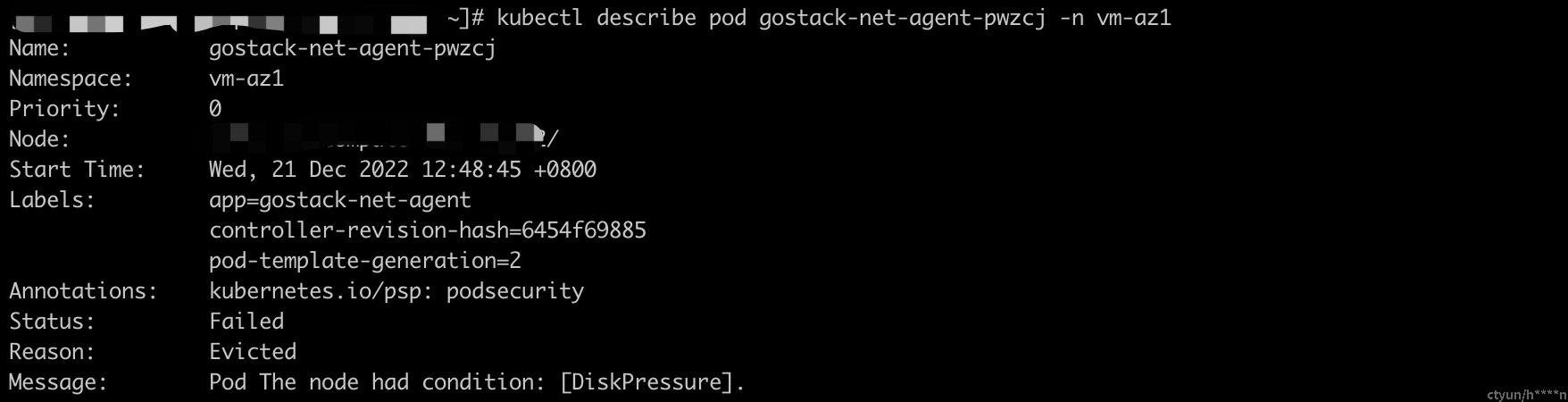
针对此类场景的一些故障排除技巧:
- 开启automatic scaling
可以向kubernetes集群中添加一个worker,也可以部署cluster-autoscaler来根据设置的条件自动缩放。当然也可以只增加工作节点的本地存储空间,这涉及到调整VM的大小,并将导致工作节点暂时不可用。
- 保证关键应用
明确指定pod资源的请求和限制。当kubelet触发pod驱逐时,这些关键应用的pod不会受到影响。上述措施在一定程度上保证了一些关键应用程序的可用性。如果在节点有故障,但还没有驱逐pod时,则需要再执行几个步骤来检查故障。执行kubectl get pods命令后,可以看到很多pod都处于驱逐状态;kukectl describe pod 查看故障信息。
- 检查pod的容忍度(tolerances)配置
tolerationSeconds配置描述pod连接失败或无响应的时间。pod的容忍度配置如下:
tolerations:
- key: "node.kubernetes.io/unreachable"
operator: "Exists"
effect: "NoExecute"
tolerationSeconds: 6000
- 确认容器可分配的资源
根据该节点的资源使用情况pod会被节点驱逐,被驱逐的pod是根据分配给它的节点资源调度的,不同的规则决定了最终的驱逐和调度结果,被驱逐的pod可能会被重新调度到原始节点。因此,需要合理分配每个pod所占用的资源。
- 检查pod是否经常故障
如果一个pod被驱逐并调度到一个新节点后,该节点中的pod也被驱逐,则该pod将再次被驱逐,pod因此可以被驱逐多次。如果由kube-controller-manager触发驱逐,则处于终止状态的pod将被保留,节点恢复后,pod会自动销毁。如果节点已被删除或因其他原因无法恢复,可以强制销毁pod。如果kubelet触发了驱逐,pod的状态将会停留在驱逐状态,仅用于后续故障定位,可直接删除。
要删除被驱逐的pod,可以运行以下命令:
kubectl get pods | grep Evicted | awk ‘{print $1}’ | xargs kubectl delete pod
六、结论
通过更好地理解如何驱逐pod以及何时驱逐pod,可以更简单地维护kubernetes集群。给部署的组件服务指定正确的参数,掌握所有可用的选项,了解到服务的工作负载,可以更有效的管理Kubernetes资源。
