


在高并发场景下,MySql等传统关系型数据库成为瓶颈,无法满足系统性能要求。如果过多请求直击数据库,可能导致数据库响应变慢甚至瘫痪,产生严重后果。
缓存技术的出现可以很好解决这类问题。将热门数据从关系型数据库加载到内存,后续数据访问优先从内存中读取,大大减轻数据库压力,同时利用内存优势极大提升查询性能。
缓存分为两类:本地缓存和远端缓存。常用本地缓存工具有ConcurrentHashMap、Guava Cache、Caffeine等。常用远端缓存工具有redis和memcache等。本地缓存和远端缓存各有优势。
本文主要介绍本地缓存的几种实现方式,并做比较分析。
1 本地缓存方式
1.1 ConcurrentHashMap
利用ConcurrentHashMap的线程安全特性,实现数据缓存读写,但是功能非常简单,不支持数据淘汰和过期机制,需要做定制开发。适用于数据量少且固定的场景。
1.2 Guava Cache
1.2.1 介绍
Guava Cache底层存储实现原理类似于历史版本的ConcurrentHashMap(详见源码LocalCache.class),使用segment分段锁,减小锁粒度,增加性能同时保证数据线程安全,具有比较多的功能:
- 支持数据过期功能。可以设置数据写入后过期时间和数据访问后过期时间,在发生数据读写操作时,对已过期缓存数据做处理;
- LRU算法支持数据淘汰功能。可以设置缓存初始容量和最大容量。设置初始容量可以一定程度避免扩容产生的损耗。设置最大容量用于实现数据淘汰,防止内存占用过多,在数据写入时检查已缓存数据量是否超过最大容量,如果超过最大容量,则对数据进行淘汰清理;
- 支持设置并发数,既segment数组大小;
- 具备缓存数据(LoadingCache)load和(LoadingCache和Cache)callback功能,当从缓存中获取不到数据时,按照callback>load的优先级顺序,获取数据并保存到缓存,为了防止缓存穿透,多线程读取相同key值,load和callback都是阻塞串行;
- LoadingCache支持数据刷新功能,当数据写入后超过设定时间,在发生数据读取动作时,会执行load函数对需要刷新的缓存数据做刷新操作;
- 一些不是很常用的功能,例如:依赖GC的弱引用和软引用设置、缓存信息统计等。
1.2.2 demo
public class GuavaCacheTest {
private static final Logger LOG = LoggerFactory.getLogger(GuavaCacheTest.class);
@Test
public void GuavaLoadingCache () throws InterruptedException, ExecutionException {
LoadingCache<String, String> loadingCache = CacheBuilder.newBuilder()
.concurrencyLevel(5)
.expireAfterWrite(10, TimeUnit.SECONDS)
.refreshAfterWrite(3, TimeUnit.SECONDS)
.initialCapacity(3)
.maximumSize(3)
.recordStats().removalListener(entry ->
LOG.info("缓存数据移除,key:[{}],移除原因:[{}]", entry.getKey(), entry.getCause().toString())
).build(new CacheLoader<String, String>() {
@Override
public String load(String key) throws Exception {
Thread.sleep(10000);
return key + "_load";
}
});
LOG.info("开始插入数据,key:[{}]", "111");
loadingCache.put("111", "111");
LOG.info("开始插入数据,key:[{}]", "222");
loadingCache.put("222", "222");
LOG.info("开始插入数据,key:[{}]", "333");
loadingCache.put("333", "333");
LOG.info("开始插入数据,key:[{}]", "444");
loadingCache.put("444", "444");
LOG.info("缓存size :[{}]", loadingCache.size());
Thread.sleep(5000);
LOG.info("开始插入数据,key:[{}]", "555");
loadingCache.put("555", "555");
LOG.info("主线程开始获取缓存数据444");
String str444 = loadingCache.get("444");
LOG.info("主线程获取缓存数据444,value:[{}]", str444);
Thread.sleep(10000);
//模拟线程并发
new Thread(() -> {
try {
LOG.info("时间:[{}],子线程开始获取缓存数据,key:[{}]", LocalDateTime.now(), "111");
String str111 = loadingCache.get("111", () -> {
LOG.info("时间:[{}], 子线程开始callable获取数据,key:[{}]", LocalDateTime.now(), "111");
Thread.sleep(10000);
return "111" + "_子线程callable";
});
LOG.info("时间:[{}], 子线程获取缓存数据111,value:[{}]", LocalDateTime.now(), str111);
} catch (ExecutionException e) {
LOG.error("获取缓存数据异常", e);
}
}).start();
LOG.info("时间:[{}],主线程开始获取缓存数据,key:[{}]", LocalDateTime.now(), "111");
String str111 = loadingCache.get("111", () -> {
LOG.info("时间:[{}], 主线程开始callable获取数据,key:[{}]", LocalDateTime.now(), "111");
Thread.sleep(10000);
return "111" + "_主线程callable";
});
LOG.info("时间:[{}], 主线程获取缓存数据111,value:[{}]", LocalDateTime.now(), str111);
String str222 = loadingCache.get("222");
LOG.info("主线程获取缓存数据222,value:[{}]", str222);
LOG.info("缓存size :[{}]", loadingCache.size());
}
}
日志打印结果:
17:52:13.545 - 开始插入数据,key:[111]
17:52:13.576 - 开始插入数据,key:[222]
17:52:13.576 - 开始插入数据,key:[333]
17:52:13.576 - 开始插入数据,key:[444]
17:52:13.591 - 缓存数据移除,key:[111],移除原因:[SIZE]
17:52:13.592 - 缓存size :[3]
17:52:18.602 - 开始插入数据,key:[555]
17:52:18.603 - 缓存数据移除,key:[222],移除原因:[SIZE]
17:52:18.603 - 主线程开始获取缓存数据444
17:52:28.711 - 缓存数据移除,key:[333],移除原因:[EXPIRED]
17:52:28.711 - 缓存数据移除,key:[444],移除原因:[EXPIRED]
17:52:28.711 - 缓存数据移除,key:[555],移除原因:[EXPIRED]
17:52:28.711 - 主线程获取缓存数据444,value:[444_load]
17:52:38.739 - 时间:[2022-12-27T17:52:38.738],主线程开始获取缓存数据,key:[111]
17:52:38.739 [Thread-1] INFO - 时间:[2022-12-27T17:52:38.738],子线程开始获取缓存数据,key:[111]
17:52:38.740 - 缓存数据移除,key:[444],移除原因:[EXPIRED]
17:52:38.740 - 时间:[2022-12-27T17:52:38.740], 主线程开始callable获取数据,key:[111]
17:52:48.754 [Thread-1] INFO - 时间:[2022-12-27T17:52:48.754], 子线程获取缓存数据111,value:[111_主线程callable]
17:52:48.758 - 时间:[2022-12-27T17:52:48.758], 主线程获取缓存数据111,value:[111_主线程callable]
17:52:58.763 - 缓存数据移除,key:[111],移除原因:[EXPIRED]
17:52:58.763 - 主线程获取缓存数据222,value:[222_load]
17:52:58.763 - 缓存size :[1]
demo模拟了数据到期、淘汰、刷新、loader多线程并发拉取、缓存失效监听等功能,通过分析日志打印结果,可以了解上述功能的触发时机和实现逻辑。
1.3 Caffeine
1.3.1 介绍
Caffeine作为本地缓存天花板,使用方法和Guava Cache相似,但是读写性能是Guava Cache数倍,缓存命中率有一定提升。其主要优势在于独特的数据淘汰算法W-TinyLFU和高性能的异步读写能力。下图来源官方数据(https://github.com/ben-manes/caffeine/wiki/Benchmarks)
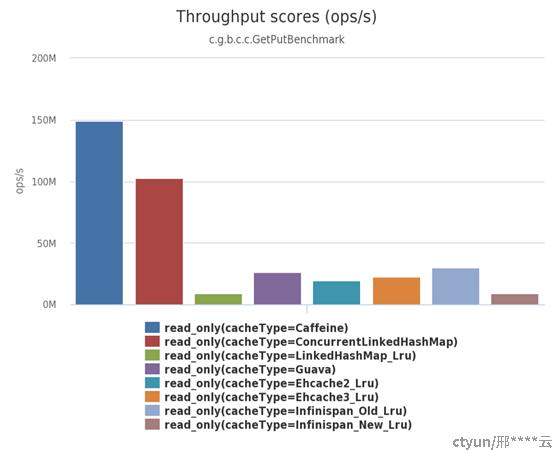
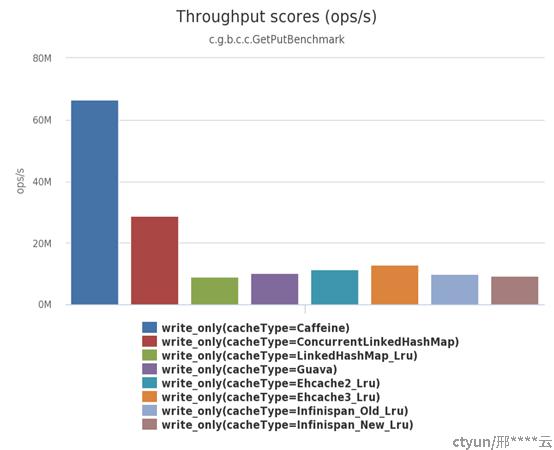
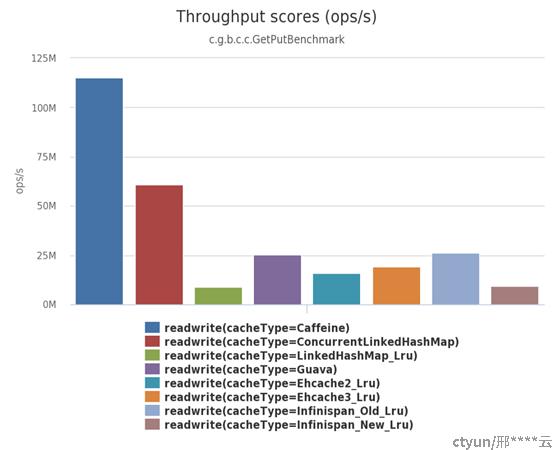
1.3.1.1 W-TinyLFU算法
W-TinyLFU算法是LFU的改良升级款,主要概念有Count-Min Sketch、Window Cache和Main Cache。
1.3.1.1.1 Count-Min Sketch
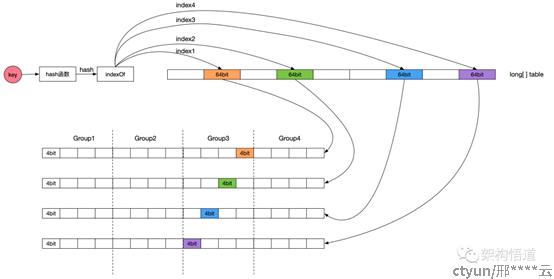
采用Count-Min Sketch频率统计算法,解决传统LFU算法单独记录每条数据的调用频率,导致内存占用大的问题。Count-Min Sketch算法和布隆过滤器实现逻辑相似,但是记录的是数据的访问频率而非boolean值,W-TinyLFU访问频率计算原理如图所示(来源网图)。具体计算逻辑如下:
定义long类型数组table,数组中每个long元素是64bit,将64bit拆分为4个group和16个等分,即每个group 4等分,每等分4bit,这样每等分可以记录最大数值15,也是W-TinyLFU记录单条数据的最大频率。计算步骤如下(详见源码FrequencySketch.class):
- 对key值做hash计算,得到hash值hashA;
- 将hashA分别和四个固定的种子值做计算,得到4个index,以这四个index值为下标获取table数组中的4个long值,long1,long2,long,long4;
- 计算(hashA & 3) << 2,计算结果可能是0,4,8,12。确定group值,groupA;
- 获取long1数据的第(groupA+0)等分值fre1,long2数据的第(groupA+1)等分值fre2, long3数据的第(groupA+2)等分值fre3, 获取long4数据的第(groupA+3)等分值fre4;
- 获取fre1,fre2,fre3,fre4中的最小值,便是该条key数据的访问频率。
- 如果所有记录的总频率记录达到一定值,会将所有记录的访问频率值/2,以便持续比对,这也有效避免冷门数据突发高访问导致无法被淘汰问题发生。
1.3.1.1.2 Window Cache和Main Cache
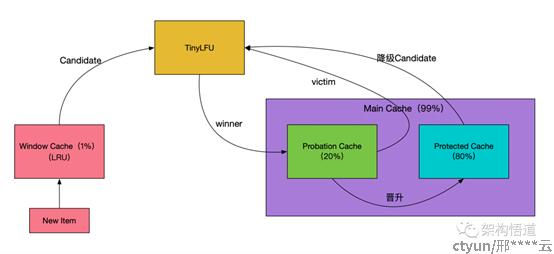
Caffeine缓存区域设计如图(来源网图),包括Window Cache和Main Cache,Window Cache使用标准的LRU算法,Main Cache使用分段LRU算法。这种设计极大地提升了缓存命中率,并且解决了LFU算法在面对突发性流量时表现差的问题,因为新的记录还没来得及建立足够的频率就会被剔除出去,导致缓存命中率下降。
具体数据流转流程是这样的:最新数据写入缓存,会被首先记录到Window Cache区域,如果Window Cache区域已满,会按照LRU算法取出Window Cache中最旧的一条缓存记录,并将其移入Probation Cache,如果Probation Cache区域已满,则会获取Probation Cache区域最旧一条记录和该条记录做PK(源码详见BoundedLocalCache类的admit方法,主要是访问频率的PK),PK失败一方被淘汰,获胜一方记录到Probation Cache区域。Probation Cache区域数据达到一定访问频率,会被移入Protected Cache区域,如果Protected Cache区域已满,则会将Protected Cache区域最旧数据降级到Probation Cache区域,如果Probation Cache区域已满,又会进行上述PK操作。
1.3.1.2 高性能的异步读写
缓存数据读写时候,需要更新缓存状态。Guava Cache将缓存状态更新和数据读写放在一起执行,导致性能受影响。而Caffeine 借鉴了数据库系统的 WAL(Write-Ahead Logging)思想,执行读写操作时,先把操作信息记录在缓冲区,然后异步、批量地更新缓存状态。
1.3.2 demo
Caffeine使用方法和Guava Cache很相似,这里不再重复编写,有一点高级的用法是expireAfter(自定义淘汰策略)配置项,可以实现对不同的key设置不同的过期时间,这样可以一定程度预防缓存雪崩。expireAfter使用时间轮算法实现。
2 项目实践
目前项目中主要应用在固定、数据量小且访问量比较大的数据,用来提升性能,比如产品信息,运营商信息,承载平台信息,区域信息等,这些数据可能很久变化一次,每次变化接受一定程度延迟刷新。
首先定义抽象服务,用于缓存基本实现,预留loadByKey抽象方法,由继承服务具体实现。getByKey方法用于获取key对应的value值。
/**
*
* 缓存服务抽象类
*
* @author xingxy
* @date 2022/12/27 10:29
*/
public abstract class AbstractCaffeineCacheService<K, V> {
private final LoadingCache<K, V> dataCache;
public AbstractCaffeineCacheService(int reloadSeconds) {
this.dataCache = Caffeine.newBuilder()
.expireAfterWrite(Duration.ofSeconds(reloadSeconds))
.build(this::loadByKey);
}
/**
* 根据key从数据库load值
* @param key key
* @return value
*/
protected abstract V loadByKey(K key);
/**
* 根据key查询
* @param key key
* @return value
*/
public V getByKey(K key) {
return key == null ? null : dataCache.get(key);
}
}继承服务实现,定义缓存的key和value数据类型,缓存过期时间,具体的缓存数据load方法。实现业务数据获取逻辑和缓存逻辑分离。
/**
*
* 产品信息缓存服务类
*
* @author xingxy
* @date 2022/12/27 10:29
*/
@Service
public class ProductLocalCacheService extends AbstractCaffeineCacheService<String, Product> {
@Autowired
private ProductMapper productMapper;
public ProductLocalCacheService() {
super(10);
}
@Override
protected Product loadByKey(String productCode) {
if (StringUtils.isBlank(productCode)) {
return null;
}
ProductExample productExample = new ProductExample();
productExample.createCriteria().andProductCodeEqualTo(productCode);
List<Product> productList = productMapper.selectByExample(productExample);
return productList.stream().findFirst().orElse(null);
}
}
3 总结
本文对ConcurrentHashMap、Guava Cache、Caffeine三种本地缓存实现方法做了分析比较,Caffeine依靠W-TinyLFU算法和高性能异步读写等能力,拥有高性能、高命中率、低内存占用等优势,是实现本地缓存较好的选择。
