


此次优化的目标主要是减少网页渲染的首屏时延,也就是从用户点击到页面完全加载的耗时。
加载一个页面主要分为几个步骤(以输入URL加载网页的方式为例):
1、首先,在浏览器地址栏中输入url
2、初始化webview client
3、网页缓存查询(浏览器缓存-系统缓存-路由器缓存),未命中则发起网页加载。
4、DNS解析(也分为浏览器缓存->java缓存->native缓存)。
5、发起TCP/HTTP/TLS握手。
6、请求基本HTML+CSS内容,加载js脚本。
7、生成Dom树,解析css样式,js交互,js动态请求网页内容。
8、渲染引擎工作,blink引擎+v8引擎
作为平台侧,可以优化的是webview和网络请求实现。
这里首先优化平台侧DNS的逻辑,以提高网络请求的稳定性(防劫持/崩溃),提高网络体验下限。
那么要提高dns效率,有几个方面可以进行:
1、增加/延长dns缓存
提升:增加缓存命中率,减少某些重复的dns查询
风险:dns映射失效时缓存命中,会无法联通
2、超时优化(已实现)
提升:在有nameserver失效,但未全部失效的情况下,降低整体dns时延
风险:弱网场景可能出现解析失败
3、httpDns
提升:防劫持,稳定快速
风险:成本高,需自行搭建
4、串行改并行(已实现)
提升:类似超时优化,搭配多个name server,可实现min(ns1, ns2, ...)延迟
风险:逻辑改动较大
围绕串行改并行讲下:
首先通过流程图再回顾下当前的dns主要流程
可以看出,从APP进程(java层->native层->dnsproxyd写命令)到netd进程(监听命令→执行res_nsend→send_dg),
整个流程对于单个name server来说,都是串行逻辑,虽然经历一次跨进程,但是对于java层来说,都是单线程阻塞的逻辑。
如上述,并行的逻辑粒度要细化到每个name server,就需要看哪里逻辑牵涉到了对应iface的name server数组。
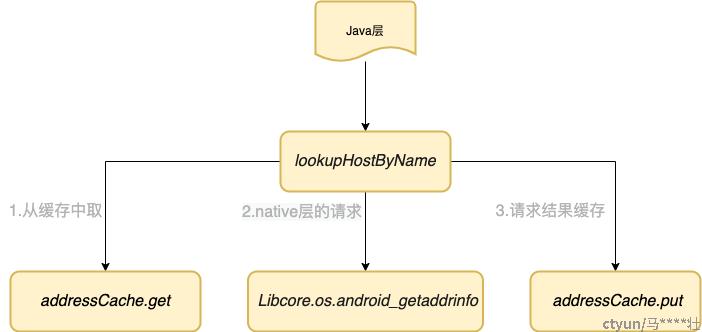
java层流程图
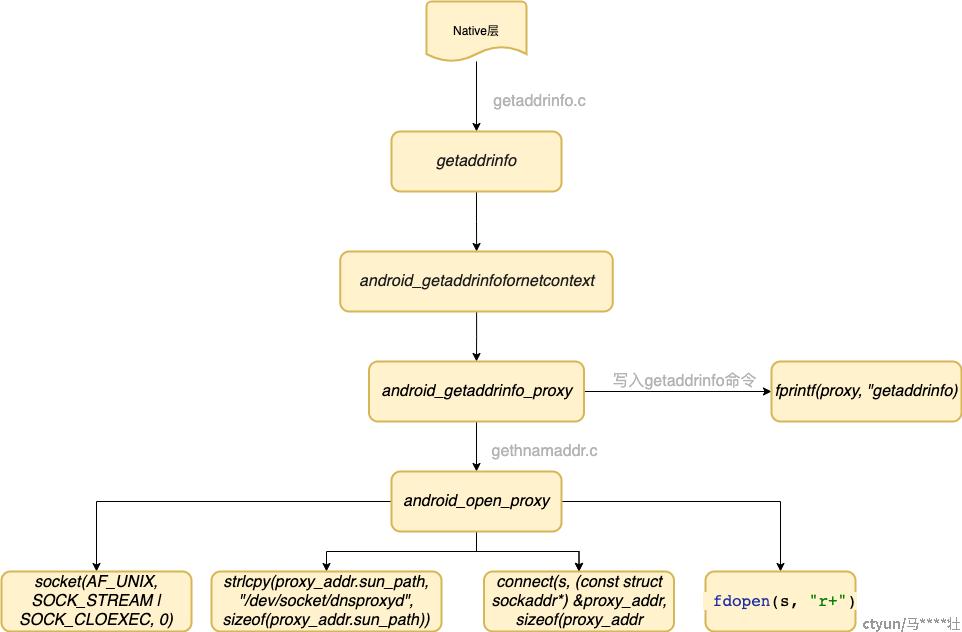
native层流程图
netd流程图
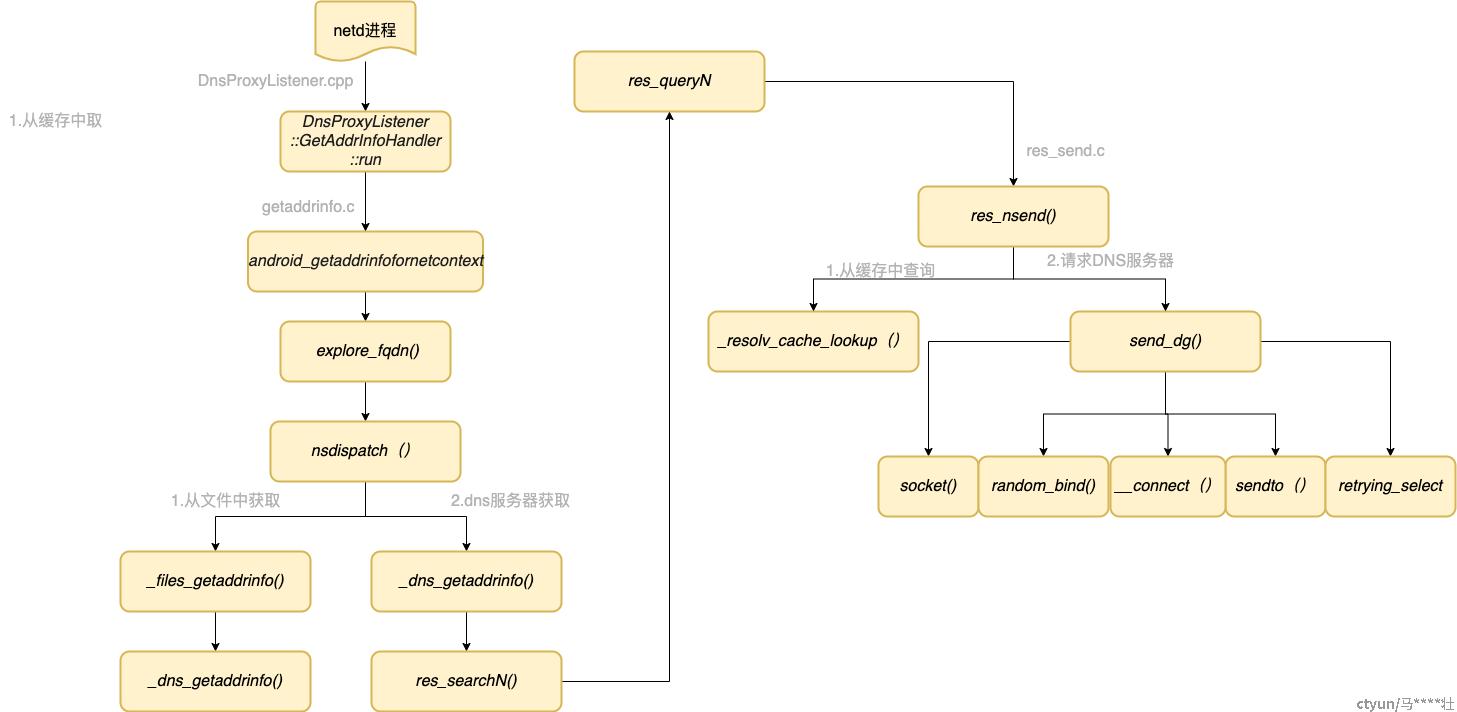
纵观流程对应的函数,上层一直都不关心name server,直到libc中res_state的初始化才出现对当前netid对应nameserver的查询。
也就是res_init.c中,存放在nsaddr_list[MAXNS]中
if (MATCH(buf, "nameserver") && nserv < MAXNS) {
struct addrinfo hints, *ai;
...
if (getaddrinfo(cp, sbuf, &hints, &ai) == 0 &&
ai->ai_addrlen <= minsiz) {
if (statp->_u._ext.ext != NULL) {
memcpy(&statp->_u._ext.ext->nsaddrs[nserv],
ai->ai_addr, ai->ai_addrlen);
}
if (ai->ai_addrlen <=
sizeof(statp->nsaddr_list[nserv])) {
memcpy(&statp->nsaddr_list[nserv],
ai->ai_addr, ai->ai_addrlen);
} else
statp->nsaddr_list[nserv].sin_family = 0;
freeaddrinfo(ai);
nserv++;
}
}
continue;
}
|
继续向下到res_nsend中,就可以看到aosp默认的串行逻辑实现,根据res_state中设置的retry和name server,轮询阻塞发包。
循环内单次逻辑分为socket random_bind,connect,sendto和retrying_select。
如果将串行改并行,需要找到一个异步操作逻辑才可以实现。
而random_bind,connect,sendto都是阻塞逻辑,是没有机会做异步的,只有select操作是异步的。
但是回到代码,select操作是封装在send_dg中的,而retrying_select的参数只有一个name server建立的socket的对应fd
static int
retrying_select(const int sock, fd_set *readset, fd_set *writeset, const struct timespec *finish)
{
struct timespec now, timeout;
int n, error;
socklen_t len;
...
}
|
那么就需要:
1、把nameserver数组下放到select
2、循环建立socket并把socket fd数组下放
3、在select处增加循环
4、一旦有可读且有效数据,停止其他socket的select
把name server数组传到select逻辑处:
+retrying_select_array(const int socks[], const bool usable_servers[], int available_sock, fd_set *readset, fd_set *writeset, const struct timespec *finish)
+{
+ struct timespec now, timeout;
+ int n, error;
+ socklen_t len;
+ int ns;
+
+retry:
+ for (ns = 0; ns < MAXNS; ns++) {
+ if (!usable_servers[ns]) continue;
+ int sock = socks[ns];
...
+ n = pselect(sock + 1, readset, writeset, NULL, &timeout, NULL);
+ if (n == 0) {
+ syslog(LOG_WARNING, " %d retrying_select_array timeout. Abort all sockets query.\n", sock);
+ errno = ETIMEDOUT;
+ return 0;
+ }
...
+ return n;
+}
|
然后将send_dg中建立socket的循环建立,并将fd数组下发
+ int ns;
+ for (ns = 0; ns < statp->nscount; ns++) {
+ nsap = get_nsaddr(statp, (size_t)ns);
+ nsaplen = get_salen(nsap);
+ char abuf[NI_MAXHOST];
+ getnameinfo(nsap, (socklen_t)nsaplen, abuf, sizeof(abuf),
+ if (statp->_mark != MARK_UNSET) {
+ if (setsockopt(EXT(statp).nssocks[ns], SOL_SOCKET,
+ SO_MARK, &(statp->_mark), sizeof(statp->_mark)) < 0) {
+ res_nclose(statp);
+ return -1;
+ }
+ }
+ if (random_bind(EXT(statp).nssocks[ns], nsap->sa_family) < 0) {
+ Aerror(statp, stderr, "bind(dg)", errno, nsap,
+ nsaplen);
res_nclose(statp);
- return -1;
+ return (0);
}
+ if (__connect(EXT(statp).nssocks[ns], nsap, (socklen_t)nsaplen) < 0) {
+ Aerror(statp, stderr, "connect(dg)", errno, nsap,
+ nsaplen);
+ res_nclose(statp);
+ return (0);
+ }
+ if (send(s, (const char*)buf, (size_t)buflen, 0) != buflen) {
+ Perror(statp, stderr, "send", errno);
res_nclose(statp);
return (0);
}
- if (__connect(EXT(statp).nssocks[ns], nsap, (socklen_t)nsaplen) < 0) {
- Aerror(statp, stderr, "connect(dg)", errno, nsap,
- nsaplen);
+ if (sendto(s, (const char*)buf, buflen, 0, nsap, nsaplen) != buflen)
+ {
+ Aerror(statp, stderr, "sendto", errno, nsap, nsaplen);
n = retrying_select_array(EXT(statp).nssocks, usable_servers, s, &dsmask, NULL, &finish);
...
}
|
还有部分边缘逻辑,比如控制整体超时,以及判断数据有效的逻辑暂时不讲述。
下图是修改后的dns行为,三个ns会一起发包,为避免某些网关不支持同时处理多个包,还需要加入大概2ms的延时间隔(此处例子未加入延时)
只要上层收到任何一个ns的有效包即可停止select
