1、技术背景:
传统的TCP/IP通信方式在两台PC之间的传输过程大概是这样的:
- 发送端需要将数据从用户空间复制到内核空间的Socket Buffer
- 发送端在内核空间中添加数据包头,进行数据封装
- 数据从内核空间的Socket Buffer复制到NIC Buffer进行网络传输
- 接收端接收到从远端发送的数据包后,要将数据包从NIC Buffer中复制到内核空间的Socket Buffer
- 经过一系列网络协议进行数据包的解析工作,将解析后的数据从内核空间的Socket Buffer复制到用户空间
- 进行系统上下文切换,用户应用程序才被调用
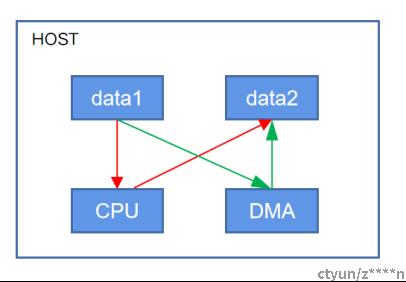
多次上下文切换,内存拷贝需要CPU介入,导致处理延时大,消耗CPU。同时传统内存访问需要通过CPU进行数据copy来移动数据,通过CPU将内存中的是数据进行搬运。在DMA模式下中,计算机主板上的设备通过DMA直接把数据发送到目标内存中去,数据搬运不需要CPU的参与。如下图所示,图中红色部分是CPU参与数据搬运,绿色部分是DMA搬运数据。
2、RDMA概念
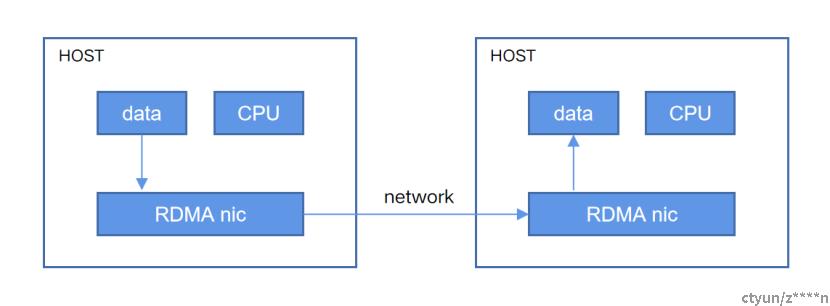
RDMA( Remote Direct Memory Access )意为远程直接地址访问,通过RDMA,本端节点可以“直接”访问远端节点的内存。所谓直接,指的是可以像访问本地内存一样,绕过传统以太网复杂的TCP/IP网络协议栈读写远端内存,而这个过程对端是不感知的,而且这个读写过程的大部分工作是由硬件而不是软件完成的。如下图所示:
3、与传统通信对比的优势:
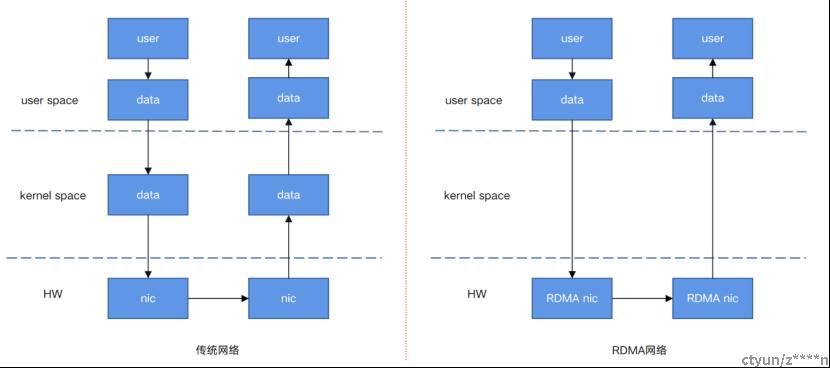
如上图所示:可以看到传统的方法需要经过用户态->内核->硬件。而RDMA直接是只经过用户态,数据的存取是通过RDMA硬件直接操作内存的。
使用RDMA的优势如下:
- 零拷贝:用户的数据能够被直接发送到缓冲区或者能够直接从缓冲区里接收,而不需要被多次拷贝。
- 内核bypass:用户可以直接在用户态执行数据传输,不需要在内核态与用户态之间做上下文切换;
- CPU卸载:用户可以访问远程主机内存而不消耗远程主机中的任何CPU。可以在远程主机不知情的情况下对其进行读写操作。
4、支持RDMA的网络协议
目前支持RDMA的网络协议主要有三种:
- InfiniBand(IB)
- iWARP(RDMA over TCP/IP)
- RoCE(RDMA over Converged Ethernet)
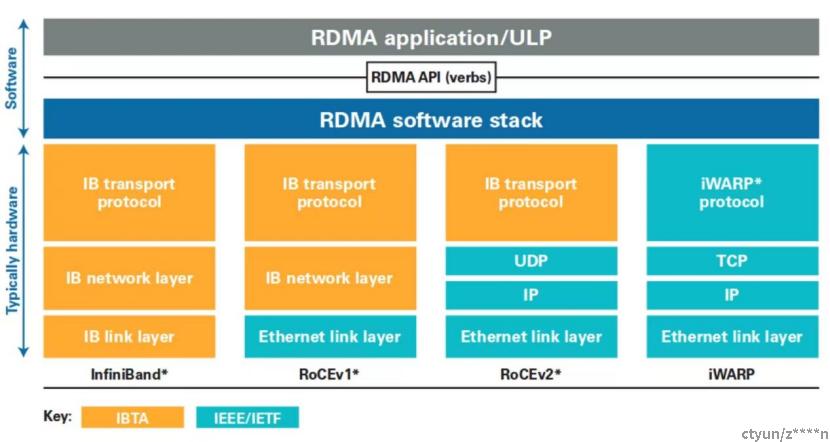
上图对于几种常见的RDMA技术的协议层次做了非常清晰的对比,
4.1、Infiniband
由IBTA(InfiniBand Trade Association)提出的IB协议,RDMA在设计的时候重新定义了物理链路层、网络层、传输层,所以要使用专用的IB交换机和网卡做物理隔离的专网,成本较大,但性能表现最优。
4.2、RoCE
RoCEv2是运行在以太网之上的RDMA,RoCEV1基于以太网数据链路层协议,仅可在局域网的单个广播域内传输。RoCEv2基于UDP协议,支持路由协议,传输距离更远。RoCEv2需要支持“无损以太网”以达到类似于InfiniBand的性能特征,一般通过无损以太网的优先流量控制(PFC)配置保证拥塞时不丢包,同时使用ECN进一步减缓拥塞。
4.3、iWARP
iWARP将InfiniBand移植到TCP/IP协议栈,使主流的以太网支持RDMA,支持在标准的以太网交换机上运行RDMA,但缺点在于TCP协议开销较大,且算法复杂,失去了大部分的RDMA性能优势。
综上:虽然有软件实现的RoCE和iWARP协议,但是真正商用时上述几种协议都需要专门的硬件(网卡)支持。
5、RDMA 基本元素:
5.1、队列(Queue)
- RDMA一共支持三种队列:
(1)发送队列Send Queue(SQ)和接收队列Recv Queue(RQ),SQ和RQ通常成对创建,被称为Queue Pairs(QP)。
(2)完成队列Completion Queue(CQ)。
- 队列中的元素:
(1)SQ和RQ中元素的叫WQE(Work Queue Element,工作队列元素),因此SQ和RQ也被统称为WQ。
(2)CQ中的元素叫CQE(Completion Queue Elemen)。
5.2、WR和WC:
WR全称Work Request,意为工作请求;WC全称Work Completion,意为工作完成。这两者其实是WQE和CQE在用户层的“映射”。因为用户是通过调用协议栈接口来完成RDMA通信的,WQE和CQE本身并不对用户可见,是驱动中的概念。用户真正通过Verbs API下发的是WR,收到的是WC。
5.3、Memory Registration(MR) | 内存注册
MR全称为Memory Region,指的是由RDMA软件层在内存中规划出的一片区域,用于存放收发的数据。IB协议中,用户在申请完用于存放数据的内存区域之后,都需要通过调用IB框架提供的API注册MR,才能让RDMA网卡访问这片内存区域。
注册MR主要解决三个问题:(1)实现虚拟地址与物理地址转换,(2)避免进程换页导致数据发生变化;(3)控制本端和对端访问内存的权限。
6、RDMA基本操作
6.1、概述:
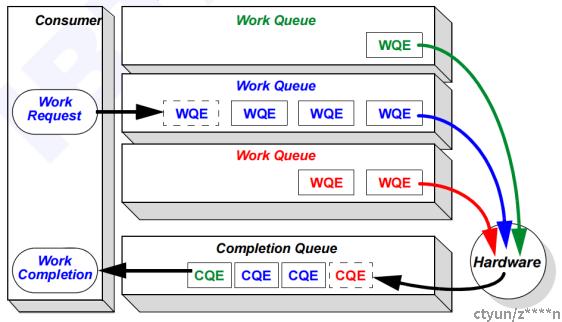
以生产者-消费者角度简单概述如下:
(1)HOST提交工作请求WR,将WR放到(post)工作队列WQ(SQ和RQ)。此时SQ和RQ中就有WQE(WR),等待RDMA硬件消费;
(2)RDMA硬件从SQ和RQ中消费WQE(WR);
(3)RDMA硬件消费完成后,产生CQE(WC),将CQE放入CQ队列中,等待HOST消费。
(4)HOST从CQ中消费WC(CQE)。
6.2、RDMA SEND/RECV操作:
SEND/RECV是双边操作,即需要通信双方的参与,并且RECV要先于SEND执行,这样对方才能发送数据,当然如果对方不需要发送数据,可以不执行RECEIVE操作。如下图所示(图中的顺序不一定是正确的,处理逻辑由硬件决定的):
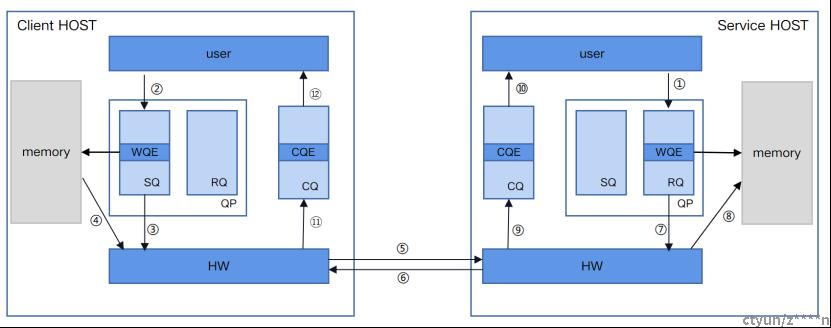
(1)service host以WR(WQE)的形式下发一次RECV任务到RQ。
(2)client host以WR(WQE)的形式下发一次SEND任务到SQ。
(3)client host的RDMA硬件(具有RDMA功能的硬件)从SQ中消费WQE。
(4)client host的RDMA硬件从内存中拿到待发送数据,组装数据包。
(5)client host的网卡将数据包通过物理链路发送给service网卡。
(6)service host收到数据,进行校验后回复ACK报文给client。
(7)service host的RDMA硬件从RQ中消费WQE。
(8)service host的RDMA硬件将数据放到WQE中指定的位置。
(9)service host的RDMA硬件生成CQE,放置到CQ中。
(10)service host消费CQE。
(11)client host的RDMA硬件收到ACK后,生成CQE,放置到CQ中。
(12)client host消费CQE。
6.3、RDMA WRITE操作:
RDMA WRITE是单边操作,是本端主动写入远端内存的行为,除了准备阶段(建链、交换内存信息),远端CPU不需要参与,也不感知何时有数据写入、数据在何时接收完毕。如下图所示:
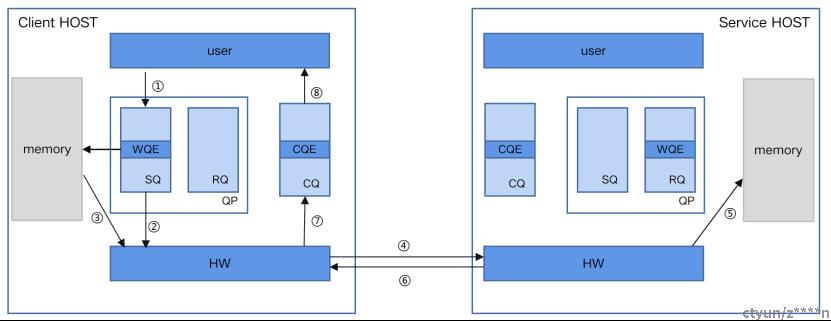
(1)client host以WR(WQE)的形式下发一次WRITE任务。
(2)client host的RDMA硬件从SQ中取出WQE,解析信息。
(3)client host的RDMA硬件根据WQE中的虚拟地址,转换得到物理地址,然后从内存中拿到待发送数据,组装数据包。
(4)client host网卡将数据包通过物理链路发送给service网卡。
(5)service host的RDMA硬件收到数据包,解析目的虚拟地址,转换成本地物理地址,解析数据,将数据放置到指定内存区域。
(6)service host回复ACK报文给client。
(7)client host的RDMA硬件收到ACK后,生成CQE,放置到CQ中。
(8)client host消费CQE。
6.4、RDMA READ操作:
RDMA READ也是单边操作,与WRITE是相反的过程,是本端主动读取远端内存的行为。同WRITE一样,远端CPU不需要参与,也不感知数据在内存中被读取的过程。如下图所示:
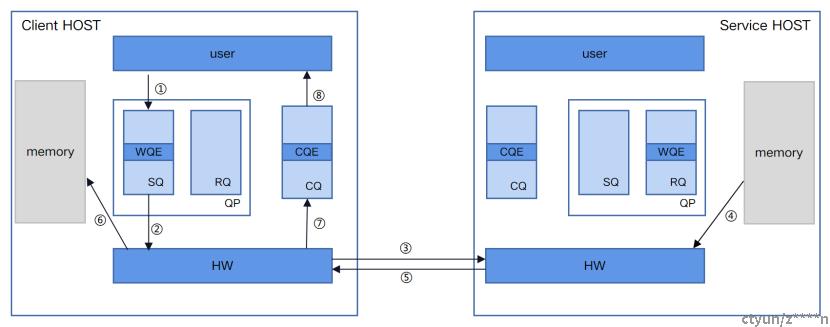
(1)client host以WR(WQE)的形式下发一次READ任务。
(2)client host的RDMA硬件从SQ中取出WQE,解析信息。
(3)client host的网卡将READ请求包通过物理链路发送给service。
(4)service host收到数据包,解析目的虚拟地址,转换成本地物理地址,解析数据,从指定内存区域取出数据。
(5)service host的RDMA硬件将数据组装成回复数据包发送到物理链路。
(6)client host的RDMA硬件收到数据包,解析提取出数据后放到READ WQE指定的内存区域中。
(7)client host的RDMA硬件生成CQE,放置到CQ中。
(8)client host消费CQE。
7、RDMA编程接口之IB Verbs API:
7.1一些基本信息了解:
- RDMA Core 指开源RDMA用户态软件协议栈,包含用户态框架、各厂商用户态驱动、API帮助手册以及开发自测试工具等。rdma-core在github上维护,我们的用户态Verbs API实际上就是它实现的。
路径:https://github.com/linux-rdma/rdma-core
- kernel RDMA subsystem指开源的Linux内核中的RDMA子系统,包含RDMA内核框架及各厂商的驱动。RDMA子系统跟随Linux维护,是内核的的一部分。一方面提供内核态的Verbs API,一方面负责对接用户态的接口。
驱动路径:kernel/drivers/infiniband; 头文件kernel/include/rdma;和 kernel/include/uapi/rdma。
- OFED:全称为OpenFabrics Enterprise Distribution,是一个开源软件包集合,其中包含内核框架和驱动、用户框架和驱动、以及各种中间件、测试工具和API文档。
开源OFED由OFA组织负责开发、发布和维护,它会定期从rdma-core和内核的 RDMA子系统取软件版本,并对各商用OS发行版进行适配。除了协议栈和驱动外, 还包含了perftest等测试工具。
7.2 什么是Verbs API
Verbs API是一组用于使用RDMA服务的最基本的软件接口,也就是说业界的RDMA应用,向用户提供了有关RDMA的一切功能,典型的包括:注册MR、创建QP、Post Send、Post send、Poll CQ等等。
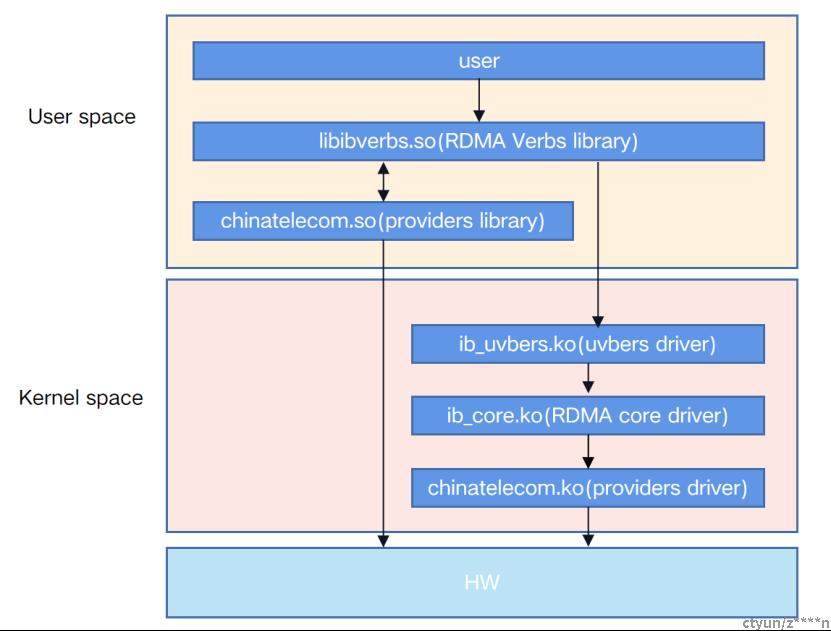
对于Linux系统来说,Verbs的功能由rdma-core和内核中的RDMA子系统提供,分为用户态Verbs接口和内核态Verbs接口,分别用于用户态和内核态的RDMA应用。
组件架构如下: