


一、基本简介
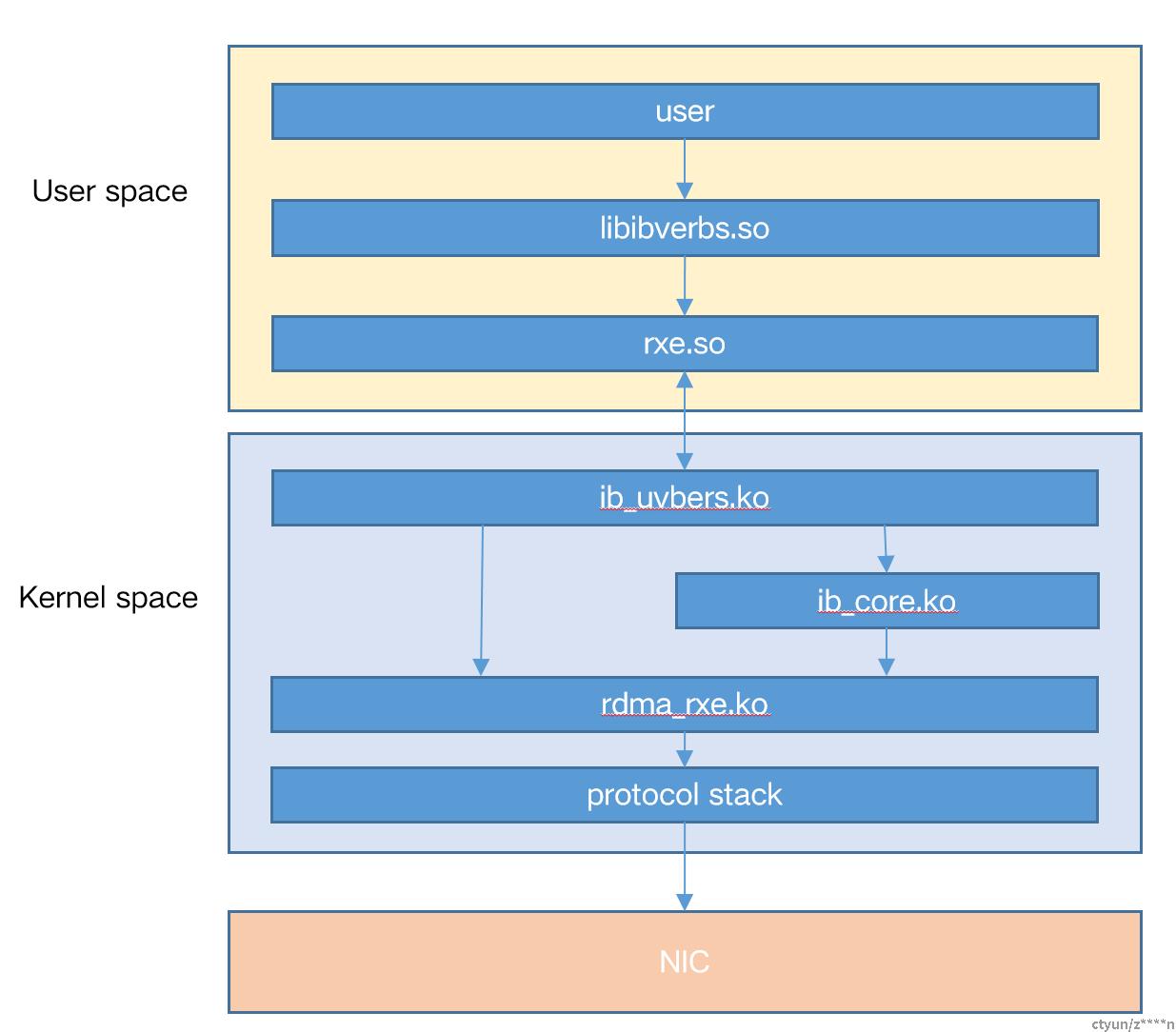
rxe是完全使用软件实现的rdma协议。基本架构如下图所示,特性如下:
- 基于udp实现
- 向用户呈现的是一套标准的IB verbs接口
- 基于标准的IB spec实现
- 所有的verbs操作都需要陷入内核。不同于硬件RDMA,数据路径by-pass kernel
- 支持RDMA的操作:SEND/RECV、WRITE、READ、ATOMIC
- 支持RC、UC、UD
- 支持NAK重传、超时重传机制
- 支持累计ACK,WQE是一个一个确定,CI依次+1
- 支持CQ中断,但不支持EQ。
- 不支持拥塞管理(没有PFC、ECN),依赖于内核协议栈的拥塞管理
代码路径:
用户态代码路径:rdma-core/providers/rxe/
内核代码路径:kernel/driver/infiniband/sw/rxe/
本文的分析基于内核4.19版本的代码。
二、设备初始化
1、rxe模块中使用到的两个机制pool和queue
(1)Pool机制-rxe用于管理qpc,cqc,mrc等context使用的方法,两个结构体如下所示:
struct rxe_pool_entry {
struct rxe_pool *pool;
struct kref ref_cnt;
struct list_head list;
/* only used if indexed or keyed */
struct rb_node node;
u32 index;
};
struct rxe_pool {
struct rxe_dev *rxe;
spinlock_t pool_lock; /* pool spinlock */
size_t elem_size; /*qp、cq、mr等结构体的大小*/
struct kref ref_cnt;
void (*cleanup)(struct rxe_pool_entry *obj);
enum rxe_pool_state state;
enum rxe_pool_flags flags;
enum rxe_elem_type type; /*pool 的类型*/
unsigned int max_elem; /*支持的pool的个数*/
atomic_t num_elem; /*当前pool中的个数*/
/* only used if indexed or keyed */
struct rb_root tree; /*用于管理pool*/
unsigned long *table; /*index bitmap*/
size_t table_size; /*根据max_index和min_index计算的table size*/
u32 max_index; /*和范围*/
u32 min_index;
u32 last; /*记录上次分配的bit,便于查找index*/
size_t key_offset;
size_t key_size;
};- 所有context要包含struct rxe_pool_entry成员
- 使用红黑树管理context
- pool中记录了qp,cq,mr等元素的一些基本信息,在创建时候使用。用于申请内存、资源检测是否足够等等。
(2)Queue机制-rxe模块用于管理qp、cq队列使用的方法,如下所示:
struct rxe_queue结构体说明
struct rxe_queue {
struct rxe_dev *rxe;
struct rxe_queue_buf *buf;
struct rxe_mmap_info *ip;
size_t buf_size;
size_t elem_size;
unsigned int log2_elem_size;
unsigned int index_mask;
};buf_size = sizeof(rxe_queue_buf) + queue depth * queue entry size
elem_size = queue entry size
index_mask = queue depth – 1
buf = vmalloc_user(buf_size),用于给用户态mmap使用。
struct rxe_queue_buf结构体说明:
struct rxe_queue_buf {
__u32 log2_elem_size;
__u32 index_mask; /*队列深度的掩码*/
__u32 pad_1[30];
__u32 producer_index; /*生产者index*/
__u32 pad_2[31];
__u32 consumer_index; /*消费者index*/
__u32 pad_3[31];
__u8 data[0]; /*队列的起始地址*/
};内核和用户态对queue的操作主要使用到index_mask、producer_index;和consumer_index。对于queue中的pi和ci的修改陈述:(1)mmap的内存,所以内核和用户态是操作的一个数据(2)CQ的PI内核修改,加锁;CI用户态修改,加锁;(3)SQ的PI用户态修改,加锁;CI内核修改,不加锁;(4)RQ的PI用户态修改,加锁;CI内核修改,不加锁
2、rxe模块的加载
通过insmod rdma_rxe.ko触发rxe模块的加载,主要完成下面两件事情
- 初始化udp tunnel,使用udp框架完成收发包
- 注册netdev事件,关心网卡的UP、DOWN、MTU变化等事
3、rdma设备的加载
通过sysfs或者netlink发起rxe设备add请求,与内核rxe模块通信完成rxe设备的加载(具体使用方法见后文)。
rxe模块响应add请求,通过rxe_add()函数完成结构体struct rxe_dev{}的初始化
- 初始化rxe_dev->attr,配置rdma设备cap(max qp、max_cq、max sge、max mr等等)
- 初始化rxe_dev->port,配置prot的属性(guid、MTU等等)
- 初始化rxe_dev->rxe_poll指向的结构体。pool使用rbtree管理创建的qp、mr等资源。
- 完成IB device的注册
三、MR
1、MR注册

上图是MR注册的基本过程。最终完成struct rxe_mem{}的初始化。
struct rxe_mem {
struct rxe_pool_entry pelem;
union {
struct ib_mr ibmr;
struct ib_mw ibmw;
};
struct rxe_pd *pd;
struct ib_umem *umem;
u32 lkey;
u32 rkey;
enum rxe_mem_state state;
enum rxe_mem_type type;
u64 va; /*用户传入的地址*/
u64 iova; /*用户传入的地址*/
size_t length; /*用户传入的长度*/
u32 offset; /*第一个entry的偏移*/
int access; /*访问权限*/
int page_shift;
int page_mask;
int map_shift;
int map_mask;
u32 num_buf; /* entry的个数*/
u32 nbuf;
u32 max_buf;
u32 num_map; /*一级表的个数*/
struct rxe_map **map; /*二级页表*/
};
说明:
(1)4K页表存放256个地址entry(struct rxe_phys_buf)。enrty包含了地址和长度地址和长度都是通过ib_umem_get()整理后得来的。size不一定全部是4K。可以使连续地址的大小
(2)MR的组织形式以二级页表的方式组织,
(3)MR中记录页表存放的地址,地址存放的是内核的虚拟地址
(4)rxe_mem->offset是第一个entry中的可使用的偏移。
2、lookup mr过程
(1)根据sge的key获取index,从rb tree中找到对应的mr context。 需要循环遍历。
(2)根据sge中的addr也mr context中保存的地址进行比较,将数据memcpy到payload对应的地址中。这块是sge对应的buf和skb 对应的buf互相copy(TX和RX)
四、CQ
1、CQ创建

上图是创建CQ的过程。(1)CQ有创建个数的最大限制。(2)CQ不同于MR、QP不需要用rb_tree管理,通过QP找到CQ即可。结构体如下:
struct rxe_cq {
struct rxe_pool_entry pelem;
struct ib_cq ibcq;
struct rxe_queue *queue;
spinlock_t cq_lock;
u8 notify;
bool is_dying;
int is_user;
struct tasklet_struct comp_task; /*中断函数*/
};
2、POLL CQ
(1)内核在RX流程中完成CQE结构体的赋值,根据CQ的PI,填充CQE,PI++,填充CQE过程需要加锁
(2)用户态根据CQ addr、CI和PI,获取CQE, CI++, 返回给APP.Poll cq 需要加锁的
3、CQ的中断模式;
cq->complete task用于中断模式。调用创建CQ时复制的ib_uverbs_comp_handle()处理函数。ib_uverbs_comp_handler()函数调用wake_up_interruptible()唤醒对应阻塞的线程,通知用户态处理。
五、QP
1、QP创建

上图是创建QP的基本过程,完成struct rxe_qp{}的初始化。
struct rxe_qp {
struct rxe_pool_entry pelem;
struct ib_qp ibqp;
struct ib_qp_attr attr;
unsigned int valid;
unsigned int mtu;
int is_user;
struct rxe_pd *pd;
struct rxe_srq *srq;
struct rxe_cq *scq;
struct rxe_cq *rcq;
enum ib_sig_type sq_sig_type;
struct rxe_sq sq;
struct rxe_rq rq;
struct socket *sk;
u32 dst_cookie;
struct rxe_av pri_av;
struct rxe_av alt_av;
struct list_head grp_list;
spinlock_t grp_lock; /* guard grp_list */
struct sk_buff_head req_pkts; /*内核协议栈的req pkt*/
struct sk_buff_head resp_pkts;
struct sk_buff_head send_pkts;
struct rxe_req_info req; /*tx处理*/
struct rxe_comp_info comp; /*ACK报文*/
struct rxe_resp_info resp; /*respond报文*/
atomic_t ssn;
atomic_t skb_out;
int need_req_skb;
struct timer_list retrans_timer; /*超时重传*/
u64 qp_timeout_jiffies;
/* Timer for handling RNR NAKS. */
struct timer_list rnr_nak_timer; /*rnr nak 重传*/
spinlock_t state_lock; /* guard requester and completer */
struct execute_work cleanup_work;
};说明:
(1)不同于其他的硬件RDMA厂商,没有db_record
(2)RXE是内核申请queue buf,用户态映射。硬件厂商是用户态申请
(3)收发包的回调函数参数是QP。不需要lookup QO
(4)wqe size是固定的,内核和用户态用一个结构体。SQ和RQ的组织如下:

2、TX-POST SEND

上图是Post send的基本过程。Send wqe的结构体如下:
struct rxe_send_wqe {
struct rxe_send_wr wr; /*wqe hdr信息*/
struct rxe_av av;
__u32 status;
__u32 state; /*wqe的状态 pending、process*/
__aligned_u64 iova;
__u32 mask;
__u32 first_psn; /*wqe对应报文的第一个psn*/
__u32 last_psn; /*wqe对应报文的最后一个psn*/
__u32 ack_length;
__u32 ssn;
__u32 has_rd_atomic;
struct rxe_dma_info dma; /*sge信息*/
};
说明:
(1)post send敲doorbel是向内核发送了POST_SEND的命令,代码如下;
cmd.hdr.command = IB_USER_VERBS_CMD_POST_SEND;
cmd.hdr.in_words = sizeof(cmd) / 4;
cmd.hdr.out_words = sizeof(resp) / 4;
cmd.response = (uintptr_t)&resp;
cmd.qp_handle = ibqp->handle;
cmd.wr_count = 0;
cmd.sge_count = 0;
cmd.wqe_size = sizeof(struct ibv_send_wr);
write(ibqp->context->cmd_fd, &cmd, sizeof(cmd));
(2)报文发送是在当前post send的上下文完成
(3)分片的报文要记录buf信息,一次只获取mtu大小的报文(lookup mr),填充获取addr和payload len
(4)对于需要ACK的wqe,需要pending,还需要放在SQ中
(5)QP的ci在ack后,更新
(6)post send过程加锁了(分为用户态PI加锁和内核态QP处理报文过程加锁)所以同时只有一个线程能操作队列。多个线程操作同一个qp时,第一个获取到QP资源的线程会继续处理到没有wqe,后面的线程直接返回。
(7)最终发包是调用rxe_send()函数完成。
3、RX-POST RECV

上图是post recv的过程。(1)post recv过程需要加锁,所以同时只有一个线程下发rqe(2)操作不会下限到内核。结构体如下:
struct rxe_recv_wqe {
__aligned_u64 wr_id;
__u32 num_sge; /*sge个数*/
__u32 padding;
struct rxe_dma_info dma; /*sge*/
};
4、RX
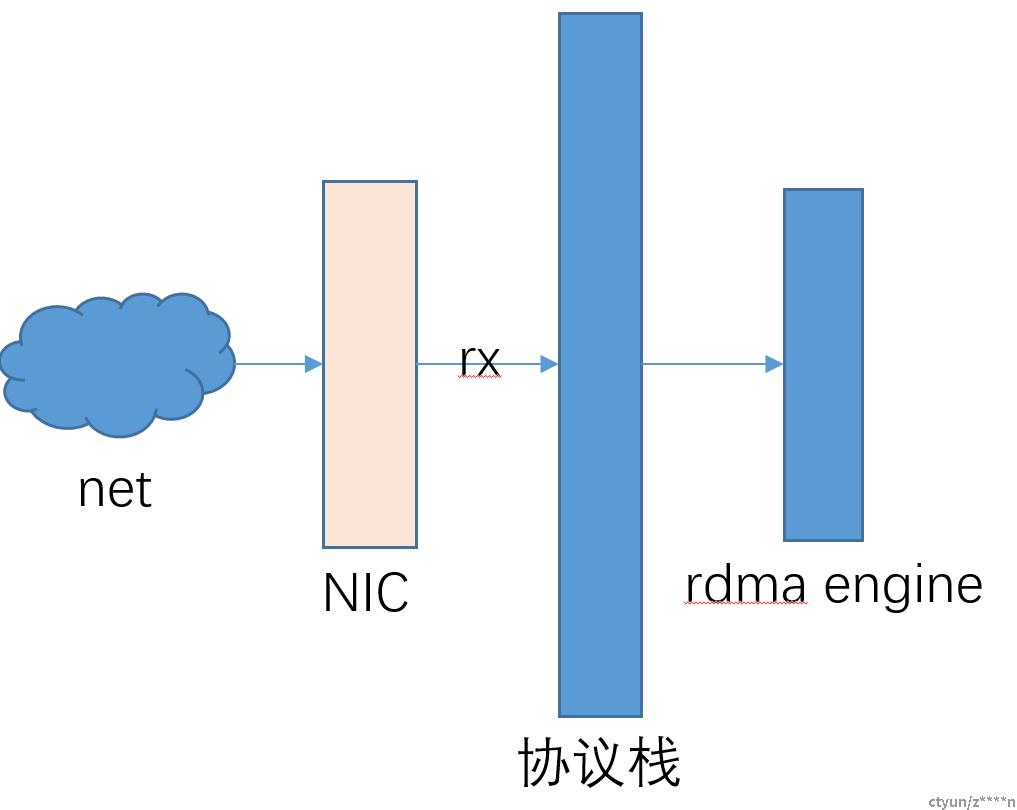
上图是RX的流程,rxe收到的包只有IB头+payload两部分,UDP之前的包头已经被剥离。收到的包分为两种包:(1)处理requester;(2)处理ACK报文;代码如下:
static inline void rxe_rcv_pkt(struct rxe_dev *rxe, struct rxe_pkt_info *pkt,struct sk_buff *skb)
{
if (pkt->mask & RXE_REQ_MASK)
rxe_resp_queue_pkt(rxe, pkt->qp, skb);
else
rxe_comp_queue_pkt(rxe, pkt->qp, skb);
}
5、RX-请求报文

上图是处理request报文的过程。简单说明:
(1)RDMA read request在softirq上下文处理,获取buf,通过rxe_send发送
(2)Requester 队列中的报文大于1个,在softirq中处理
(3)只有一个报文,在UDP tunnel收包上下文处理
6、RX-ACK报文
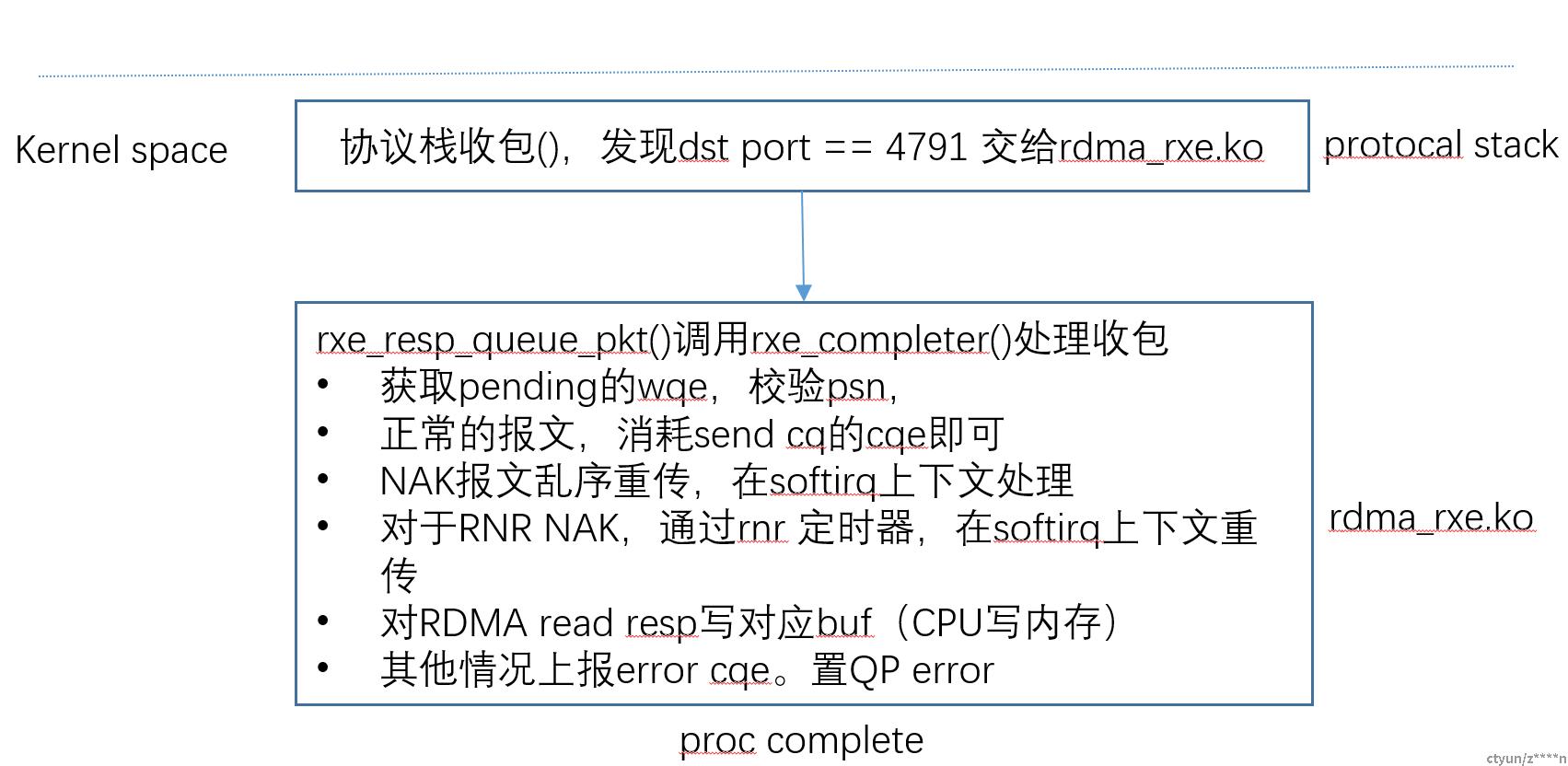
上图是处理ACK报文的过程。简单说明:
(1)当respond 队列中的报文数量大于1,在softirp上下文处理
(2)一个报文,在UDP tunnel收包上下文处理
(3)没有处理cq full的情况,应该是认为报文是成功发送的,用户不用关心。
(4)SQ ci ++
7、RX-ACK报文之RDMA_READ_RESPOND
解析ACK报文,判断opcode是rdma read resp,处理过程如下:
(1)首先从SQ中获取根据CI和SQ_addr获取wqe
(2)解析wqe,获取要存储报文的sge
(3)将rdma read resp的报文写到对应的buf中
- 如果是多个rdma read resp报文,wqe还继续维持pending,同时记录写sge的偏移(写struct rxe_send_wqe->dma)。
- 当多个rdma read resp 报文全部收齐后,ci ++,释放wqe。
8、RX-累计ACK功能
(1)首先从SQ中获取根据CI和SQ_addr获取wqe。
(2)解析wqe,发现wqe->last_psn(这个wqe对应的最后一个分片报文的psn) < ack 报文中的psn时,认为是累计ack
- Send/write操作,会处理到相同psn的wqe即可,一个wqe上送一个cqe。如果不是全部上送cqe或者不要求上送cqe,则不上送cqe
- 如果pending的wqe是Rdma read resp 或者atomic报文就任务丢包了,需要重传
使用方法:
1、前提条件:
(1)确定设备上是否有rxe的用户态驱动,不存在需要更新/安装rdma-core
- 查看/etc/libibverbs.d/目录下是否有driver
- 查看设备上是否有librxe-rdma.so

(2)确定设备上是否有IB、rxe的内核驱动,不存在就找对应的内核源码,单独编译driver/infiniband/生成驱动
- 查看是否有ko,ib_core.ko,rdma_rxe.ko

2、添加设备
(1)两种方法:
- 通过rdma link add命令,(只在高版本内核中支持)
- rdma link add xxx type rxe netdev xxx 命令通过netlink与内核IB模块交互,与c中的注册模块完成rxe设备的添加

- 通过sysfs添加
- echo xxx(网卡) > /sys/module/rdma_rxe/parameters/add。如果没有parameters目录,就是加载ko不正确。


3、性能测试:
使用perftest测试,使用标卡和cx6对打测试,中间一跳交换机
- 8个进程占用8个核,带宽:22Gb
- 时延:26us
- PPS:0.5M
分析
- 数据面需要陷入内核操作
- 数据包需要经过一次完整的协议栈
- rxe发包过程中,需要将内存通过CPU将数据写入发包缓存中,网卡还需要一次dma才能将数据发送出去
- rxe的收包是瓶颈,写内存是CPU处理 softirq
4、测试网卡的选择
- 尽可能的使用不带有rdma功能的网卡
- 使用Mlnx网卡测试rxe的时候,网卡会截获rdma报文,不会上送rxe。
