


1. 概念与术语
|
术语 |
场景 |
解释 |
|
一致性 |
通用 |
狭义的说,在分布式系统中,多个节点中数据的值是一致的;同时,也指事务的基本特征或特性相同。 |
|
强一致性 |
通用 |
系统中的某个数据被成功更新后,后续任何对该数据的读取操作都将得到更新后的值。 |
|
弱一致性 |
通用 |
系统中的某个数据被更新后,后续对该数据的读取操作可能得到更新后的值,也可能是更改前的值。 |
|
最终一致性 |
通用 |
是弱一致性的特殊形式,存储系统保证在没有新的更新的条件下,最终所有的访问都是最后更新的值。 |
|
Proposer(发起者) |
PAXOS |
处理客户端请求,将客户端的请求发送到集群中,以便决定这个值是否可以被批准。 |
|
Acceptor(批准者) |
PAXOS |
负责处理接收到的提议,他们的回复就是一次投票,会存储一些状态来决定是否接收一个值。 |
|
Learner(学习者) |
PAXOS |
不参与决策,当Proposer/Acceptor达成一致之后,接受决策的值。 |
|
Proposal(提案) |
PAXOS |
提议内容,包含编号ID和提议值。 |
|
Epoch(提案编号) |
PAXOS |
提案唯一id,可以确定提案先后顺序。 |
|
Consistency(强一致性) |
CAP |
副本强一致性。 |
|
Availability(可用性) |
CAP |
系统在出现异常时依旧可以提供服务。 |
|
Tolerance to the partition of network(分区容忍性) |
CAP |
指系统可以对网络分区异常情况进行容错处理。 |
|
Leader(领导者) |
RAFT |
负责发起投票和决议;更新系统状态。 |
|
Follower(跟随者) |
RAFT |
接受客户端请求;备份决议内容;参与选主。 |
|
Observer(观察者) |
RAFT |
接受客户端请求;备份决议内容;不参与选主。 |
|
LOOKING(选主状态) |
RAFT |
Leader down 或初始状态,选主中。 |
|
LEADING(主状态) |
RAFT |
Server当选后的状态。 |
|
FOLLOWING(备状态) |
RAFT |
Leader当选后,Follower的状态。 |
|
zxid |
RAFT |
(e, c) – 其中 e 表示PAXOS第一阶段epoch, c 表示第二阶段propose 计数 |
|
(v, z) |
RAFT |
一次事务的表示,其中v 为propose的值, z 为 zxid |
2. 分布式一致性定义
在分布式环境中,一致性是指数据在多个副本之间是否能够保持一致的特性。如果对第一个节点的数据进行了更新操作并且更新成功后,却没有使得第二个节点上的数据得到相应的更新,于是在对第二个节点的数据进行读取操作时,获取的依然是老数据(或称为脏数据),这就是典型的分布式数据不一致情况。
在分布式系统中,如果能够做到针对一个数据项的更新操作执行成功后,所有的用户都可以读取到其最新的值,那么这样的系统就被认为具有强一致性(或严格的一致性)。
3. 分布式一致性实现
3.1. PAXOS
Paxos算法是Lamport提出的一种基于消息传递的分布式一致性算法。自Paxos问世以来就持续垄断了分布式一致性算法,Paxos这个名词几乎等同于分布式一致性。Google的很多大型分布式系统都采用了Paxos算法来解决分布式一致性问题,如Chubby、Megastore以及Spanner等。开源的ZooKeeper也是采用Paxos算法解决分布式一致性问题。
Paxos算法中涉及的角色包括Proposer、Acceptor、Learner,达成决议需要经过两个阶段,Prepare阶段、Accept阶段,以及达成决议之后的Learn阶段。典型的流程如下如下:
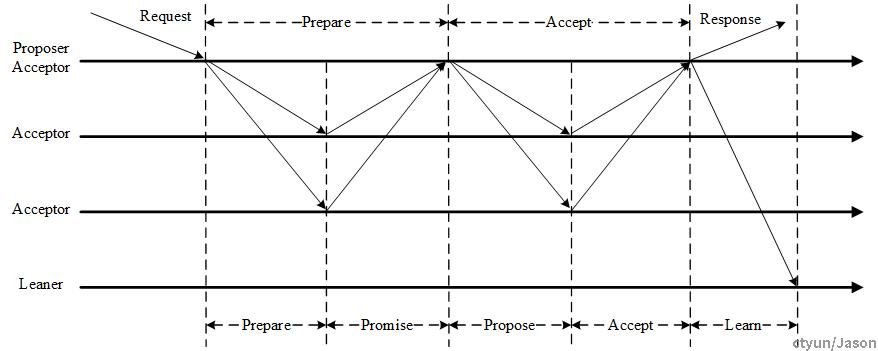
3.1.1. 第一阶段 - Prepare
在Prepare阶段,主要是为了达成一致谁可以提交Proposal,以及提交Proposal的编号与值。具体过程为
- 获取一个Proposal ID n,为了保证Proposal ID唯一,可采用时间戳+Server ID生成;
- Proposer向所有Acceptors广播Prepare(n)请求;
- Acceptor比较n和minProposal,如果n>minProposal,minProposal=n,并且将 acceptedProposal 和 acceptedValue 返回;
- Proposer接收到过半数回复后,如果发现有acceptedValue返回,将所有回复中acceptedProposal最大的acceptedValue作为本次提案的value,否则可以任意决定本次提案的value;
3.1.2. 第二阶段 - Accept
在Accept阶段,由于第一阶段以及确定可以提交Proposal的Proposer,已经Proposal编号,第二阶段Proposer就可以根据规则提交Proposal。具体过程为
- Proposer广播Accept (n, value) 到所有节点;
- Acceptor比较n和minProposal,如果n>=minProposal,则acceptedProposal=minProposal=n,acceptedValue=value,本地持久化后,返回;否则,返回minProposal。
- 提议者接收到过半数请求后,如果发现有返回值result >n,表示有更新的提议,跳转到第一阶段;否则value达成一致。
3.1.3. 第三阶段 - Learn
在完成第二阶段之后,一致性已经达成了,此时Proposer已经对客户端的请求做响应。同时Proposer可以将决议内容发给所有Learner。
3.1.4. 伪代码
为方便理解实际过程,以下两个为Proposer与Acceptor的伪代码:
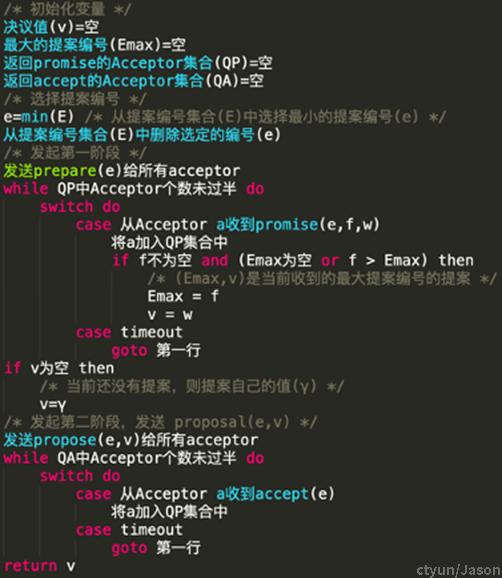

提案编号(e) – 每次提案的编号,需要具有唯一性,且能比较大小。
准备(prepare(e)) - Proposer发起提案前确认当前的提案编号是否可以发起提案。
承诺(promise(e, f, w)) - Acceptor告诉Proposer承诺接受编号f的提案,其值为w,且不再受理比f小的提案。
提案(propose(e, v)) – Proposer 提交的一次决议请求,包含待决议的值和提案编号。
接受(accept(e)) - Acceptor接受了提案编号e的提案。
3.1.5. 举例
以下为一次Paxos过程:
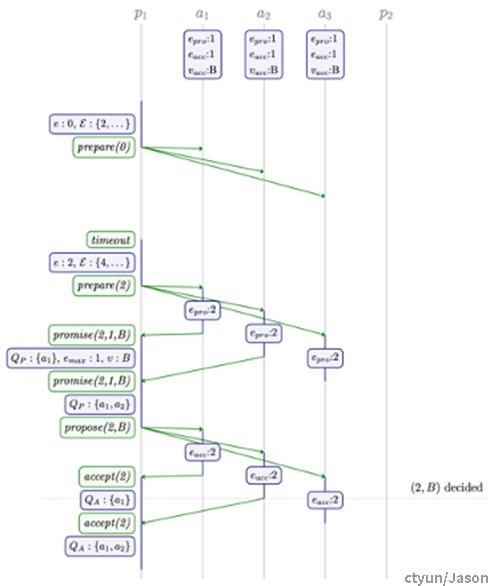
- 初始状态(P2完成两阶段,值B被接受,所有的Acceptor上都已经Promise并接受编号为1,值为B的提案)
- Proposer 1 发起第一阶段,准备提交编号为0的提案,超时
- Proposer 1 再次发起第一阶段,准备提交编号为2的提案
- Accepter 收到请求后,都承诺接受编号为2的提案,并告知Proposer 1当前已经接受了B值
- Proposer 1 发起第二阶段,提案编号2值为B
- Acceptor收到提案后,接受编号为2的提案,值为B
3.2. RAFT
由于PAXOS算法比较难理解,且难以实现,RAFT算法诞生。RAFT算法将分布式系统一致性问题转化为多个子问题:Leader选举(Leader election)、日志同步(Log replication)、安全性(Safety)、日志压缩(Log compaction)、成员变更(Membership change)等。
3.2.1. Leader选举
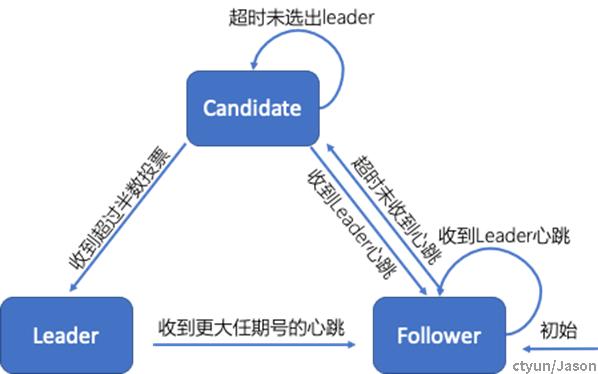
当服务器启动时,初始化为Follower。如果Follower在选举超时时间内没有收到Leader的heartbeat,就会等待一段随机的时间后发起一次Leader选举。Follower将其当前term加一然后转换为Candidate。它首先给自己投票并且给集群中的其他服务器发送 RequestVote RPC。结果有以下三种情况:
- 赢得了多数的选票,成功选举为Leader;
- 收到了Leader的消息,表示有其它服务器已经抢先当选了Leader;
- 没有服务器赢得多数的选票,Leader选举失败,等待选举时间超时后发起下一次选举。
选举出Leader后,Leader通过定期向所有Followers发送心跳信息维持其统治。若Follower一段时间未收到Leader的心跳则认为Leader可能已经挂了,再次发起Leader选举过程。
3.2.2. 日志同步
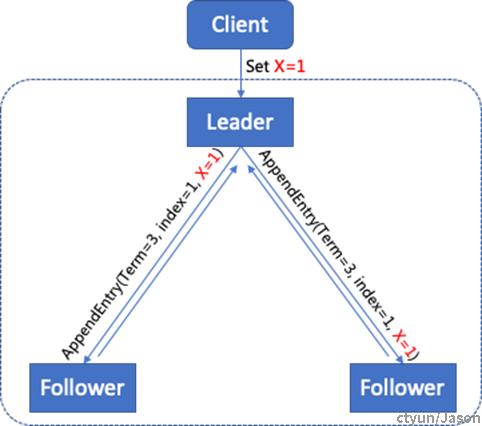
Leader把请求作为日志条目(Log entries)加入到它的日志中,然后并行的向其他服务器发起AppendEntries RPC复制日志条目。当这条日志被复制到大多数服务器上,Leader将这条日志应用到它的状态机并向客户端返回执行结果。
某些Followers可能没有成功的复制日志,Leader会无限的重试 AppendEntries RPC直到所有的Followers最终存储了所有的日志条目。
日志由有序编号(log index)的日志条目组成。每个日志条目包含它被创建时的任期号(term),和用于状态机执行的命令。如果一个日志条目被复制到大多数服务器上,就被认为可以提交(commit)了。
Raft日志同步保证如下两点:
- 如果不同日志中的两个条目有着相同的索引和任期号,则它们所存储的命令是相同的。
- 如果不同日志中的两个条目有着相同的索引和任期号,则它们之前的所有条目都是完全一样的。
3.2.3. 安全性
Raft增加了如下两条限制以保证安全性:
- 拥有最新的已提交的log entry的Follower才有资格成为Leader。Candidate在发送RequestVote RPC时,要带上自己的最后一条日志的term和log index,其他节点收到消息时,如果发现自己的日志比请求中携带的更新,则拒绝投票。日志比较的原则是,如果本地的最后一条log entry的term更大,则term大的更新,如果term一样大,则log index更大的更新。
- Leader只能推进commit index来提交当前term的已经复制到大多数服务器上的日志,旧term日志的提交要等到提交当前term的日志来间接提交(log index 小于 commit index的日志被间接提交)。
3.2.4. 举例
Raft官网介绍文档上有一个动态演示的工具,可以可视化Leader选举、日志复制、成员变更等过程,而且可以模拟特定包丢弃、网络超时等故障,以及故障恢复后系统自愈过程。详情见链接。
4. CAP原理
CAP原理是指在一个分布式系统中,不可能同时满足一致性(C:Consistency)、可用性(A: Availability)和分区容错性(P:Partition tolerance)这三个基本需求,最多只能同时满足其中的两项。
- 一致性指强一致性,具体见前文。
- 可用性是指系统提供的服务必须一直处于可用的状态,对于用户的每一个操作请求总是能够在有限的时间内返回结果。
- 分区容错性是指分布式系统在遇到任何网络分区故障的时候,仍然需要能够保证对外提供满足一致性和可用性的服务,除非是整个网络环境都发生了故障。
从 CAP 定理中我们可以看出,一个分布式系统不可能同时满足一致性、可用性和分区容错性这三个需求。对于一个分布式系统而言,组件必然需要被部署到不同的节点,因此网络问题是一个必定会出现的异常情况,所以分区容错性就成为了一个分布式系统必然需要面对和解决的问题。因此系统架构设计师往往需要把精力花在如何根据业务特点在C(一致性)和A(可用性)之间寻求平衡。
