


问题
清洗业务向 topic 中写数据, 打标业务从 topic 中消费数据, 当两者分别运行时没有问题, 但同时运行时, 打标业务拉取消息时不时会出现 poll 超时情况, 和消费速率慢的情况
优化过程
第一次优化尝试
优化依据:
通过查看节点, 磁盘 io 处于比较高的状态
优化项:
调整 Kafka Broker 配置, 主要调整网络和IO 方面:
num.io.threads: 实际处理网络请求的线程(一般是IO操作), 由 36 增加到 60 (均为磁盘数量的倍数)queued.max.requests: 1000 增加到 2000, 增大了网络请求队列的长度
优化结果:
未有改善, 且通过 jstack 查看, 请求队列基本没有积压, io 处理线程都在等待队列的请求,说明这方面于这两个参数无关
第二次优化尝试
优化依据:
监控同学帮忙添加了监控之后, 发现节点网卡流量有很大的尖刺, 最大速率基本达到网卡的速率上限
优化项:
创建一个副本数为 2 的临时 topic -- C_DPI_hebei_4G_temp (原有的副本数是3), 观察副本拉取流量减少后情况是否有改善
优化结果:
网卡的流量峰值有降低, 业务表现有些许改善


第三次优化尝试
优化依据:
由于节点磁盘 IO 仍然较大, 考虑观察在最理想的分区分布下(每个节点的每个磁盘一个分区), 集群和业务的情况
优化项:
将临时 topic 从 250 分区扩大为 708 (59 * 12)
优化结果:
磁盘 IO 方面各个磁盘较为均匀, 但由于分区数增大, 网络流量又出现回升, , 业务情况依旧

第四次优化尝试
优化依据:
在减少副本后, 网络流量降低, 业务有少许改善, 因此判断突发的尖峰流量才是主要原因, 考虑对清洗业务的生产者进行限速, 以此来消除尖峰流量, 拉平写入速率
优化项:
对 client.id 为 kafkaGenerator 的生产者进行限流, 调整为每个 Broker 最大接收此 id 100MB/s 的写入速率
优化结果:
网络流量明显下降, 流量比较连续无峰值,
同时清洗业务(生产者)也未出现积压
消费问题有明显改善, 打标业务消费数据都在 30 s 内完成, 没有出现超时和明显变慢的情况


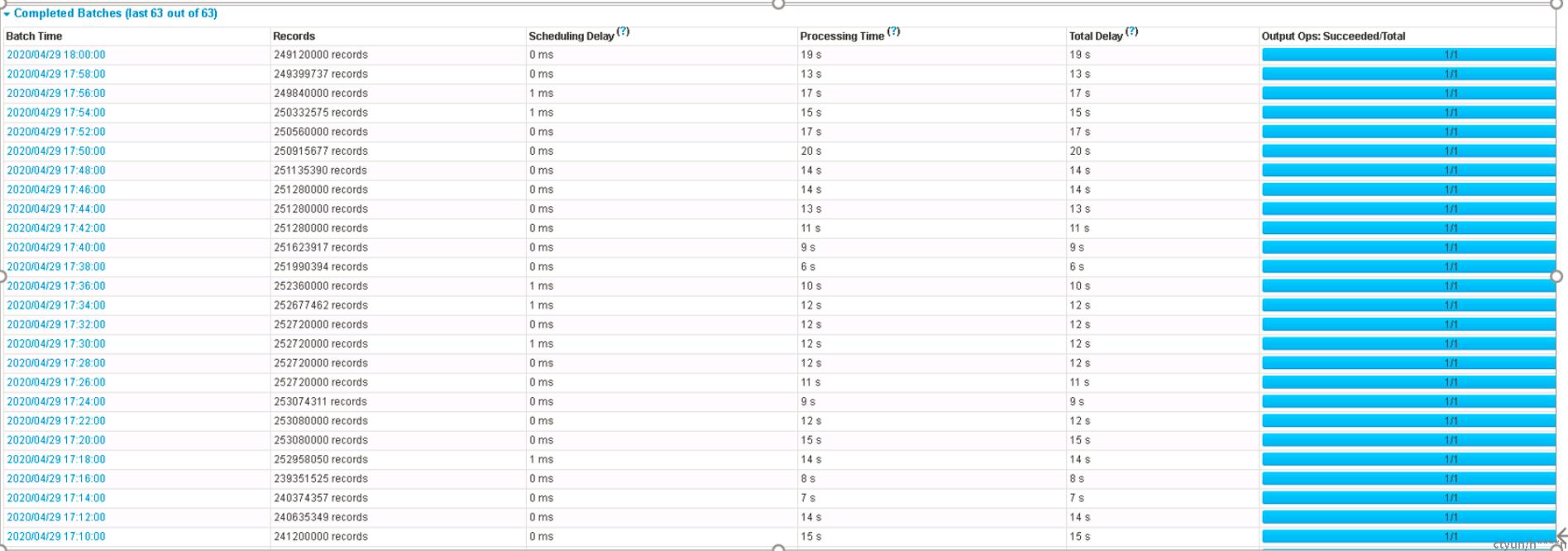
结论
- 消费者消费慢和超时问题主要由于网络流量的尖峰导致
- 通过配置客户端的 quota 来控制高峰流量, 使流量曲线平滑可以大幅度改善问题
-
优化之前, 一个批次的处理时间会出现很大的毛刺(10-20min),而且整体比较慢(2min, 3min, 7min 等), 优化之后(主要还是最后一轮优化), 处理时间最大不超过 30s, 整体在 10-15s 中
待定
本来准备的后续方案,上述改进后问题没有在出现,后续方案未执行
- 此次测试是 1/3 的数据量, 当接入全部数据量时的情况仍待观察
- Topic 的分区数和副本数可以讨论
- quota 的大小需要根据实际情况来调节
- 清洗业务的生产者也可以进行限流(如令牌桶等方法, 对他们而言要求可能比较高了)
- 在上述的方法都使用的情况下, 如果流量问题仍不能很好的解决, 可以扩容集群
