


场景描述
负责管理线上云主机生命周期的混合云管理系统需要自动化的机房调度模式:根据监控数据,流量水位,成本指数等指标,在一定的区域范围内,根据亲和性选择最优的机房并开机交付给业务。例如,存在区域-机房集合A{a,b,c}, B{d,e,f},根据成本指数X、带宽水位Y选择区域A内没有被标记禁用的最优的机房。此刻的指标数值分别为:
| X{weight: 10} | Y:{weight: 100} | |
|---|---|---|
| a | 1 | 1 |
| b | 2 | 2 |
| c {污点:禁止调度} | 3 | 3 |
| d {亲和性:倾向调度} | 2 | 2 |
❝表格省略了区域B的数值
❞
此时,我们首先筛选出区域A的机房,得到{a,b,c}
然后,根据权重计算,得到:
| X{weight: 10} | Y:{weight: 100} | 权重(简单相加) | |
|---|---|---|---|
| a | 1 | 1 | 110 |
| b | 2 | 2 | 220 |
| c {污点:禁止调度} | 3 | 3 | 330 |
| d {亲和性:倾向调度} | 2 | 2 | 220 |
此时排序为c,d|b,a,但是由于c禁止调度,被排除;d、b同分,但是由于亲和性设置,d被设置为具有倾向性,则调度到d机房。于是系统从d机房开启一个新的虚机交付给业务。
注:我们的机房对应运营商的可用区。
Kube-Scheduler设计模式
K8S的调度器为了实现调度亲和性,设计了过滤 - 评分 - 保留 - 确认 - 绑定的调度流程,具体代码位于pkg/scheduler/schedule_one.go中的Scheduler/findNodesThatFitPod方法。官方文档 Scheduling Framework | Kubernetes 也进行了一系列的描述。整个ScheduleFramework用于调度特定POD到特定节点上。
过滤流程
过滤流程包括PreFilter,Filter,PostFilter流程。评分流程包括
PreFilter流程用于筛选可用的节点,RunPreFilterPlugins执行了一系列筛选插件的对应方法。如:
-
Fit 用于计算节点CPU、内存是否有最大适配余量。因为如init-container这样的一次性任务也需要消耗CPU、GPU等资源,它需要计算满足POD全生命周期调度的资源最大值。 -
VolumeBinding 用于计算是否有满足条件的PV、PVC, -
VolumeRestrictions 用于计算对应PV、PVC是否满足读写模式, -
PodTopologySpread 用于处理亲和性和污点,过滤满足对应条件的节点 -
etc.
Filter用于过滤不适合POD调度的节点,findNodesThatPassFilters执行了对应方法。利用fwk.RunFilterPluginsWithNominatedPods执行。它处理了POD调度和抢占的任务,如:
-
Fit的Filter函数计算了所需资源的不满足项并返回,过滤掉不适合调度的节点。 -
NodePorts的Filter函数检查是否节点不满足端口条件,过滤掉了不适合的节点。
PostFilter只有一个插件,选择被抢占的POD,只有在所有node无法直接放置时生效。
评分流程
评分流程包括PreScore,Score流程。
其中PreScore做数据获取和预处理,如
-
NodeAffinity 插件的PreScore方法获取并构建了节点分数,
Score流程用于计算带权分数。如
-
NodeAffinity插件的Score方法计算了带权分数并返回。
评分标准化
评分标准化应被视为评分的一部分。因不同指标的范围不一致,可以采取求和平均取比例的方式,获得规范化的分数。
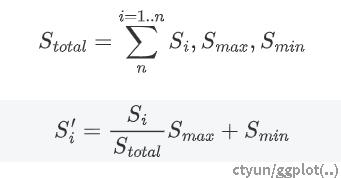
后续流程这里就不赘述了,为简化工作我们假设云厂商的库存是无限的。我们的设计里只用到了前面两个节点。
推荐调度器的设计模式
我们参照上述模型,设计我们自己的调度器。同Kube-Scheduler一样,我们设计了一个Framework结构用于存储整个上下文,并以插件实现接口的形式。代码参考runtime.Framework接口。但我们提供了符合业务的数据模型,用于满足业务需求。
数据采集
系统集成了不同数据源,如监控、成本系数以及一些第三方的自定义调度数值。这些数值会存在系统的数据库中。需要作为判定值时,获取并作为评分依据。
插件实现
过滤、评分插件同调度器的实现类似,每个插件都集成了整个调度生命周期的所有方法,如预过滤、过滤、预评分、评分方法,这样就可以适用在调度的每一个节点上。
过滤
在过滤阶段,我们放置PreFilter、Filter节点。(资源池与抢占交给了别的模块)。
PreFilter
PreFilter节点过滤出满足条件的节点,譬如根据标签筛选区域、运营商,边缘还是中心机房,根据字段筛选可用性,获得Idc列表。如上文描述的例子,根据region:A筛选出区域A下的{a, b, c}机房。其中,
-
AvailableFilterPlugin用于过滤出标记为在线的机房, -
IspFilterPlugin用与过滤出特定运营商机房, -
NetworkFlowPlugin用于过滤出满足带宽要求的机房,判定带宽余量是否能满足所需机器带宽总和 -
etc.
同时根据标签过滤自定义分区。
Filter
Filter节点用于过滤掉不满足条件的机房,适配如污点标记、整体CPU超限等反向选择条件。如上文例子中,根据污点状况,过滤掉了c机房。
评分
评分我们亦分为PreScore、Score两个节点。但是根据我们的业务需要进行划分功能。
PreScore
PreScore利用各个插件获取相关指标并进行评分。如监控水位等数据。并按照上面的公式计算标准化的评分。这个节点主要用于获取数据。如:
-
NetworkFlowPlugin的PreScore函数会从数据库拉取每个机房预处理好的带宽总量和带宽上限,判定余量。 -
ResourceMgmtPlugin的PreScore节点会获取当前机房整体负载状况。
Score
Score节点对各个指标的评分进行标准化并排序,这里由于不同的指标所需的排序问题,标准化会将排序统一处理为倒序。调度器随后会根据权重合并,选出一个最优机房。后续根据用户API传参,决定是直接交付机房ID,还是走开机流程。
总结
这种设计一定程度上解决了我们资源动态调度的问题,从一个区域内选出最优机房并交付一定量的云主机。对于更加精细的优化,指标归纳和排序模式,仍需要继续摸索。
