


场景描述
因接入多家云厂商,云主机生命周期管理是一个重要功能。由于多数大型运厂商对按量计费和包年包月在单位价格的商务策略相对不平衡,通常按量付费的每小时价格是包年包月的5倍甚至更高,且很多应用场景并不能很好地根据周期性季节性峰谷调整算力,算力调度上容易产生利用率低下的情况。例如许多大数据任务只要几个小时到几天的计算,大型K8S集群的所需集群算力也会因淡旺季而发生变化。因此从商务降本增效的角度,对非常驻的算力调度采进行池化处理是一个折中的解决方案。
设计模式
整体架构
系统初始启动时,运维管理平台根据业务需要选择机房(云厂商的可用区)从云厂商开启一定数量的包年包月云主机存放到主机池里。当有系统需要资源时,先从资源池寻找空闲的主机;若无则寻找不满足利用率的已交付主机进行回收并重置;若池中所有云主机均利用率较高,则重新开启云主机并加入池中,走交付流程。系统注销处理空闲时间过长的云主机。整体运行机制如图所示。 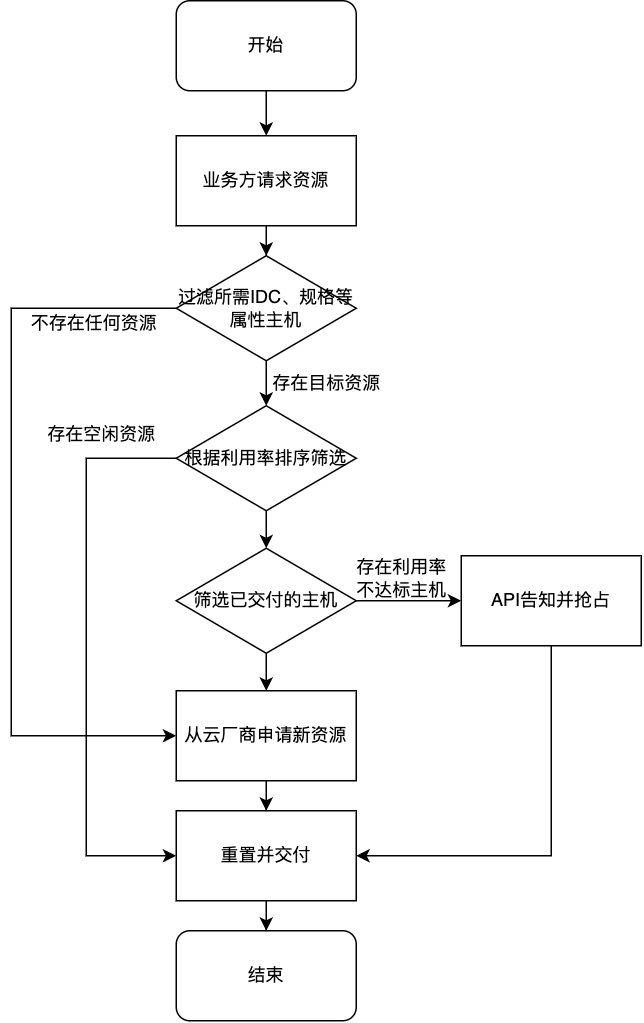
初始池化
系统开启运作时,首先根据预先设定的热点机房申请到初始数量的云主机添加到资源池里。主机的对象标记包含了如系统、CPU规格、内存规格、GPU规格、使用方业务ID等字段,用于筛选用户所需的资源属性。资源池的实现可以是一个对象列表,只要在操作时加redis锁即可。所有池中对象在使用时都需要从数据库拉取,因此在数量并不多(5000以下)的情况下并不需要专门的优化。

业务接入
业务方通过API调用获取资源。系统根据资源池状态、其他业务的利用情况决定是否进行抢占。 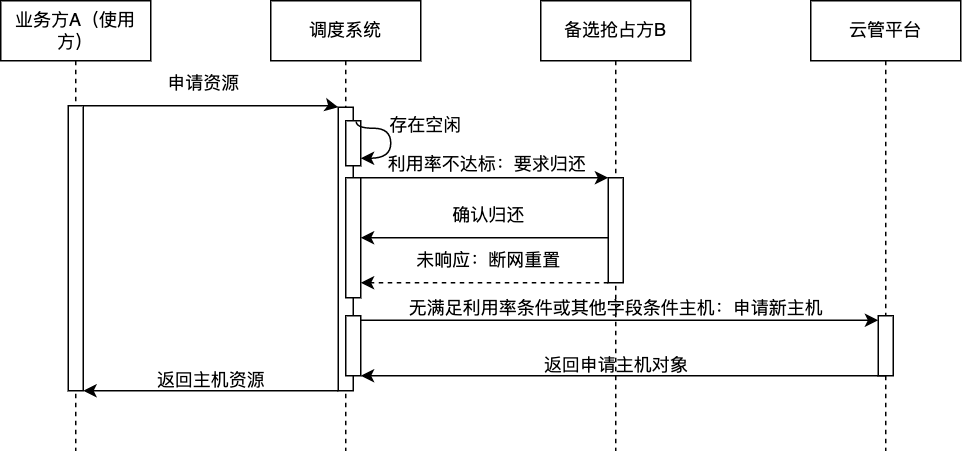
业务方需要提供详细的使用数量、规格、预计使用天数等字段,用于确认需要交付的主机列表相关细节。
发起调度
整个调度流程需要规范到一个上下文中,而调度的上下文也需要持久化存储以防出现系统崩溃重复调度的情况。交互上下文框架可以参考Kube-scheduler的runtime.Framework,捆绑所有DAO bean和筛选、排序组件。以下为伪代码,并不等同实际生产代码。
public class Framework {
private int scheduleID;
// 待调度的数据
private List<Host> candidates;
// 存放各种过滤器
private List<PreFilterPlugin> preFilterPlugins;
// 存放各种过滤器
private List<FilterPlugin> filterPlugins;
// 存放各种调度上下文结果
private List<Context> contexts;
private ScheduleContextDao scheduleContextDao;
public static Framework mkFramework(List<FilterPlugin> filterPlugins, /*其他数据数据bean等*/) {
candidates = new ArrayList<Host>();
this.filterPlugins = filterPlugins;
}
/**
* 这里只写了一个大概,表示每个调度节点都会在调度完毕后持久化
*
*/
public ScheduleStatus preFilter() {
// START 预先过滤流程
// ...
// 一系列业务代码
// ...
// END 预先过滤流程
ScheduleContext ctx = scheduleContextDao.get(scheduleID);
if (ctx == null) {
ctx = new ScheduleContext();
}
ctx.setContext(Jsons.writeAsValue(contexts));
scheduleContextDao.save(ctx);
}
public ScheduleStatus preFilter() {
// 根据原始业务字段,筛选出可以用的主机
// 若发生错误,持久化状态
}
public ScheduleStatus filter() {
// 过滤掉不可用的机器,如标记损坏等
}
public ScheduleStatus preScore() {
// 所有备选评分并排序
}
public ScheduleStatus score() {
// 排序,筛选出利用率不满足的机器
}
public ScheduleStatus permit() {
// 确认目标主机,执行抢占或开机(如需)
// 该步骤需要持久化状态
}
public ScheduleStatus bind() {
// 绑定交付状态
}
}
在调度器层面,使用待调度队列存放来自用户的请求,并逐一使用调度并持久化。这里采用SpringMVC的Service实现并使用定时任务执行。(这里同样是伪代码)。
@Service
public class Scheduler {
// 存放所有调度上下文
@Autowired
private SchedulerContextDao schedulerContextDao;
// 业务数据
@Autowired
private IdcDao idcDao;
// 其他基本辅助字段
private boolean inited;
private static Log logger = LoggerFactory.getLogger(Scheduler.class);
// 其他字段
@PostConstruct
public void init() {
// 恢复上下文,获取池化主机数据等
inited = true;
}
public boolean offer(ScheduleRequest request) {
logger.info("....");
return schedulerContextDao.offer(request);
}
// 太久没写java了,不记得定时任务是不是这个
@Schedule("* * * * * *")
public void scheduleOne() {
if (!inited) {
return;
}
ScheduleRequest pending = schedulerContextDao.listPending();
schedule(pending);
}
private void schedule(ScheduleRequest pending) {
Framework fw = Framework.mkFramework(/* 各种数据 */);
try {
ScheduleStatus preFilterStatus = fw.preFilter();
if (preFilterStatus.isEmpty()) {
// ...
return
}
ScheduleStatus filterStatus = fw.filter();
if (!filterStatus.isSuccess()) {
// 处理错误
return
}
// ...
ScheduleStatus status = fw.preScore();
if (status.isEmpty()) {
// 创建新主机
} else {
ScheduleStatus status = fw.permit();
if (status.needPreemption()) {
preemption();
return;
}
}
fw.bind();
} catch (Exception ex) {
// ...
}
}
}
筛选与排序
收到业务方请求后,根据业务方字段筛选对应门类的云主机,并筛选掉不可用的云主机,如上文伪代码中的preFilter、filter所示。如果没有则开机,绑定状态即可。随后,系统从监控系统获取各主机CPU、GPU、内存等资源的利用率快照以及其他数据源的加权数据快照进行排序。这里的步骤没有持久化,因为即便系统崩溃,重启后利用新数据排序也是可以接受的。以下为伪代码,忽略了错误处理。 其中,
-
preFilter环节用于处理过滤出可以用机器列表 -
filter环节过滤掉不满足条件的云主机 -
preScore从各个数据源获取监控指标数据并归一化 -
score进行排序,并根据排序获取所需数量云主机
其中preFilter代码类似如下:
public ScheduleStatus preFilter() {
List<Host> candidates = new ArrayList<>();
for (PreFilterPlugin pf : preFilterPlugins) {
candidates.addAll(pf.listAll());
}
// 求各路条件下的交集
this.candiates = intersection(candidates);
}
其他环节类似。
确认与抢占
调度器通过机器CPU、GPU等利用率排序后,确认一台待抢占的机器。此时调度器通过API告知使用方,10分钟之后将会强制回收并重置系统。用户方需要在规定时间内处理好自己的上下文并返回ACK。此时机器会被标记为预占用状态。
绑定与交付
确认了待交付机器ID列表后,系统通过API告知待使用的业务方机器ID等信息,流程执行完毕。
上下文持久化
调度上下文需要记录整个状态到数据库中,以保证宕机重启后状态是正确的。筛选、排序环节正确状态情况下不会持久化,错误的情况会记录错误日志。每一个状态记录如下,此处参考了kubectl get pods xxx -o yaml输出的日志数据:
[
{
"status": "False",
"createdTime": "2022-02-02T00:00:00",
"updatedTime": "2022-02-02T00:00:00",
"statusValue": "Creation",
"contextValueID": 123456,
"description": "Insufficiant host from ALIYUN",
},
{
"Status": "True",
"createdTime": "2022-02-02T00:00:00",
"updatedTime": "2022-02-02T00:00:00",
"statusValue": "Schedule.Filter",
},
{
"Status": "True",
"createdTime": "2022-02-02T00:00:00",
"updatedTime": "2022-02-02T00:00:00",
"statusValue": "Schedule.Filter",
}
]
持久化表结构大抵如下:
create table if not exists ScheduleContext (
id bigint(20) not null primary key auto_increment,
business_id char(32) not null,
amount not null int comment '所需数量',
specification_id not null comment '对应规格',
-- 一些其他的业务数据不展示
status_ char(32) not null comment 'pending, scheduling, xxx, error, success',
context varchar(255) comment 'json value context',
-- 一些审计字段
)
总结
通过这种调度方式,能够有效提升整体的云主机利用率,降低因商务规划导致的成本浪费。
