


1. 缓存简介
1.1 缓存层次管理
CPU Cache 通常会分为 L1、L2、L3 三层,其中 L1 Cache 通常分成「数据缓存」和「指令缓存」,L1是距离 CPU 最近的,因此它⽐ L2、L3 的读写速度都快、存储空间都⼩。可以通过如下命令查看CPU缓存层次:
-
- # lscpu | grep cache
- L1d cache: 32K
- L1i cache: 32K
- L2 cache: 4096K
- L3 cache: 16384K
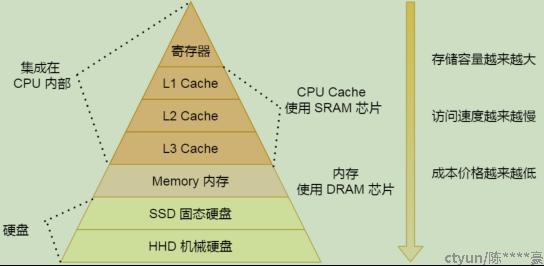
图1:存储层次图
寄存器的访问速度⾮常快,⼀般要求在半个 CPU 时钟周期内完成读写。
- L1 ⾼速缓存通常分成指令缓存和数据缓存,2-4个时钟周期; 一级缓存越大,CPU的运行效率越高,但受到CPU内部结构的限制,一级缓存的容量都很小。指令缓存与数据缓存的区别只会在L1存在。
- L2 和L1一样也是每个core独有的,只是离cpu更远,10-20个时钟周期; 主要就是做一级缓存和内存之间数据临时交换的地方用。L2缓存是同时存储指令和数据的。
- L3是多个core共享的,20-60个时钟周期内存速度⼤概在200~300 个时钟周期之间。
1.2 缓存工作方式
整个缓存空间被分成了N个line,被称为缓存行,缓存行是cache和内存交换数据的最小单位。缓存行大小可有如下命令读取:
# cat /sys/devices/system/cpu/cpu0/cache/index0/coherency_line_size64
一个缓存行包含图2中的基本信息:
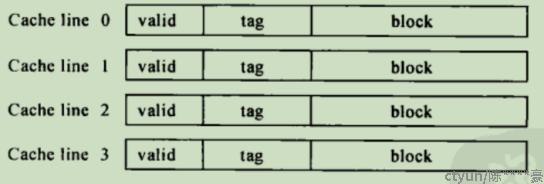
图2:缓存行信息
图中元素简介如下:
- block:存放内存在cache中缓存的数据。
- tag:存储该cache line 对应的内存块地址。
- valid:cache line中的数据是否有效。
2. 缓存的映射方式
内存空间远大于cache空间,因此内存中的数据搬到cache中时,会存在一个多对一的映射。常见的缓存的映射方式包括如下三种:
Full-associative Cache(全关联Cache)
将内存也看成按照line的方式存储。在全关联cache中,内存中每个line能够被映射到cache中的任意一个cache line。

图3:全关联示意图
全关联,判断数据是否在cache中时,它需要将地址和所有cache line的tag匹配。
Direct-mapped Cache(直接映射cache)
将内存按照cache的大小的分成了N个page,每个page和cache大小相同。page中的line0只能映射到cache中的line0,以此类推。
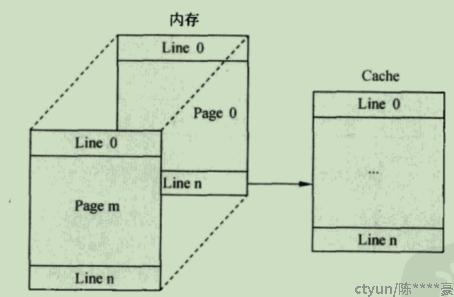
图4:直接映射示意图
优点:随便给一个地址,通过地址就知道它位于哪个cache line中,tag记录page索引。
缺点:考虑执行如下一段代码:
for (i=0;i<10;i++){
c+=a[i]+b[i]}
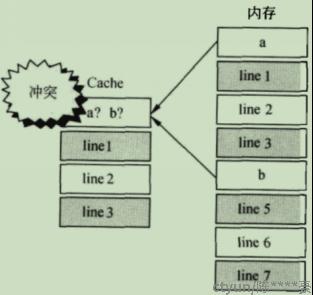
图5:cache miss示意图
当数组a和b中的元素都映射到line0时,可能发生严重的cache miss
Set-associate Cache(组关联Cache)
将cache分成了很多个way,每个way是完全相同的结构。Direct-mapped Cache等同于1-way Set associate Cache
在相同的cache容量下,cache way越多,则每个way的容量越小。way增加会减少cache miss,但way容量减少,又会增加cache miss。并且,way越多,cache的硬件结构越复杂,功耗也越高。不同处理器会根据应用设定最佳的way数和way的容量。
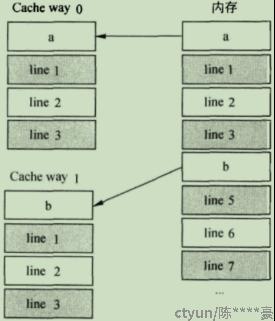
图6:组关联示意图
3. 缓存一致性
3.1 一致性底层操作
为了保证cache的一致性,处理器提供了两个保证cache一致性的底层操作:write invalidate和write update。
write invalidate:当一个core修改了一份数据,其它core上如果有该数据的缓存,则置为无效状态(invalid);该操作实现简单,尤其是其它core用不到该数据的时候,比较高效。缺点:valid标志对应一个cache line,会导致cache line中其它有效数据也无效。
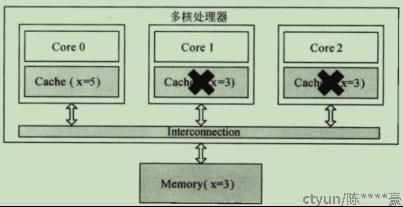
图7:write invalidate示意图
write update:当一个core修改了一份数据,其他地方如果有该数据的缓存,就都更新到最新值。会导致大量的数据更新操作,不过只用更新修改的数据。
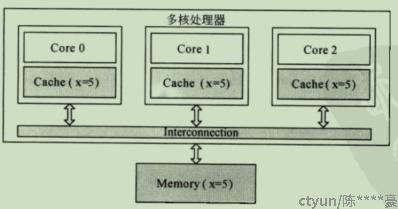
图8:write update示意图
3.2 MESI协议
3.2.1 MESI协议简介
每个cache中每个cache line有两个标志:dirty(是否被修改,内存和cache一致性)和vaild(是否有效)。
MESI是Modified、Exclusive、Shared、Invalid这四个单词的首字母。这4个字母分别代表4种状态:
|
状态 |
描述 |
监听任务 |
|
Modified (修改) |
该缓存行有效,但是该缓存数据已经被当前核心修改,此时和DRAM中数据不一致。我们将其置为M,其他的核中缓存行都会置为I。 |
监听总线上所有对该缓存行写回DRAM的操作(不希望别人写入),需要将该操作延迟到自己将缓存行写回到主存后变成S状态。 |
|
Exclusive(互斥) |
该缓存行有效,数据和RAM的数据一致,数据只存在当前内核工作内存中,只有他在使用是独占的。 |
监听总线上所有从DRAM读取该缓存行的操作,一旦有读的,需要将状态置为S状态。 |
|
Shared (共享) |
该缓存行有效,不过当前缓存行在多个核中都有,并且大家以及DRAM中的都一样。 |
监听其他的缓存中将该缓存置为I或者为E的事件,将状态置为I状态。 |
|
Invalid (无效) |
表明该缓存行无效,如果想要获取数据的话,就去DRAM中加载最新的。 |
不需要监听。 |
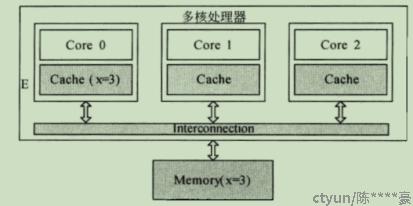
图9:Exclusive示意图

图10:Share示意图
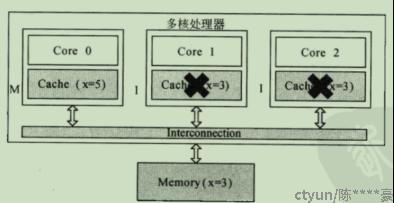
图11:Modified和Invalid示意图
在MESI协议中,每个cache的cache控制器不仅知道自己的读写操作,而且也监听其它cache的读写操作。每个cache line的状态根据本core和其它core的读写操作在4个状态间转移。
当有一个核去修改了自己的缓存行,需要同步到其他的核并更新他们的状态。所以说在MESI中每个cache控制器,不仅需要知道自己的操作,还会监听其他的cache的操作。
我们把CPU各个内核对缓存的操作可以总结为4种操作:
- local read:CPU内核读取自己的本地缓存
- local write:CPU内核写入自己的本地缓存
- remote read:其他的CPU内核读取了DRAM中当前内核的缓存行
- remote write:其他的CPU内核写入了DRAM中当前内核的缓存行
CPU内核中的缓存会监听这些事件来修改自己缓存的缓存行中的Flag标志位。然后通过该标志位来决定CPU如何处理这个缓存数据
3.2.2 MESI状态转移图
MESI状态转移图如下所示。
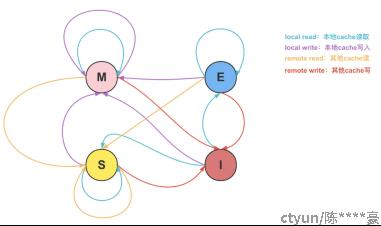
图12:MESI状态转移图
我们这里用CPU的两个核CA(coreA)和CB(coreB)以及缓存行数据 X 来解释下上面图片的转变,当CA中存在X:
状态是M(修改):此时只有CA内部有X,并且X和RAM的X值是不一致的。
|
事件 |
行为 |
下一个状态 |
|
local read |
直接从CA的cache中读,状态不发生改变 |
M |
|
local write |
直接修改CA的cache数据,状态不变 |
M |
|
remote read |
CB需要最新数据,将CA的X值写回到RAM中 |
S |
|
remote write |
先将CA的X值写回到RAM中 |
I |
状态是S(共享):此时CA和CB都有X,且和RAM的值都一致。
|
事件 |
行为 |
下一个状态 |
|
local read |
直接从CA的cache中读,状态不发生改变 |
S |
|
local write |
CA直接修改cache,状态变为M。CB变为I |
M |
|
remote read |
CB读的和CA的一样的数据,状态不变 |
S |
|
remote write |
CB对应成了上面CA的local write,CB的cache变为M,CA的变为I |
I |
状态是E(独占):此时只有CA有X,且X和RAM的X值一致(值一致代表着不需要写回RAM)
|
事件 |
行为 |
下一个状态 |
|
local read |
直接从CA的cache中读,状态不发生改变 |
E |
|
local write |
直接修改CA的cache,状态变为M |
M |
|
remote read |
CB发送读事件,CA和CB需要共享X,所以状态都变为S |
S |
|
remote write |
CA将X置为I |
I |
状态是I(失效):需要依据CB是否有X,以及响应的状态来决定操作。
|
事件 |
行为 |
下一个状态 |
|
local read |
如果CB没有X,则CA读取X,状态为E |
E or S |
|
local write |
CA需要从RAM拉取数据 |
M |
|
remote read |
已经失效,只和自己读写有关,和其他的读写无关,状态不变。 |
I |
|
remote write |
已经失效,只和自己读写有关,和其他的读写无关,状态不变。 |
I |
主要抓住几个规则:
- 当有核心读的时候,需要关注其他核心的状态是否有M的,有M的必须要先让M的写入到RAM,再读最新数据。即:当read操作需要到RAM中取时,整个CPU层面不能有该缓存行状态为M的,有的必须让其先写回到RAM中。
- 当有核心写的时候,涉及会比较多,但是核心就是:写的时候CPU层面不能有任何其他核心处于M状态,有就需要将其先写回RAM,拿到最新的数据修改,修改完成,该核心以外的核都变为失效。
- 所有的这些操作都是为保证:任何核心的修改不能被覆盖!任何核心的读取,都需要拿到当前CPU缓存层面最新的值!
