


1.控制组cgroup
1.1 cgroup子系统
cgroups 的全称是control groups,cgroups为每种可以控制的资源定义了一个子系统。典型的子系统介绍如下:
-
- cpu 子系统,主要限制进程的 cpu 使用率。
- cpuacct 子系统,可以统计 cgroups 中的进程的 cpu 使用报告。
- cpuset 子系统,可以为 cgroups 中的进程分配单独的 cpu 节点或者内存节点。
- memory 子系统,可以限制进程的 memory 使用量。
- blkio 子系统,可以限制进程的块设备 io。
- devices 子系统,可以控制进程能够访问某些设备。
- net_cls 子系统,可以标记 cgroups 中进程的网络数据包,然后可以使用 tc 模块(traffic control)对数据包进行控制。
- freezer 子系统,可以挂起或者恢复 cgroups 中的进程。
- ns 子系统,可以使不同 cgroups 下面的进程使用不同的 namespace。
这里面每一个子系统都需要与内核的其他模块配合来完成资源的控制,比如对 cpu 资源的限制是通过进程调度模块根据 cpu 子系统的配置来完成的;对内存资源的限制则是内存模块根据 memory 子系统的配置来完成的,而对网络数据包的控制则需要 Traffic Control 子系统来配合完成。本文不会讨论内核是如何使用每一个子系统来实现资源的限制,而是重点放在内核是如何把 cgroups 对资源进行限制的配置有效的组织起来的,和内核如何把cgroups 配置和进程进行关联的,以及内核是如何通过 cgroups 文件系统把cgroups的功能暴露给用户态的。
1.2 cgroups 层级结构
内核使用 cgroup 结构体来表示一个 control group 对某一个或者某几个 cgroups 子系统的资源限制。
cgroup 结构体可以组织成一颗树的形式,每一棵cgroup 结构体组成的树称之为一个 cgroups 层级结构。
cgroups层级结构可以 attach 一个或者几个 cgroups 子系统,当前层级结构可以对其 attach 的 cgroups 子系统进行资源的限制。每一个 cgroups 子系统只能被 attach 到一个 cpu 层级结构中。
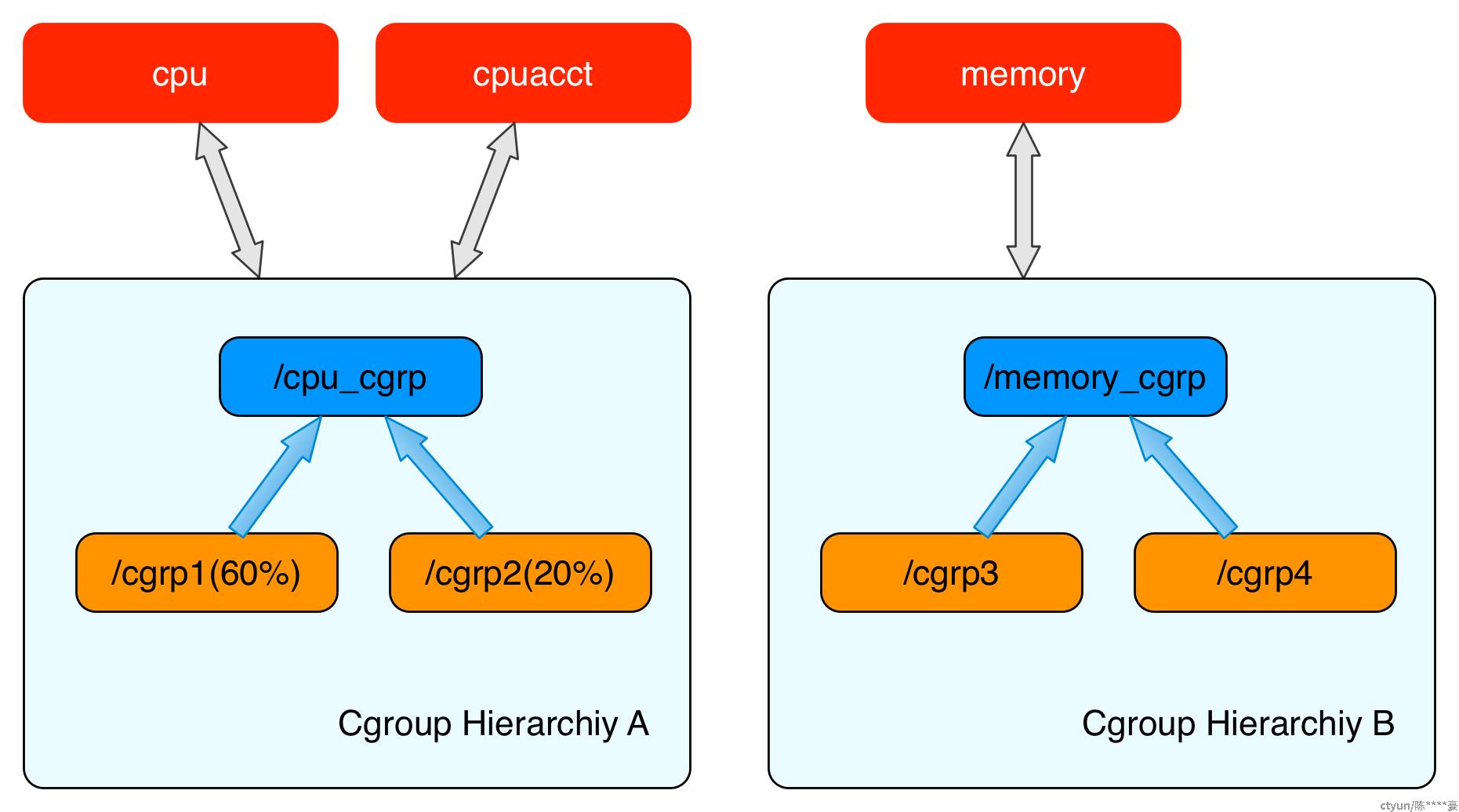
比如上图表示两个cgroups层级结构,每一个层级结构中是一颗树形结构,树的每一个节点是一个 cgroup 结构体(比如cpu_cgrp, memory_cgrp)。第一个 cgroups 层级结构 attach 了 cpu 子系统和 cpuacct 子系统, 当前 cgroups 层级结构中的 cgroup 结构体就可以对 cpu 的资源进行限制,并且对进程的 cpu 使用情况进行统计。 第二个 cgroups 层级结构 attach 了 memory 子系统,当前 cgroups 层级结构中的 cgroup 结构体就可以对 memory 的资源进行限制。
在每一个 cgroups 层级结构中,每一个节点(cgroup 结构体)可以设置对资源不同的限制权重。比如上图中 cgrp1 组中的进程可以使用60%的 cpu 时间片,而 cgrp2 组中的进程可以使用20%的 cpu 时间片。
1.3 cgroups与进程
上面的小节提到了内核使用 cgroups 子系统对系统的资源进行限制,也提到了 cgroups 子系统需要 attach 到 cgroups 层级结构中来对进程进行资源控制。本小节重点关注一下内核是如何把进程与 cgroups 层级结构联系起来的。
在创建了 cgroups 层级结构中的节点(cgroup 结构体)之后,可以把进程加入到某一个节点的控制任务列表中,一个节点的控制列表中的所有进程都会受到当前节点的资源限制。同时某一个进程也可以被加入到不同的 cgroups 层级结构的节点中,因为不同的 cgroups 层级结构可以负责不同的系统资源。所以说进程和 cgroup 结构体是一个多对多的关系。
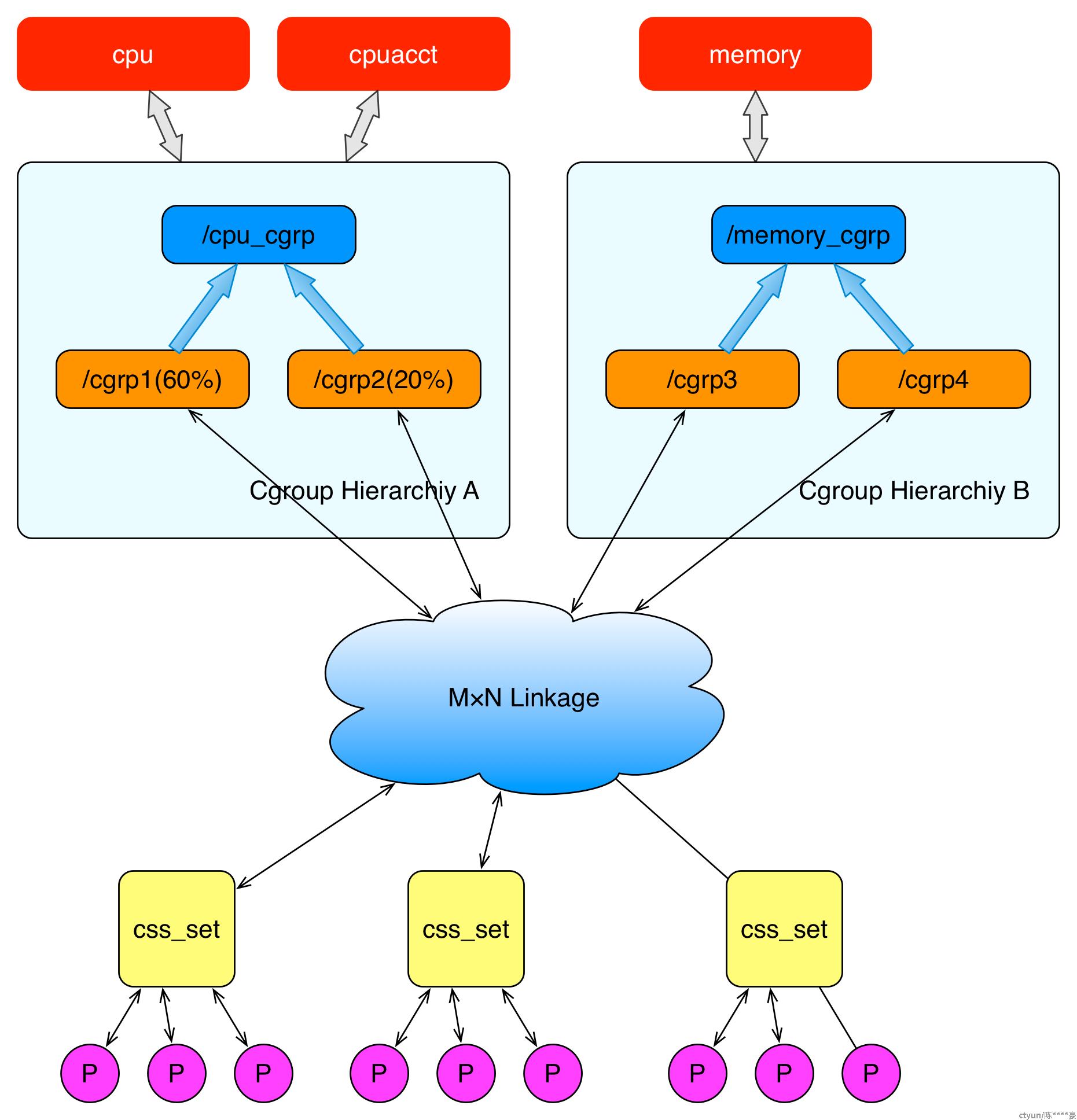
上面这个图从整体结构上描述了进程与 cgroups 之间的关系。最下面的P代表一个进程。每一个进程的描述符中有一个指针指向了一个辅助数据结构css_set(cgroups subsystem set)。 指向某一个css_set的进程会被加入到当前css_set的进程链表中。一个进程只能隶属于一个css_set,一个css_set可以包含多个进程,隶属于同一css_set的进程受到同一个css_set所关联的资源限制。
上图中的”M×N Linkage”说明的是css_set通过辅助数据结构可以与 cgroups 节点进行多对多的关联。但是 cgroups 的实现不允许css_set同时关联同一个cgroups层级结构下多个节点。 这是因为 cgroups 对同一种资源不允许有多个限制配置。
一个css_set关联多个 cgroups 层级结构的节点时,表明需要对当前css_set下的进程进行多种资源的控制。而一个 cgroups 节点关联多个css_set时,表明多个css_set下的进程列表受到同一份资源的相同限制。
系统中的每个进程都属于一个 cgroup,一个进程的所有线程都属于同一个 cgroup。一个进程可以从一个 cgroup 迁移到另一个 cgroup 。进程的迁移不会影响现有的后代进程所属的 cgroup。
1.4 资源约束

如图所示,cgroup1 中限制了使用 cpu 及 内存资源,它将控制子节点的 CPU 周期和内存分配(即,限制 cgroup2、cgroup3、cgroup4 中的cpu及内存资源分配)。cgroup2 中启用了内存限制,但是没有启用cpu的资源限制,这就导致了 cgroup3 和 cgroup4 的内存资源受 cgroup2中的 mem 设置内容的限制;cgroup3 和 cgroup4 会自由竞争在 cgroup1 的 cpu 资源限制范围内的 cpu 资源。
由此,也可以明显的看出 cgroup 资源是自上而下分布约束的。只有当资源已经从上游 cgroup 节点分发给下游时,下游的 cgroup 才能进一步分发约束资源。
子节点 cgroup 与父节点 cgroup 是否会存在内部进程竞争的情况呢?
当然不会。cgroup v2 中,设定了非根 cgroup 只能在没有任何进程时才能将域资源分发给子节点的 cgroup。简而言之,只有不包含任何进程的 cgroup 才能在其 cgroup.subtree_control 文件中启用域控制器,这就保证了,进程总在叶子节点上。
1.5 资源分配模型及功能
cgroups 的资源分配模型:
-
- 权重 - (例如,cpu.weight) 所有权重都在 [1, 10000] 范围内,默认值为 100。按照权重比率来分配资源。
- 限制 - [0, max] 范围内,默认为“max”,即 noop(例如,io.max)。限制可以被过度使用(子节点限制的总和可能超过父节点可用的资源量)。
- 保护 - [0, max] 范围内,默认为 0,即 noop(例如,io.low)。保护可以是硬保证或尽力而为的软边界,保护也可能被过度使用。
- 分配 - [0, max] 范围内,默认为 0,即没有资源。分配不能被过度使用(子节点分配的总和不能超过父节点可用的资源量)。
cgroups 提供了如下功能:
-
- 资源限制 - 上面 cgroup 部分已经示例,cgroups 可以以树状结构来嵌套式限制资源。
- 优先级 - 发生资源争用时,优先保障哪些进程的资源。
- 审计 - 监控及报告资源限制及使用。
- 控制 - 控制进程的状态(起、停、挂起)。
2.namespace
2.1 namespace简介
namespace 是 Linux 内核用来隔离内核资源的方式。通过 namespace 可以让一些进程只能看到与自己相关的一部分资源,而另外一些进程也只能看到与它们自己相关的资源,这两拨进程根本就感觉不到对方的存在。具体的实现方式是把一个或多个进程的相关资源指定在同一个 namespace 中。
Linux namespaces 是对全局系统资源的一种封装隔离,使得处于不同 namespace 的进程拥有独立的全局系统资源,改变一个 namespace 中的系统资源只会影响当前 namespace 里的进程,对其他 namespace 中的进程没有影响。
实际上,Linux 内核实现 namespace 的一个主要目的就是实现轻量级虚拟化(容器)服务。在同一个 namespace 下的进程可以感知彼此的变化,而对外界的进程一无所知。这样就可以让容器中的进程产生错觉,认为自己置身于一个独立的系统中,从而达到隔离的目的。也就是说 linux 内核提供的 namespace 技术为 docker 等容器技术的出现和发展提供了基础条件。
2.2 六大隔离机制
目前Linux中提供了六类系统资源的隔离机制,分别是:
-
- Mount: 隔离文件系统挂载点
- UTS: 隔离主机名和域名信息
- IPC: 隔离进程间通信
- PID: 隔离进程的ID
- Network: 隔离网络资源
- User: 隔离用户和用户组的ID
/proc/[pid]/ns 目录下会包含进程所属的 namespace 信息,使用下面的命令可以查看当前进程所属的 namespace 信息:
[root@yuhao-dev-machine electr]# ll /proc/$$/ns
total 0
lrwxrwxrwx 1 root root 0 Sep 5 11:31 ipc -> ipc:[4026531839]
lrwxrwxrwx 1 root root 0 Sep 5 11:31 mnt -> mnt:[4026531840]
lrwxrwxrwx 1 root root 0 Sep 5 11:31 net -> net:[4026531956]
lrwxrwxrwx 1 root root 0 Sep 5 11:31 pid -> pid:[4026531836]
lrwxrwxrwx 1 root root 0 Sep 5 11:31 user -> user:[4026531837]
lrwxrwxrwx 1 root root 0 Sep 5 11:31 uts -> uts:[4026531838]六种 namespace 正是实现容器必须的隔离技术.
综上所述,对于容器技术而言,它实现资源层面上的限制和隔离,依赖于 Linux 内核所提供的 cgroup 和 namespace 技术:
-
- cgroup 的主要作用:管理资源的分配、限制;
- namespace 的主要作用:封装抽象,限制,隔离,使命名空间内的进程看起来拥有他们自己的全局资源;
