


背景说明
今天,上云已经成为常态,不论是公有云还是私有云,云的用户更多是讨论如何更好的上云和用云。近两年,一云多芯正成为一个新常态,这其中包含诸多驱动因素。从广义的视角来看,CPU、GPU、DPU都是属于面向特定场景的芯片,都属于多芯的范畴。本文将着重谈一谈CPU的一云多芯。
为什么要采用不同架构CPU芯片?从全球来看,ARM架构CPU的自主演进、低功耗、多核能力带来的成本效应使得各大云服务商都开始自研ARM芯片,并上线ARM架构云服务。对于国内云服务市场而言,除了上述的原因,还有极强的关键技术国产化诉求驱使我们采用鲲鹏、飞腾、海光、龙芯、申威、兆芯等多种不同架构的芯片。
从不同的云部署形态来看,公有云和私有云在一云多芯的采用上具有不同的实现方式和意义。
- 公有云
- 高度的厂商自主性
- 固化配置、批量采购
- 标准化实例(性能、SLA等)
- 私有云
- 高度的客户自主性(自采硬件、区域属性)
- 配置选型、缺乏标准和指导算力多元化(也许未来某一天会统一到某一两个架构上)
- 多芯基础设施的管理较难
因此,一云多芯的复杂度更多的体现在私有云上。这其中涉及到一个重要的问题就是多芯的异构混部。
异构混部的现实意义
私有云客户在采用多芯架构上云的过程中,不可能一蹴而就。异构的CPU芯片具有的不同指令集使得现有应用需要经过改造、重新编译后才能运行在新的架构之上。这个过程通常是繁琐冗长的,且需要耗费不菲的成本。因此,私有云的客户通常会从以下角度考虑上云的策略:
- 稳定性考虑:新业务上新架构,老业务不动后者渐进式上新架构的路线。
- 成本考虑:在有限的成本范围内,先将一部分业务上新架构
- 技术限制:部分无法改造或者有特定性能需求的应用只能继续运行在老的Intel架构
以上三个方面的因素,导致必然会存在X86(Intel)、ARM(或其他)等两种以上异构CPU硬件并存的情况。而对于云平台的软件来说,也就带来了异构混部的问题。
多层次异构混部及负载调度
从云平台和云产品部署的维度看,需要从Region、AZ可用区、再到集群以及节点等维度来支持服务的混部。Region是非常容易支持的(参考,比如Region-1是Intel,Region-2是鲲鹏),AZ级别也不难,但是到了集群和节点粒度就变得相对复杂。比如管控是A架构,但是服务集群则是A、B、C架构,更进一步的会有一个集群内A、B架构共存情形,此时就需要依靠一些负载调度的能力,来均衡不同架构性能差异问题。
平台服务混合部署
下图所示,这是一种典型平台服务混部的模式。
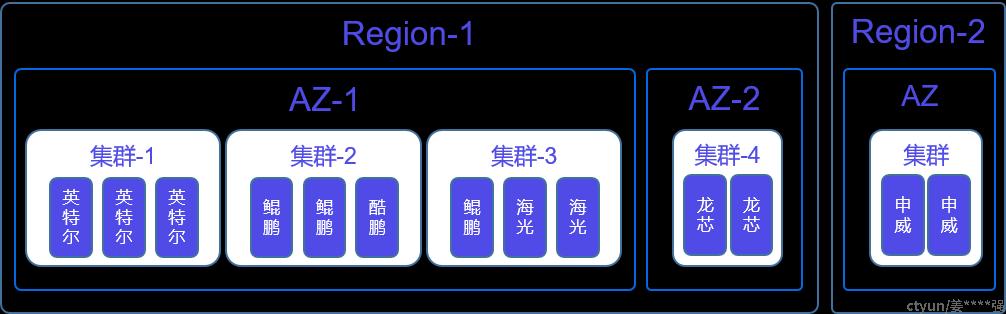
简要说明如下:
同一套管控(A架构),服务集群则可能为A、B、C等多种架构
- A架构网元同时支持A、B等多种架构
- 同架构不同代系(Intel 7代和8代CPU)
- 同类型服务集群内部存在异构节点的混部:比如一个存储集群中既有Intel又有ARM架构的机器。此场景下,通常需要进行负载调度,保证性能的稳定性。
业务应用混合部署
用户应用层面,会存在客户将一套系统跨异构资源部署的情况。由于云平台本身做到了的网络和存储协议的标准化和一致性,是底层架构无关的。因此依靠SDN、负载均衡、流量网关以及数据同步等手段,可以保证这种异构混部应用系统能够整体协同,平稳运转。
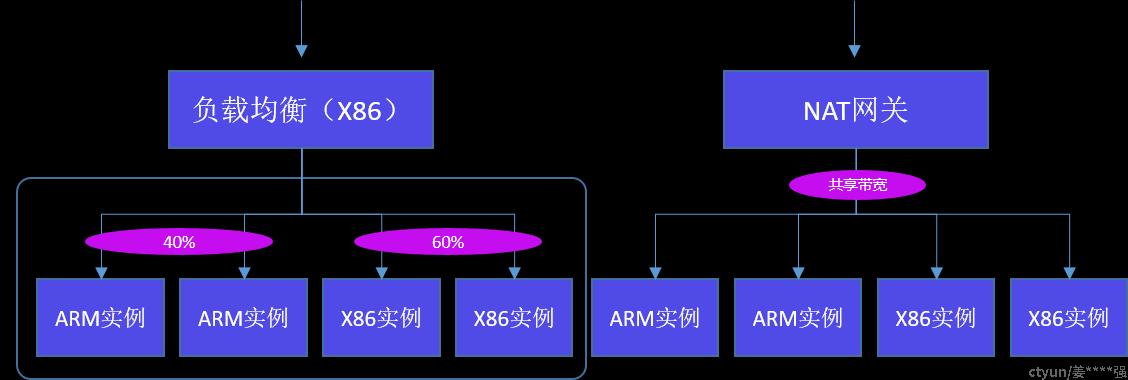
左图的部署架构,不同实例上部署应用处于同一个VPC内部,可以通过负载均衡进行整体的负载调度,保证性能更好的实例承担更高比重的负载。右图的部署架构,不同实例上部署应用处于同一个VPC内部,可以通过NAT网关实现流量的共享(NAT网关可以是其中的一种架构)。
后记
此文是作者在信通院“2023一云多芯云管实践专场”上分享的部分内容的文字总结,特此在内网分享。
