


前言
velero是一个开源的K8S集群备份还原组件,作为一个容灾与集群应用迁移的方案,已被阿里、华为和腾讯等多家共有云厂商使用。
下面先跟相似方案对比,再介绍velero简单安装,CRD及成员结构。接着分别基于备份和还原两个使用场景,从命令执行、组件交互、源码分析这几个层次进行介绍
VS Etcd备份
相比起Etcd备份,velero的备份与恢复粒度更细更灵活。
- - Etcd备份是基于快照,由于集群中所有资源定义都存储在Etcd中,故恢复Etcd只能把整体状态恢复到某一时间点;
- - velero备份是通过apiserver读出集群中资源的信息,在读取时可对资源进行筛选,导入时也可以对资源的ns进行更替,实现应用迁移的效果。
velero备份的范围更广
- - Etcd备份仅能备份恢复存储在Etcd中的数据,而持久化数据(如PV)不纳入其中;
- - velero通过restic组件可对大部分存储卷的数据进行备份。
恢复方式的差异
- - Etcd是快照恢复,所以备份点之后的操作的数据都会丢失;
- - velero是追加式的恢复,因此只会往现有的基础上在加入备份时拥有的数据,对备份后增加的数据,或者修改的数据,velero是不会删除或覆盖的。
安装部署
备份信息需要持久化存储,存放在OSS中,在开发环境可以搭个minio。接着才安装velero。两者都通过helm-chart的方式
helm repo add c7n https://openchart.choerodon.com.cn/choerodon/c7n/helm repo update# 输出安装参数文件echo 'mode: standaloneaccessKey: "minio"secretKey: "minio123"persistence: enabled: falseingress: enabled: false service: type: NodePort '>>minio.yamlhelm upgrade --install minio c7n/minio \ -f minio.yaml \ --version 5.0.5 \ --namespace minio安装完minio后登录web端页面添加一个名为velero的bucket。接着安装velero
```
wget https://github.com/vmware-tanzu/velero/releases/download/v1.7.1/velero-v1.7.1-linux-amd64.tar.gz# 解压tar -C /usr/local/bin -xzvf velero-v1.7.1-linux-amd64.tar.gz# 添加到环境变量中去export PATH=$PATH:/usr/local/bin/velero-v1.7.1-linux-amd64/# 测试是否安装成功了velero -h# 创建minio凭证(credentials-velero文件)echo '[default]aws_access_key_id = minioaws_secret_access_key = minio123' >>credentials-velerovelero install \ --provider aws \ --plugins velero/velero-plugin-for-aws:v1.0.0 \ --bucket velero \ --secret-file ./credentials-velero \ --use-volume-snapshots=false \ # 在本地群集中运行,而没有能够提供快照的卷提供程序,因此不会VolumeSnapshotLocation创建 --use-restic \ # 启用Restic支持 --backup-location-config region=minio,s3ForcePathStyle="true",s3Url=http://{填写minio的svc地址}:9000```
相关CRD
安装时会出现一大堆CRD,这是velero曾经被诟病的原因之一,所用CRD如下所示
```
CustomResourceDefinition/backups.velero.io CustomResourceDefinition/backupstoragelocations.velero.io CustomResourceDefinition/deletebackuprequests.velero.io CustomResourceDefinition/downloadrequests.velero.io CustomResourceDefinition/podvolumebackups.velero.io CustomResourceDefinition/podvolumerestores.velero.io CustomResourceDefinition/resticrepositories.velero.io CustomResourceDefinition/restores.velero.io CustomResourceDefinition/schedules.velero.io CustomResourceDefinition/serverstatusrequests.velero.io CustomResourceDefinition/volumesnapshotlocations.velero.io ```
盖备份还原过程中需要有地方记录其中间数据和状态,velero不依赖关系型数据库,故定义CRD来将存储之;再者部分配置信息也需要存储,如备份的存储路径backupstoragelocations。
CRD虽多,大体可分一下几个类型
主要功能方面
- - backups.velero.io:用于实现单次备份功能
- - restores.velero.io:用于实现还原功能
- - schedules.velero.io:用于实现定时备份功能
以上几个CR一旦定义,对应的controller就会执行响应的功能操作
配置方面
backupstoragelocations.velero.io:用于存储velero存储备份数据时所依赖的的OSS信息
pv存储方面
- - podvolumebackups.velero.io: 存储各个pod所挂载的存储卷信息,在备份时会产生,产生后对应资源的controller会调用restic相关命令去备份pv数据,有记录volume在restic的repo与snapshot信息
- - podvolumerestores.velero.io: 功能与作用与上面的类似,对应的controller会调用restic相关命令去恢复pv数据
- - resticrepositories.velero.io: 存储restic的repo信息,一个pod为一个repo
- - volumesnapshotlocations.velero.io: 存储存储卷的快照信息(没实践过,不太了解)
对备份信息操作方面
- - deletebackuprequests.velero.io:定义了此CR,CR对应的controller会将CR中指定的备份信息删除,CR也作为记录参数操作之用
- - downloadrequests.velero.io:定义了此CR,CR对应的controller会将给CR中指定的备份信息生成下载URL,存储回CR中,供CR创建方获取地址发起下载请求
成员结构
安装完成时看到velero命名空间下有两个工作负载,一个是deployment/velero,另一个是daemonset/restic
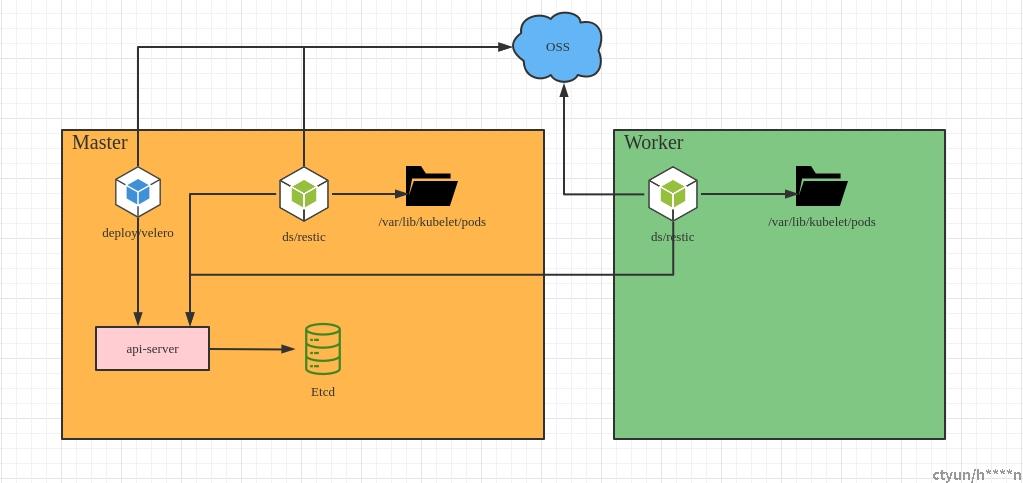
- - deployment/velero:主要运行backup,restore,sechdule,deleteBackupRequests,resticRepo这几个controller,用于执行单次和周期备份,恢复,restic的repo创建等操作
- - daemonset/restic:运行podvolumebackup和podvolumerestore的controller,用于处理同节点pod的pv备份和恢复操作,备份和恢复都依赖了restic组件
(两种工作负载共享oss的credentials,pv备份还原时由velero的repoController到调用restic到oss中创建repo,供ds的restic往repo中读写snapshot)
备份操作
现在集群中有test-ns-b命名空间,在里面创建了一个deploy/busybox的工作负载,挂载了一个pvc,该pvc绑定了本地的存储卷testPV2,存储卷中有两个文件1.txt和2.txt,现在使用velero对这个ns进行备份,备份的内容就包括这个ns,deploy,pvc,pv这几种资源,以及pv里面的两个文件。
相关命令
```
velero backup create demo-backup --include-namespaces=test-ns-b --default-volumes-to-restic=trueBackup request "demo-backup" submitted successfully.Run `velero backup describe demo-backup` or `velero backup logs demo-backup` for more details.```
执行完毕后,可以通过`velero backup describe demo-backup`查看备份的详情,以及通过`velero backup logs demo-backup`查看备份过程的日志信息
各组件交互流程
上述velero命令执行完毕后,就会创建一个Backup CR,然后开始执行备份流程,一个yaml示例如下(并非与上面创建的一致)
```yaml
apiVersion: velero.io/v1kind: Backupmetadata: name: migrate-backup # 必须得是 velero 安装的命名空间 namespace: velerospec: # 仅包含 nginx-example 命名空间的资源 includedNamespaces: - nginx-example # 包含不区分命名空间的资源 includeClusterResources: true # 备份数据存储位置指定 storageLocation: default # 卷快照存储位置指定 volumeSnapshotLocations: - default # 使用 restic 备份卷 defaultVolumesToRestic: true```
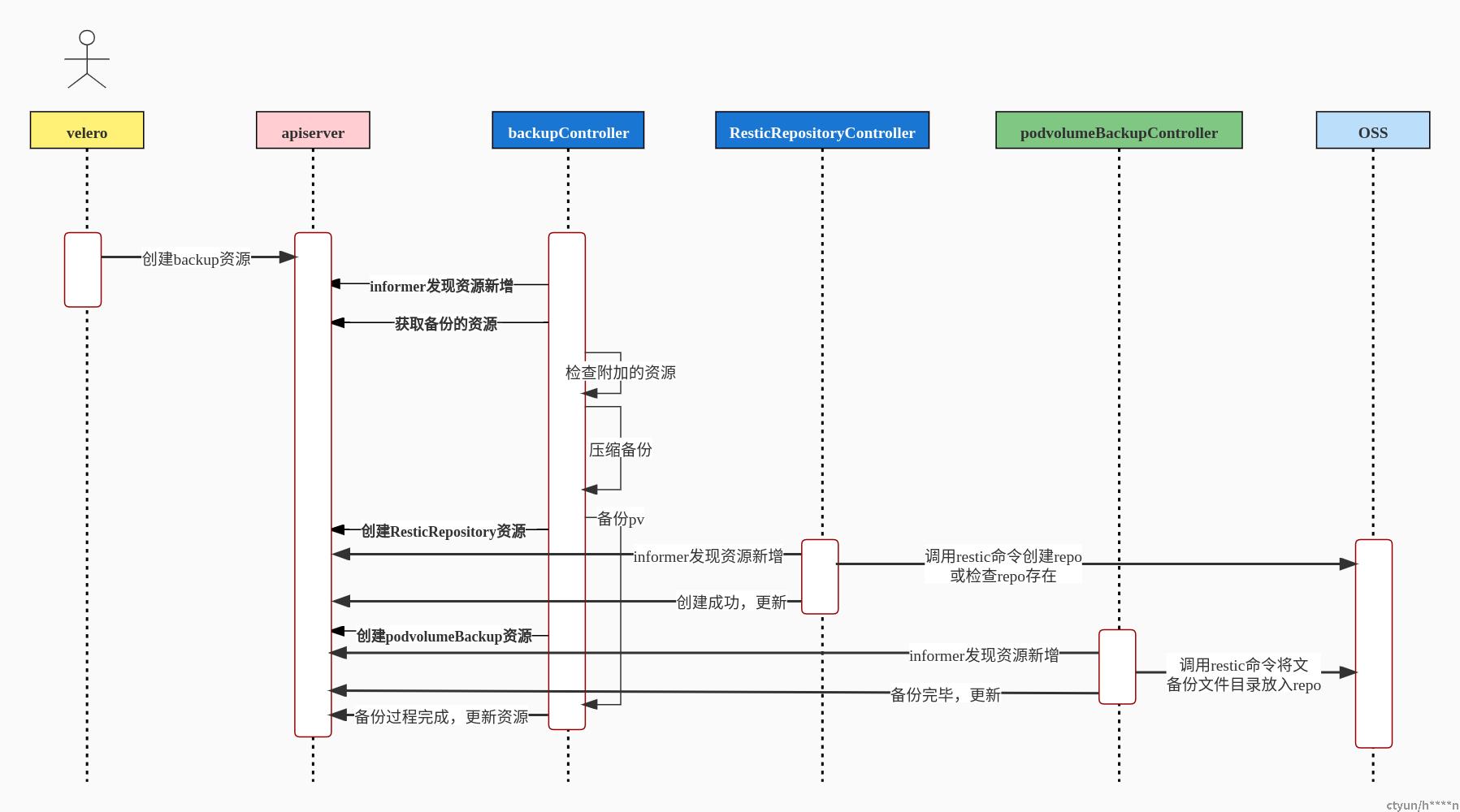
下图则是几个组件的交互流程,其中蓝色方框的两个controller属于deploy/velero工作负载中的,绿色方框的controller属于daemonset/restic工作负载中
相关源码分析
从backupcontroller的处理逻辑processBackup方法开始,调用关键的调用链如下,
```shell
backupController.processBackup // /pkg/controller/backup_controller.go|--c.runBackup |--c.backupper.BackupWithResolvers // /pkg/backup/backup.go | |--items := collector.getAllItems() | |--kb.backupItem //wrapper | | |--itemBackupper.backupItem // /pkg/backup/item_backuper.go | | |--ib.executeActions | | |--ib.takePVSnapshot | | |--ib.backupPodVolumes | | |--ib.tarWriter.WriteHeader(hdr) | | |--ib.tarWriter.Write(itemBytes) | |--kb.backupCRD |--persistBackup```
backupController.processBackup是backupController从workqueue中取出变更资源的key后调用的处理方法,常规的包含将key转成对应资源对象,赋默认值更新等,经过两层调用到达kubernetesBackupper.BackupWithResolvers,即调用链中的c.backupper.BackupWithResolvers。在这方法中调用collector.getAllItems()获取所有需要备份的资源信息,该信息包含资源的ns,name,gvr,序列化后的临时存放地址等。然后经过一个循环递归将每个资源调用kb.backupItem进行压缩存储,压缩存储好各个资源的数据调用kb.backupCRD检查该资源是不是CRD的CR,如果是则要对CRD也一块备份。最后将压缩好的备份数据调用persistBackup持久化存储。
下面则挑出几个关键方法的源码看看
collector.getAllItems()
collector.getAllItems()是itemCollector的方法,他的作用是获取集群中所有类型的资源,代码如下
// 代码位于/pkg/bakcup/item_collector.go
```golang
func (r *itemCollector) getAllItems() []*kubernetesResource {var resources []*kubernetesResource//获取apiresource 并遍历 集合中每个元素即apiGroupfor _, group := range r.discoveryHelper.Resources() {groupItems, err := r.getGroupItems(r.log, group)if err != nil {r.log.WithError(err).WithField("apiGroup", group.String()).Error("Error collecting resources from API group")continue}resources = append(resources, groupItems...)}return resources}```
先通过client-go的discoveryClient获取集群中的各个apiGroup,遍历时调用r.getGroupItems拿到每个apiGroup中有多少种资源类型,再针对每个资源类型调用client获取资源实例,存放到kubernetesResource对象中,r.getGroupItems代码如下
```golang
func (r *itemCollector) getGroupItems(log logrus.FieldLogger, group *metav1.APIResourceList) ([]*kubernetesResource, error) {gv, err := schema.ParseGroupVersion(group.GroupVersion)//遇着core group就按pod,pvc,pv来对apiGroup中的kind排序if gv.Group == "" {sortCoreGroup(group)}var items []*kubernetesResource//遍历每个apiGroup里面的每种gvk,获取其每个资源,序列化并写到文件目录中去//返回的是kubernetesResource类型的值,字段包含资源的name,ns,gvr,序列化文件的路径for _, resource := range group.APIResources {resourceItems, err := r.getResourceItems(log, gv, resource)if err != nil {log.WithError(err).WithField("resource", resource.String()).Error("Error getting items for resource")continue}items = append(items, resourceItems...)}return items, nil}```
for循环中则是遍历apiGroup中的资源类型,通过资源类型获取资源实例的代码在r.getResourceItems中,代码如下
```golang
func (r *itemCollector) getResourceItems(...){var (gvr = gv.WithResource(resource.Name)gr = gvr.GroupResource()clusterScoped = !resource.Namespaced)if gr == kuberesource.Namespaces && namespacesToList[0] != "" {resourceClient, err := r.dynamicFactory.ClientForGroupVersionResource(gv, resource, "")for _, ns := range namespacesToList {unstructured, err := resourceClient.Get(ns, metav1.GetOptions{})path, err := r.writeToFile(unstructured)items = append(items, &kubernetesResource{groupResource: gr,preferredGVR: preferredGVR,name: ns,path: path,})}}}```
代码只展示了对ns资源的处理,其他类型的资源处理方式相似都是通过dynamicFactory获取这种资源的client,是client-go的dynamicClient,获取出资源实例是unstructured结构,然后序列化成json存储到临时文件中,相关信息都转成kubernetesResource。
collector.getAllItems()方法就是这样把要备份的资源都收集了。
itemBackupper.backupItem()
itemBackupper.backupItem()是itemBackupper的方法,他负责对要备份的资源压缩存储,同时对一些特定的类型的资源附加处理,代码如下
//代码位于 /pkg/backup/item_backuper.go
```golang
func (ib *itemBackupper) backupItem(...){updatedObj, err := ib.executeActions(log, obj, groupResource, name, namespace, metadata)if groupResource == kuberesource.Pods {for _, volume := range restic.GetPodVolumesUsingRestic(pod, boolptr.IsSetToTrue(ib.backupRequest.Spec.DefaultVolumesToRestic)) {if found, pvcName := ib.resticSnapshotTracker.HasPVCForPodVolume(pod, volume); found {continue}resticVolumesToBackup = append(resticVolumesToBackup, volume)}ib.resticSnapshotTracker.Track(pod, resticVolumesToBackup)}}if groupResource == kuberesource.PersistentVolumes {if err := ib.takePVSnapshot(obj, log); err != nil {backupErrs = append(backupErrs, err)}}if groupResource == kuberesource.Pods && pod != nil {podVolumeBackups, errs := ib.backupPodVolumes(log, pod, resticVolumesToBackup)}if namespace != "" {filePath = filepath.Join(velerov1api.ResourcesDir, groupResource.String(), versionPath, velerov1api.NamespaceScopedDir, namespace, name+".json")} else {filePath = filepath.Join(velerov1api.ResourcesDir, groupResource.String(), versionPath, velerov1api.ClusterScopedDir, name+".json")}itemBytes, err := json.Marshal(obj.UnstructuredContent())if err != nil {return false, errors.WithStack(err)}hdr := &tar.Header{Name: filePath,Size: int64(len(itemBytes)),Typeflag: tar.TypeReg,Mode: 0755,ModTime: time.Now(),}if err := ib.tarWriter.WriteHeader(hdr); err != nil {return false, errors.WithStack(err)}if _, err := ib.tarWriter.Write(itemBytes); err != nil {return false, errors.WithStack(err)}}```
ib.executeActions获取此资源的附加、或关联的资源实例,如pod就会拿pvc信息,再临时取出pvc信息调用ib.backupItem。一些引用的、依赖的资源通过这种方式带出来,以防漏掉,pod与pvc是一种,pvc与pv是一种,sa与role,rolebinding也是。代码如下
```golang
func (ib *itemBackupper) executeActions(...){for _, action := range ib.backupRequest.ResolvedActions {if !action.ShouldUse(groupResource, namespace, metadata, log) {continue}updatedItem, additionalItemIdentifiers, err := action.Execute(obj, ib.backupRequest.Backup)for _, additionalItem := range additionalItemIdentifiers {gvr, resource, err := ib.discoveryHelper.ResourceFor(additionalItem.GroupResource.WithVersion(""))client, err := ib.dynamicFactory.ClientForGroupVersionResource(gvr.GroupVersion(), resource, additionalItem.Namespace)item, err := client.Get(additionalItem.Name, metav1.GetOptions{})if _, err = ib.backupItem(log, item, gvr.GroupResource(), gvr); err != nil {return nil, err}}}}```
这些action都是实现了BackupItemAction接口的实现类,目前这些类有podAction,pvcAction,serviceAccountAction等,每个ation都会先调用ShouldUse方法校验当前资源是否是当前action适合处理的,是才往下走,action拿到关联或依赖的资源后,同样通过dynamicClient获取到资源实例,调用ib.backupItem。这种算是确保依赖资源同样也得到备份的一种保障机制
执行完executeActions,就会判断当前处理的资源是不是pv,是就尝试对其做个pv快照,但是前提是velero要开启了volume-snapshots才行,也会判断当前资源如果是pod,就会检查里面有否用到volume且是restic支持备份的类型,如果是则让restic对volume的内容进行备份,
ib.backupPodVolumes
ib.backupPodVolumes经过两层调用到达backupper的BackupPodVolumes方法,代码如下
// 代码位于/pkg/restic/backupper.go
```golang
func (b *backupper) BackupPodVolumes(...){repo, err := b.repoEnsurer.EnsureRepo(b.ctx, backup.Namespace, pod.Namespace, backup.Spec.StorageLocation)for _, volumeName := range volumesToBackup {if volume.PersistentVolumeClaim != nil {pvc, err = b.pvcClient.PersistentVolumeClaims(pod.Namespace).Get(context.TODO(), volume.PersistentVolumeClaim.ClaimName, metav1.GetOptions{})}isHostPath, err := isHostPathVolume(&volume, pvc, b.pvClient.PersistentVolumes())if isHostPath {log.Warnf("Volume %s in pod %s/%s is a hostPath volume which is not supported for restic backup, skipping", volumeName, pod.Namespace, pod.Name)continue}volumeBackup := newPodVolumeBackup(backup, pod, volume, repo.Spec.ResticIdentifier, pvc)if volumeBackup, err = b.repoManager.veleroClient.VeleroV1().PodVolumeBackups(volumeBackup.Namespace).Create(context.TODO(), volumeBackup, metav1.CreateOptions{}); err != nil {errs = append(errs, err)continue}numVolumeSnapshots++}ForEachVolume:for i, count := 0, numVolumeSnapshots; i < count; i++ {select {case <-b.ctx.Done():errs = append(errs, errors.New("timed out waiting for all PodVolumeBackups to complete"))break ForEachVolumecase res := <-resultsChan:switch res.Status.Phase {case velerov1api.PodVolumeBackupPhaseCompleted:podVolumeBackups = append(podVolumeBackups, res)case velerov1api.PodVolumeBackupPhaseFailed:errs = append(errs, errors.Errorf("pod volume backup failed: %s", res.Status.Message))podVolumeBackups = append(podVolumeBackups, res)}}}}```
先确保restic的repo是可用的,然后再去判定当前volume是否属于restic支持范围内,如果是hostPath的volum,或者Volume资源是用了hostPath的都是不支持的。确认是能备份之后,就会创建一个PodVolumeBackups的CR,调用客户端创建资源,具体的备份操作由PodVolumeBackup controller去实现,会调用restic的命令将目录backup到repo中,代码不在这里展开细说;同样前面的repo确保可用的也是同样方式,创建了ResticRepository的CR,调用客户端创建资源,具体restic创建命令调用由ResticRepository执行,这正是veleor创建了如此多CRD,如此多controller的原因,让各个controller分工明细,各自管好各自的资源,各自负责好各自的事情。
kb.backupCRD
当kb.backupItem执行成功之后,会把备份资源的gr记录起来,后面会根据这些已备份的资源检查他们是否是CRD,如果是就要对CRD也要执行备份,代码如下
```golang
func (kb *kubernetesBackupper) backupCRD(...){//先拿crd的客户端gvr, apiResource, err := kb.discoveryHelper.ResourceFor(crdGroupResource.WithVersion(""))crdClient, err := kb.dynamicFactory.ClientForGroupVersionResource(gvr.GroupVersion(), apiResource, "")//检查crd列表中是否有当前资源的gr,拿不到则表明不是CRD,就可以返回unstructured, err := crdClient.Get(gr.String(), metav1.GetOptions{})if apierrors.IsNotFound(err) {// not found: this means the GroupResource provided was not a// custom resource, so there's no CRD to back up.log.Debugf("No CRD found for GroupResource %s", gr.String())return}kb.backupItem(log, gvr.GroupResource(), itemBackupper, unstructured, gvr)}```
这里也是保障备份资源完整性的一个措施,假如CRD没备份,则CR也会还原失败
还原操作
还原是要把上面备份的demo-backup还原到集群中,先将集群中的test-ns-b的deploy删除掉,同时也将pv中的文件清除
如果要将集群到其他机器上恢复,则需要到OSS中将相关文件下载,bucket中backups目录存放是集群资源的备份文件,文件名就是backup cr的名字;restic中存放的是pv备份的数据,目录均以pvc所在的ns来命名,
如上面例子中备份完毕后资源在minio存放如下
```shell
velero #bucket名|--backups| |--demo-backup| |--velero-backup.json| |--demo-backup.tar.gz| |--demo-backup-volumesnapshotcontents.josn.gz| |--demo-backup-volumesnapshtos.json.gz| |--demo-backup-logs.gz| |--demo-backup-podvolumebackups.json.gz| |--demo-backup-resource-list.json.gz| |--demo-backup-volumesnapshots.json.gz|--restic |--test-ns-b #restic repo的目录结构```
再把这些文件在目标OSS环境中导入,导入完毕还需要将velero-backup.json在目标集群中创建backup cr对象,还原时需要此cr存在。如果有用到pv备份或者volumesnapshot的,也要将相关json执行到目标集群中创建相关cr对象。
相关命令
```
velero restore create --from-backup demo-backupRestore request "demo-backup-20220113092310" submitted successfully.Run `velero restore describe demo-backup-20220113092310` or `velero restore logs demo-backup-20220113092310` for more details.```
执行完毕后,可以通过`velero restore describe demo-backup`查看备份的详情,以及通过`velero restore logs demo-backup`查看备份过程的日志信息
各组件交互流程
与备份的原理一样,执行了velero restore create命令后会创建一个Restore类型的CR,例如下面就是一个restore资源的yaml,当资源一创建,就会触发restorecontroller的逻辑,开始执行恢复操作
```yaml
apiVersion: velero.io/v1kind: Restoremetadata: name: migrate-restore namespace: velerospec: backupName: migrate-backup includedNamespaces: - nginx-example # 按需填写需要恢复的资源类型,nginx-example 命名空间下没有想要排除的资源,所以这里直接写 '*' includedResources: - '*' includeClusterResources: null # 还原时不包含的资源,这里额外排除 StorageClasses 资源类型。 excludedResources: - storageclasses.storage.k8s.io # 使用 labelSelector 选择器选择具有特定 label 的资源,由于此示例中无须再使用 label 选择器筛选,这里先注释。 # labelSelector: # matchLabels: # app: nginx restorePVs: true```
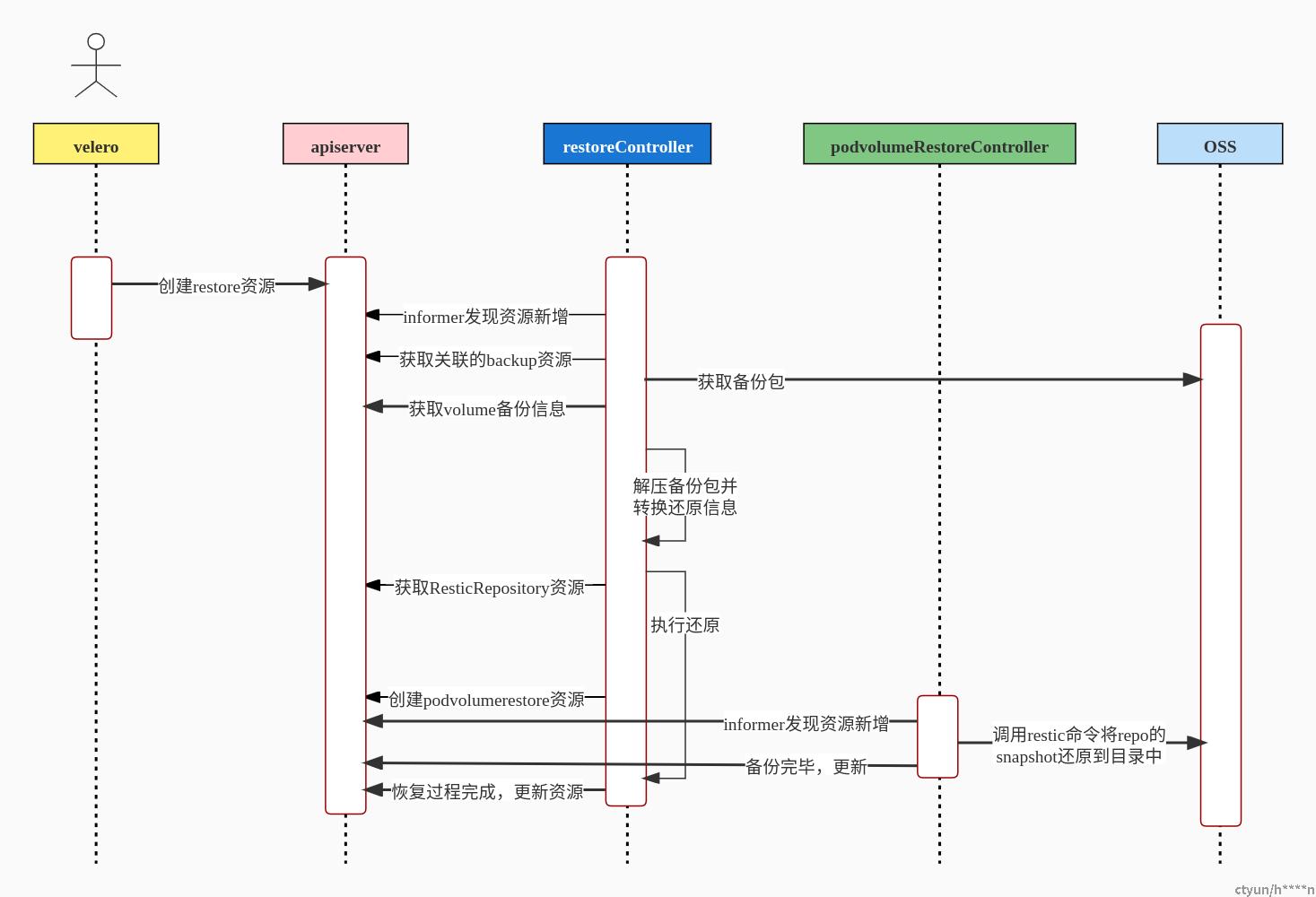
下图则是几个组件的交互流程,其中蓝色方框的两个controller属于deploy/velero工作负载中的,绿色方框的controller属于daemonset/restic工作负载中
### 相关源码分析
restoreController从workqueue中取出新增事件后交由processQueueItem执行还原操作,相关调用及关键方法函数如下
```shell
restoreController.processQueueItem // /pkg/controller/restore_controller.go|--c.processRestore |--c.validateAndComplete | |--c.fetchBackupInfo //获取备份相关信息 |--c.runValidatedRestore |--downloadToTempFile |--c.podVolumeBackupClient.PodVolumeBackups |--info.backupStore.GetBackupVolumeSnapshots |--c.restorer.RestoreWithResolvers // /pkg/restore/restore.go |--restoreCtx.execute() **** |--archive.NewExtractor(ctx.log, ctx.fileSystem).UnzipAndExtractBackup(ctx.backupReader) |--archive.NewParser(ctx.log, ctx.fileSystem).Parse(ctx.restoreDir) |--ctx.getOrderedResourceCollection //第一次先恢复crd |--ctx.processSelectedResource | |--ctx.restoreItem ×××× | |--isCompleted | |--ctx.getResourceClient | |--resourceClient.Create(obj) | |--restorePodVolumeBackups //这个函数仅在回复pod时才有可能调用 | |--ctx.crdAvailable //这个方法在恢复crd时才会被调用 |--ctx.getOrderedResourceCollection //第二次才恢复其他资源 |--ctx.processSelectedResource```
restorePodVolumeBackups ×××× /pkg/restore/restore.go
当controller响应还原的创建事件时,从restore的cr中获取指定的backup名字,就会从OSS中下载backup包,同样也通过podVolumeBackupClient会从apiserver处获取这个备份时创建的PodVolumeBackups,这些都是执行还原前的一些准备工作。当执行到restoreCtx.execute()方法时,即restoreContext的execute方法,他会调用archive.NewExtractor(ctx.log, ctx.fileSystem).UnzipAndExtractBackup把先前下载的还原包解压到一个临时目录中,这个还原包中的文件目录和文件名都会和待还原的资源名相关,调用archive.NewParser(ctx.log, ctx.fileSystem).Parse通过文件目录信息分析出整个还原操作所包含的资源列表。先后调用两次ctx.getOrderedResourceCollection和ctx.processSelectedResource来进行单个资源实例的还原操作,先还原CRD,再还原其他类型的资源。processSelectedResource是包含单个资源实例的还原操作的方法调用,前一个函数getOrderedResourceCollection是为后面的处理方法做类型转换,对待还原资源按ns,label,资源类型进行筛选,筛选通过的会把ns,name,资源文件路径存起来。到ctx.restoreItem还原单项资源时,会用回备份时的套路,通过资源类型构造出dynamicClient,用它来执行资源的create操作,如果遇到pod而且带有pv的则调用restorePodVolumeBackups还原pv的内容,遇到还原crd时需要等待一下,待crd可用才进入下一个还原循环。
restoreCtx.execute()
下面直接看restoreCtx.execute()方法的定义,它是restoreContext类的方法,方法执行的事项大概有以下几项
- - 解压备份包
- - 从解压包的目录中解析还原的资源列表backupResources
- - 开启一个协程异步更新还原的进度到restore的cr里面
- - 将backupResources结构做一个数据转换,顺便做一次对命名空间映射转换和资源筛选;
- - 循环执行单个资源的还原
代码如下,
// /pkg/restore/restore.go
```golang
func (ctx *restoreContext) execute() (Result, Result) {///解压包,解压demo-backup.tar.gzdir, err := archive.NewExtractor(ctx.log, ctx.fileSystem).UnzipAndExtractBackup(ctx.backupReader)ctx.restoreDir = dir///从解压目录中解析出各个会恢复的资源///解析结果按备份时的存储结构 结构是一个两层的key,value结构,第一层的key是资源类型,第二层是命名空间,第三层是资源名,字符串类型的集合backupResources, err := archive.NewParser(ctx.log, ctx.fileSystem).Parse(ctx.restoreDir)///异步更新还原进度go func() {}()///将 map[string]*archive.ResourceItems转化成[]restoreableResource用于后面处理,顺带将资源筛选一下,有排序,筛选转换之用///先处理CRD,然后再处理其他所有资源,但是仍然会再重用再恢复一次crdResourceCollection, processedResources, w, e := ctx.getOrderedResourceCollection(backupResources,//待处理转化的,make([]restoreableResource, 0),//也是用来传结果的sets.NewString(),//已处理已恢复的[]string{"customresourcedefinitions"},//Priorities,下面一个参数为false,只处理这个参数的false, //是否全部都用来处理,)for _, selectedResource := range crdResourceCollection {var w, e Result// Restore this resource//执行恢复在此入去//第一个存储还原的信息,以ns::[]selectedItem 存储,selectedItems(targetNs,name,path)processedItems, w, e = ctx.processSelectedResource(selectedResource,totalItems,processedItems,existingNamespaces,update,)}// Restore everything elseselectedResourceCollection, _, w, e := ctx.getOrderedResourceCollection(backupResources,crdResourceCollection,processedResources,ctx.resourcePriorities, //在/pkg/cmd/server/server.go 处的常量,defaultRestorePrioritiestrue,)for _, selectedResource := range selectedResourceCollection {var w, e Result// Restore this resourceprocessedItems, w, e = ctx.processSelectedResource(selectedResource,totalItems,processedItems,existingNamespaces,update,)warnings.Merge(&w)errs.Merge(&e)}//这里通过一个waitgroup来等待podvolumerestoreController执行完所有volume内容的还原go func() {ctx.log.Info("Waiting for all restic restores to complete")// TODO timeout?ctx.resticWaitGroup.Wait()close(ctx.resticErrs)}()}```
ctx.restoreItem
ctx.processSelectedResource内部会调用ctx.restoreItem方法执行单项资源的还原操作,
```golang
func (ctx *restoreContext) restoreItem(...){///按资源类型筛选if !ctx.resourceIncludesExcludes.ShouldInclude(groupResource.String()) {}///按命名空间筛选if namespace != "" {if !ctx.namespaceIncludesExcludes.ShouldInclude(obj.GetNamespace()) {}}///pod是或者是job是complete等状态就不恢复了complete, err := isCompleted(obj, groupResource)///已还原过的就不还原,顺便也标记当前的已经还原if _, exists := ctx.restoredItems[itemKey]; exists {}ctx.restoredItems[itemKey] = struct{}{}resourceClient, err := ctx.getResourceClient(groupResource, obj, namespace)//对pv资源还原的额外处理,如果有做volumecontentsnapshot的就对其还原if groupResource == kuberesource.PersistentVolumes {}///清空对象中status,metadata除ns,name,annotation,label外其他信息清除if obj, err = resetMetadataAndStatus(obj); err != nil {}//与备份时类似,寻找依赖项,让依赖项优先执行恢复,另外还有skipRestore的看下面注释for _, action := range ctx.getApplicableActions(groupResource, namespace) {executeOutput, err := action.RestoreItemAction.Execute(&velero.RestoreItemActionExecuteInput{...}//只有apiresource和grpcClient两种会skipif executeOutput.SkipRestore {return warnings, errs}for _, additionalItem := range executeOutput.AdditionalItems {w, e := ctx.restoreItem(additionalObj, additionalItem.GroupResource, additionalItemNamespace)}}//对pvc资源的特殊处理if groupResource == kuberesource.PersistentVolumeClaims {if pvc.Spec.VolumeName != "" {//重置绑定,将pv与pvc解绑,让pv回归可用,能继续绑定pv,实质就是清除spec.claimRef字段内容obj = resetVolumeBindingInfo(obj)}}///在此处执行创建恢复,会出现已存在的问题,由此可见velero的还原操作不会覆盖原有的资源createdObj, restoreErr := resourceClient.Create(obj)if isAlreadyExistsError(ctx, obj, restoreErr) {return warnings, errs}///在此处执行pv内容恢复if groupResource == kuberesource.Pods {if len(restic.GetVolumeBackupsForPod(ctx.podVolumeBackups, pod, originalNamespace)) > 0 {restorePodVolumeBackups(ctx, createdObj, originalNamespace)}}//遇到恢复crd要等待crd就绪,即能通过kubectl get crd 能get出该crdif groupResource == kuberesource.CustomResourceDefinitions {available, err := ctx.crdAvailable(name, resourceClient)}}```
restorer.RestorePodVolumes
restorePodVolumeBackups里面会调用Restorer接口的RestorePodVolumes方法执行pv内容恢复,实现类是restorer,代码位于/pkg/restic/restorer.go
```golang
func (r *restorer) RestorePodVolumes(data RestoreData) []error {repo, err := r.repoEnsurer.EnsureRepo(r.ctx, data.Restore.Namespace, data.SourceNamespace, data.BackupLocation)for _, podVolume := range data.Pod.Spec.Volumes {podVolumes[podVolume.Name] = podVolume}for volume, snapshot := range volumesToRestore {volumeRestore := newPodVolumeRestore(data.Restore, data.Pod, data.BackupLocation, volume, snapshot, repo.Spec.ResticIdentifier, pvc)if err := errorOnly(r.repoManager.veleroClient.VeleroV1().PodVolumeRestores(volumeRestore.Namespace).Create(context.TODO(), volumeRestore, metav1.CreateOptions{})); err != nil {}}}```
这里调用的repoEnsurer.EnsureRepo方法也跟备份时的一样,检查对象存储中的restic repo是否存在,不存在会去重建,但是在还原阶段重建已经没意义了,调用restic命令执行还原操作的同样不在这个contrtoller中执行,而是创建了PodVolumeRestore资源,交给PodVolumeRestore controller去执行
小结
从K8S功能扩展来看,velero定义如此多的CRD,一方面通过以K8S的方式实现了请求发起与响应的操作:定义一个CRD就会在apiserver中开辟了一套资源都API,请求时所带的参数信息均可以通过CRD中的spec对象进行存储传输;CR对应的controller通过list&watch机制来执行功能逻辑,响应请求。另一方面CR能记录controller处理过程中的一些中间数据,记录状态以及处理结果。正是这两个方面,充分发挥了事件订阅模式优势,让整个过程都在异步模式下进行。
